 The Answer Gang
The Answer Gang

By Jim Dennis, Karl-Heinz Herrmann, Breen, Chris, and... (meet the Gang) ... the Editors of Linux Gazette... and You!

...making Linux just a little more fun!
 Re: [SEAPY] Pie-thon
Re: [SEAPY] Pie-thonDan Sugalski (Parrot) gets a pie in the face by Guido van Rossum (Python). Dan lost a bet that Python would run faster on Parrot (Perl 6's virtual machine) than the standard C version.
http://www.oreillynet.com/pub/a/oscon2004/friday/index.html
-- -Mike Orr (aka. Sluggo)
FYI, The reason Dan lost was because he failed to complete 3 of the 7 tests. On the 4 he did complete, Parrot beat Python on 3 of them. Of those 3, Dan said Parrot was 2-3 times faster.
Cheers, Brian
Say please? Thank you...What is the computer language that makes you say please? I used to know this. I might recognize it if I saw the name. A fellow LUG member suggested I look at http://sk.nvg.org/lang but nothing seemed obvious.
Someone out there knows, I hope.
Thank you!
MetaThemeIn my article "A guide to Windows technologies for Linux users" in issue 104 (http://linuxgazette.net/104/oregan2.html) I mentioned gtk-qt, which allows Gtk apps to use Qt themes. MetaTheme (http://metatheme.advel.cz) is a project to create a theme engine which is independant of the various toolkits. It currently supports Gtk and Qt, and work is under way to support Firefox. (http://metatheme.advel.cz)
Moaning goat meterHi.
Linux Gazette is always a pleasure to read,thank you for
that experience
![]()
You're welcome, and thank you for taking the time to write to us. It's always nice to hear that people appreciate the work we do.-- Thomas
Glad you're enjoying it! -- Ben
In article "Which window manager" in #105 of LG MGM was mentioned.It looked interesting enough,so I looked it up.
I found it on http://www.linuxmafia.com/mgm
My mistake was that I started reading the FAQ
while drinking coffee...
![]()
Classic case of C|N>K
Whups. We should probably warn people about that. Me, I cautiously set aside any drinks and dangerous objects (err, well - except my mind) before opening any mail prefixed with [TAG]; I know this bunch. -- Ben
My nose is much better now,thank you...
Let me tell ya, be glad you weren't eating raisins or peanuts. Those can really hurt your nasal passages, and leave dents in your walls and furniture! -- Ben
It is amusing, isn't it.
You are really serious about this 'Making Linux a little more fun' thing,aren't you? Thank God for that.
Pedja
We have to be, Predrag, otherwise we'd be YAMP (Yet Another Man Page).
[grin] That's the LG to a tee. 'Fun' isn't our middle name - it would involve all sorts of boring paperwork, people would ask pointed questions about changes in marriage status, and applying to courts in various countries would be a real hassle - but we do enjoy ourselves, usually.
Thanks for writing! -- Ben
[Rick Moen] You're very welcome, Predrag. Furthermore, I'll take this opportunity to declare you an official Linux Gazette Evil Genius. We'll be sending you your white Persian cat and monocle via separate attachment. Go forth[1] and conquer.
[1] Or FORTH, perhaps.
Thank you,I'm honoured
![]() .
Can I put that on a t-shirt?
.
Can I put that on a t-shirt?
Pedja
Ben's Boat...Wherein "The Answer Gang" express our general pleasure that the Editor In Chief's home survived the wake of the hurricanes pouring through Florida lately.
This is really Not Linux, but we send good wishes to any readers out there cleaning up after Mother Nature's mess. -- Heather
Ben,
I didn't catch from your earlier email where your anchorage was, did the ~ Charley course change spare your boat?
-- Brian Bilbrey
It made it worse, actually - Charlie's eye passed right through St. Augustine, from what I'm told - but my anchors held (I had a friend put out a third one; I normally ride to two anchors, but have eight on board.)
The winds were supposedly in the 70+ knot range (Category 1 hurricane) with 6' seas in the Matanzas river, where I'm actually anchored. The docks at the nearby city marina took a real pasting, but everything and everybody seems to be OK.
WHEW, big-time. When Charlie got up to 145mph, and shifted course to pass dead over St. Augustine, I was not a happy camper.
[Breen Mullins] Whew! indeed. Glad to hear all's okay -- I've been worried about you.
[John Karns] We're glad to hear that the boat is still in one piece. Our thoughts are with those who weren't quite so fortunate. At least it sounds like it went a little better than Andrew in 1992.
Yeah. Nineteen dead so far (no final count yet), lots of people hurt, at least $11B worth of property damage (again, not final figure); 300,000 people still without electricity; it was a rough one.
Quote from CNN:
|
............... Despite the damage, Florida Lt. Gov. Toni Jennings said that her state was better prepared for Charley's onslaught than it had been in 1992, when Hurricane Andrew, a Category 5 storm with winds topping 155 mph, crushed the southern tip of the state from east to west. "Where we are today is about where we were two weeks after Andrew," Jennings said. ............... |
At this point you can hit up Google for all the gory details and then some; in addition to early storms it's been a heavy season so far too. -- Heather
My boat took some damage... from do-gooders without a clue - none from the hurricane. Nothing major; I spent last night on a tilt (50 degrees or so at 4 a.m. - low tide) and had to get her off the shoal this morning, then spent most of today grappling for my anchors (one line chafed through, and the idiots^Whelpful folks who moved her managed to lose a 45-lb. anchor and 300' of chain over the side.) Haven't found them yet - but hooked onto a big Fisherman-type anchor that somebody else lost here during the last few years, so that's what I'll be using temporarily.
All in all, normal life in the hurricane zone.
 [LG 105] 2c Tips #5: Open X-change
[LG 105] 2c Tips #5: Open X-changeSerendipity - Linux Today are carrying a story about Open-Xchange Server, the engine of SuSE's Openexchange Server, today - Novell have convinced the owners to GPL it. Since it's Java based, it'll be accompanied by their Java Application Server too.
It'll be available to download at http://www.Open-Xchange.org and http://www.openexchange.com at the end of the month.
They consider it working but the feature set isn't frozen. The version name is "Janus" and they've numbered it 0.7.0 since they hope to cram in a few more features before 1.0.0. -- Heather
Converting a VCD file to MP3Hello Gang, here is my tips..
There is an easy way to convert VCD (Video CD) file into MP3. What you need are just MPlayer and Lame. MPlayer is used to convert the VCD file to WAV by using the PCM audio output, and then you can convert the WAV file to MP3 by using Lame.
First, you have to convert it to WAV by using the command:
$ mplayer -ao pcm /path/to/vcd/avseq01.dat
MPlayer will play the VCD file like usual, but with no sound. Just wait until it finished. You'll get a file 'audiodump.wav' that you can convert to MP3 by using the command:
$ lame -h audiodump.wav newfile.mp3
Switch -h is used to get high quality MP3 file, but bigger filesize.
NetkitI just wanted to let you know about a nice project carried out at the Third University of Rome, namely "Netkit".
In a few words, Netkit lets you build a virtual network in order to do all the tests you would like to carry out, with special focus on learning how to use routing protocols and stuff like that. This virtual network is realised launching separate instances of Linux in different xterms - each being a full-fledged Linux box! There are methods to connect those Linux boxes via virtual Ethernets and also to communicate with them from the main host.
Netkit owes 90% of the stuff to UML, aka User Mode Linux, which is a project to let the user launch a Linux Box inside Linux. But I think that they had really an hard time to set up all the environment and create something really usable for these network experiences. Moreover, their website includes a lot of lectures about networking experiences using Netkit. To be honest, when I prepared my exams I found a couple of broken examples but everyone should be able to fix it or to... jump to the next example.
Given the fact that you're probably going to acquire tcpdump logs of the experiences if you decide to give Netkit a try, I also suggest to download and install Ethereal, which is a nice GUI to explore tcpdump sniffs.
You can find Netkit at http://www.netkit.org, more on UML at http://user-mode-linux.sourceforge.net. Ethereal is, of course, at http://www.ethereal.com.
Bye, Flavio.
That's not a bug, that's a feature
I found an entry on google regarding a possible bug in bash. I have a script
that does the following.
#!/bin/sh
formatmonth=`date "+%m"` month="$(($formatmonth * 1))" formatday=`date "+%e"` day="$(($formatday - 1))"
when this is run if the current month is 08 it gives me this error. value too great for base (error token is "08")
have you found a fix for this? or know a workaround? thanks for any help!
Gary Luker: MCSE, MCSA, MCP, Linux+, SAIR/GNU Linux Pro
The arithmetic functions in bash (and C and some other programming languages) treat numeric literals with a leading zero as if they are in octal (base eight). Octal digits range from 0 to 7; therefore 08 is not a valid octal number.
Using GNU date you can use formatmonth=`date "+%-m"` to supress the zero padding of the month. That should take care of the problem. According the date man page the %e value is already "blank padded" so it will never be mis-interpreted as an octal number.
-- JimD
answer gang without the spamAs our readers may recall, The Answer Gang ([email protected]) is really a mailing list where the regular subscribers get all queries and linuxy bits sent through, but it accepts questions and comments from anybody in the world. Of course this means spammers throughout the world email us too... -- Heather
Hello gang,
Here is a lurker's 2c worth on weeding out list spam. With a default set of rules, Spamassassin does a reasonable job of cleaning up my inbox. Recently though an increasing amount of spam sent to the TAG list has been getting past spamassassin. On a mailing list I am willing (more so than for personal mail) to accept the occasional false positive. So I wanted to try running all TAG emails through a stricter set of spam catching rules. Here is the configuration I have tried for the last week or so and found the spam:ham ratio greatly reduced.
A seperate spamassassin config file is used for TAG. From .procmailrc:
:0fw: spamassassin.lock * ^Subject:.*\[TAG\] | spamassassin -p ~/.spamassassin-tag/user_prefs :0Efw: spamassassin.lock | spamassassin
And the highlights from ~/.spamassassin-tag/user_prefs:
required_hits 4
(this is 5 by default)
score HTML_MESSAGE 3.0 score RCVD_IN_BL_SPAMCOP_NET 3.0 score RCVD_IN_SORBS 1.0 score BIZ_TLD 2.5
(arbitrarily cranking up the score for rules that seem to match the incoming spam)
This setup is working well for me so far (no false positives yet, and only a single junk mail getting through).
The answer gang mailing list is always a good read, and I was glad to find you guys hanging out at linuxgazette.net after being quite surprised at the new structure of the .com site.
'til later TAGsters
--andrew
We are looking into ways of solving it more directly. There'll hopefully be no need for this elaborateness when (
The same problem exists for any decently worldwide mailing list, maybe the -users list from your favorite distribution or major app, so it's still a great Tip! Just beware setting your filtering a little too high, as Jimmy discovers... -- Heather
[Jimmy O'Regan] Heh. I only noticed a couple of days ago that my ISP is running SpamAssassin on my mail before it gets to me. I was wondering why everyone was complaining about the level of spam on the list
More on Linux for low end systemsJust thought I'd point out a piece I wrote a some time ago on getting good performance out of older hardware: http://users.netwit.net.au/~pursang/lofat.html
John
ps. Nice bike Ben! Hope you have as much fun on it as I do on my old
GSXR750
![]()
And Ben's going to be getting a first person taste of playing with low-end systems soon. Since his laptop has been been in and out of the silicon-lifeforms hospital, I'll be sending him my eldest still-operational laptop for his ongoing use as a proper spare. Thanks, John! -- Heather
Is your sync Hot or Not?Dear LinuxGazette
I am the lucky owner of a Palm m515 handheld. One of my frustrations in the past has been that under Linux, I need to establish a PPP connection to synchronise my palm with AvantGo web pages, whilst my preference is to use the normal HotSync button to synchronise the rest of the palm. A frustration, since I wanted the PPP connecttion to establish automatically without my having to do anything, but this conflicts with JPilot Hotsync.
I thought to share the following little bash script with you, which detects in which mode the Palm is attempting to communicate, and establishes a PPP link if that is what the Palm is attempting to do. Otherwise it waits until the Hotsync operation is over and repeats.
I hope that someone finds this useful. By the way, if Palm owners are experiencing trouble with USB drivers in the later (2.6.7+) kernels, I suggest they try 2.6.5. The USB support in that version is excellent.
Paul
See attached paul.palm_smartlink.bash.txt
That's all, folks
|
...making Linux just a little more fun! |
The Answer Gang
By Jim Dennis, Karl-Heinz Herrmann, Breen, Chris, and... (meet the Gang) ... the Editors of Linux Gazette... and You! |
We have guidelines for asking and answering questions. Linux questions only, please.
We make no guarantees about answers, but you can be anonymous on request.
See also: The Answer Gang's
Knowledge Base
and the LG
Search Engine
 Greetings from Heather Stern
Greetings from Heather SternGreetings, everyone, and welcome once more to the world of The Answer Gang. It's sunny September where I'm sittign but for some places the storms are rolling in. (See our Mailbag for soggy details.)
Meanwhile, it's getting toward Autumn. The blustering winds are starting to tug at the leaves, the blustering television sings of back to school and fall fashions. What have these to do with the world of techies? Not much...
Well, hold on a second there. Actually, the start of new academic seasons give the open source world a new batch of bored students and busy computer science departments with fat links to work on new projects. Techie bits have come up in the fashion world - depending on just how far away from the techie world you are, fashion might have been what dragged Linux into your view, as the Burlington Coat Factory sometime ago (about 5 years now) held a certain large hardware vendor over a barrel by taking them up on their system preload offer, but wanting the "ordinary consumer" class of systems en masse rather than a few rackmount servers. Since then, Burlington expanded their Linux use company wide and appear to be pretty darn happy with it.
Let me take a woman's intuition on a little shopping trip, then, and see where else Linux has come into fashion... I'm not talking T-shirts, mind you. I can get those at trade shows. I can buy them at ThinkGeek. I'm not talking about silly tidbits like a tie with 47 pictures of Tux on it. The ability to wear bumper sticker and /usr/share/games/fortunes sorts of wit is not fashion. I'm talking about the world where some crazy designers feel compelled to reinvent crayola colors every 6 months or so and force beautiful slinky babes (of both genders) to walk up and down a long stage wearing... err, well, sometimes it doesn't look silly, but often it does.
What doesn't help is how hard this can be to shop for. Search engines are with "in this fashion..." and "accessories" will get you peripherals. I really had to pull out the stops for this. You won't find it on freshmeat either (though I did find yet another lightweight wm called WMI).
You want jewelry, you have to look for jewelry - amd apparently it helps if you spell this the long way. Linux Jewellery has quite the debian collection, and some BSD stuff too.
You ladies who want to show off your fondness for Red Hat instead, consider these. Sorry it's not a fedora: http://www.thesilvermonkey.com/redhatsocietythemefashionjewelry.html
OTOH, sometimes a hat is just a hat. As early as 3 years ago some people
were seeking geek chic that didn't include looking like "the techie" from
several hundred feet away. THis article from that time relates, and I'm
pleased to say many of its links are ever still good. Dress shirts wired
for techie bits? My goodness:
http://www.geek.com/pdageek/features/chic/index.htm
That was 2001. In 2002, CNN wondered if wearable computing would hit the
fall fashion highlights with an MP3 jacket. "We're just demonstrating the
technology." they cried, it's not like we want money for this.
Working with partners, etc. Get the giggles yourself while reding this:
http://news.com.com/2008-1082-941578.html
Will wonders not cease. It was shown off, among other curious inncations of the fashion world, at a fashion conference earlier this year. Infineon really has partnered with Rosner for a MP3 denim jacket (well it looks denim; I could be wrong) and O'Neill for a MP3 enabled snowboarding jacket -- now you "Extreme Linux" fans have something to wear.
No idea what OS the players use, sorry - fashion doesn't care about that. Is the open source concept affecting fashion more directly? Maybe not. But someone's thinking about it.
Amazing. Maybe we're getting somewhere. Until next month, folks. I and my red straw hat are off shopping.
Generic installer locationsFrom Jay R. Ashworth
Answered By: Thomas Adam
I have a project, sitting here on the desk in front of me, for a menu program that I need to decide on an implementation language for.
The target environments are SCO OS5 and quite some different number of Linux distros; the possible languages are Python and Perl.
While I don't especially care if the buyer can see the code, what I do care about is not putting the installer into either dependency hell or conflict hell, while still having the pieces I need to do the work.
This seems like a reasonably common problem; any suggestions on how to approach it?
[Thomas] Graphical, console or both?
![]() [Jay]
I suppose that was pertinent, yes; it's a menu program; text, but full
screen.
[Jay]
I suppose that was pertinent, yes; it's a menu program; text, but full
screen.
![]() [Jay]
I apologize; I thought I'd made my specific point clear on the first
pass:
[Jay]
I apologize; I thought I'd made my specific point clear on the first
pass:
This program, when done, sold and shipped, needs to be able to install
and run reliably on all target platforms without conflicting with, or,
really, depending on, whatever language runtimes might or might not
already be there. I don't object to depending on what's there, or
brilliant installers, or any of that stuff, but on SCO, I'm likely to
have an ancient Perl and no Python at all...
![]() [Jay]
and on Linux, you never know what will be there -- or what you might
break if you have library/module conflicts.
[Jay]
and on Linux, you never know what will be there -- or what you might
break if you have library/module conflicts.
![]() [Jay]
So, again, going back to Fred Brooks' System Program Product concept
(you know, the thing that takes 9 times as long as a simple hack?
[Jay]
So, again, going back to Fred Brooks' System Program Product concept
(you know, the thing that takes 9 times as long as a simple hack?
![]() ,
what is the best approach to this?
,
what is the best approach to this?
[1] In theory, great. In practice, err.....
Skip various snide comments -- Thomas Adam
![]() [Jay]
I propose to deploy as a commercial product a program written in a
language which expects an installed interpreter, with a system-wide
directory of modules.
[Jay]
I propose to deploy as a commercial product a program written in a
language which expects an installed interpreter, with a system-wide
directory of modules.
If that infrastructure exists, I don't object to using it (assuming that everything's the right version). But if it's not there, it's not my place to install it -- the client isn't buying a-complete-perl-install, and I don't want to be responsible for that, anyway.
![]() [Jay]
I don't have 6 years and 40 machines.
[Jay]
I don't have 6 years and 40 machines.
![]() [Jay]
Because that doesn't take into account what might have already been
done adminstratively to the machine.
[Jay]
Because that doesn't take into account what might have already been
done adminstratively to the machine.
If the administrator has been messing around with standard locations, then he/she should have enough synapses left to know what to do. As a default though, you could always install in: /usr/local/ and export LD_LIBRARY_PATH as necessary, and let the administrator know that if they know of a better place to put them, to ensure that it is done.
Mail forwardingFrom Ben Okopnik
Answered By: Jay R. Ashworth, Breen Mullins, Rick Moen, Jimmy O'Regan, Thomas Adam
Damn, I'm starting to foam at the mouth and twitch uncontrollably. This Mutt + SMTP-via-SSH-tunnel thing's got me going batty...
Mutt doesn't want to know anything about ports or hosts; instead, it invokes Sendmail directly. The SSH tunnel is trivial to set up, but I can't use it - despite spending the entire evening Googling for a possible answer. I really don't want to switch to another email client, either. Do any of you folks have a suggestion?
![]() Local-injection program - define, please? I've got it all working now
(with the exception of a warning message from fetchmail that I'm too
busy to chase down ATM), but I'm still curious about other ways to
handle it.
Local-injection program - define, please? I've got it all working now
(with the exception of a warning message from fetchmail that I'm too
busy to chase down ATM), but I'm still curious about other ways to
handle it.
ssh remotehost /usr/bin/sendmail
and let sshd remotely run it with the piped stdin as the message source. /usr/bin/sendmail is still almost always a link to something that can deal with that, even these days, no?
Local injection is a phrase I generalized from the wmail and postfix doco...
![]() I think I may have it.
I think I may have it.
![]() ))
))
Finally found the one page on the Net that simply explains exactly the process I needed:
http://revjim.net/comments/3734
You could try using Msmtp: http://msmtp.sourceforge.net but that probably has issues of its own.
![]() [Ben]
It does. I read about a guy who was using esmtp and msmtp, and he got
them working with this kind of thing, but I don't really want to drop
Exim, either; it's proven itself over time.
[Ben]
It does. I read about a guy who was using esmtp and msmtp, and he got
them working with this kind of thing, but I don't really want to drop
Exim, either; it's proven itself over time.
I've only just started using Mutt myself. What I think you're going to have to do is get an MSA on your box -- something like http://msmtp.sourceforge.net "msmtp is an SMTP client that can be used as an "SMTP plugin" for Mutt and probably other MUAs (mail user agents). It forwards mails to an SMTP server (for example at a free mail provider) which does the delivery. To use this program, create a configuration file with your mail account(s) and tell your MUA to call msmtp instead of /usr/sbin/sendmail."
![]() Actually, that's one of the things I wanted to avoid doing - much as I
like null-mailers. Picture this scenario: I'm at a Net cafe that's got
SSH blocked but 25 open (it's happened). Whups! No outgoing mail for me,
then, unless I resort to webmail (Nextel does not provide SMTP or POP -
connectivity only.)
Actually, that's one of the things I wanted to avoid doing - much as I
like null-mailers. Picture this scenario: I'm at a Net cafe that's got
SSH blocked but 25 open (it's happened). Whups! No outgoing mail for me,
then, unless I resort to webmail (Nextel does not provide SMTP or POP -
connectivity only.)
In essence, I want to retain full SMTP capability but be able to switch between doing that and forwarding 25 (and/or 995, if necessary.) This week's been sorta amusing in that regard: Earthlink blocks 25 but leaves 995 open; Sun's firewall is the opposite. Setting up Exim as I'd mentioned, plus adding another "poll" section to my ~/.fetchmailrc, and running
su -c 'sh [email protected] -L 2525:linuxgazette.net:25 -L 995:linuxgazette.net:995'
takes care of both - and should work fine with my cell setup when I get back home. The only thing I get to pay for is the additional SSH overhead for all my mail transactions, but it's not a big deal. The only thing I don't get is why I have to do the "su" bit; the first forward doesn't require it, but adding 995 - which is obviously not a low port - makes the connection fail.
Parent and ChildFrom tag
Answered By: Jim Dennis, Heather Stern
Once again, I'm teaching a class on shell and Linux basics to a group and after many years of doing it I'm really getting tired of drawing the same old pictures on the whiteboard or flipsheets.
What we need is a nice drawing of this, something animated. Maybe you could whip something up in Flash, and tuck yet another feather in the webmastery cap?
Now tossing out all the things that are apps written in Flash, libraries to make it work at all, and front-ends for the Flash viewer we have... ahhh... Generators won't do, I want this to have our images in it. Dancing text alone is worse than the old MARQUEE and BLINK tags. Oh, there we go. Some alpha quality sourceforge projects to convert various formats into flash.
Package system search time. bzzzt Hmm, guess I'll have to fetch the sources and debug why they don't just './configure; make; make install' in my copious spare time.
/me buys Wilbur the GIMP some coffee, munches on a few doughnuts, and jumps merrily back into the world of animated GIFs.
![]() Ok. So here's what I envision, About 12 slides, on a roughly square
picture, as follows.
Ok. So here's what I envision, About 12 slides, on a roughly square
picture, as follows.
1) initial process. A rectangle somewhat toward the mid-upper left, saying "process"
![]() 2) system call.
2) system call.
The giant word fork() appears over the process. Transition: process memory map.
![]() 3) fork results.
3) fork results.
Show the child - a similar sized process - seperating from the parent and the two being labelled, parent and child.
![]() 4) zoom!
4) zoom!
Make the parent smaller and give the child most of the right hand side of the picture.
![]() 5) details.
5) details.
The parent just says "parent", the child shows a memory map breakdown. From bottom to top... environment, text (code), BSS, and sharing a space where each grows toward center - heap and stack.
6) system call. The giant word exec() floats up...
![]() 7) result point 1.
7) result point 1.
The process space is cleared entirely, except the environment. This is, of course, the space which bash' "export" command moves variables into so they will be inherited, just to bring up one clear example.
![]() result point 2.
result point 2.
The child now has its own fresh copies of the other parts, but highlight the inherited environment.
![]() 9) zoom back out.
Bring the parent and child back to their previous sizes.
9) zoom back out.
Bring the parent and child back to their previous sizes.
10) meanwhile...
The parent exhibits the wait() system call. Now this could be blocking, or not blocking, I can spend quite a while on this part, but let's just make the drawing assume a blocking wait.
11) which waits until... The child does an exit() call.
12) the child dies. Highlight the parent, which unblocks as it catches a SIGCHLD signal.
![]() That's not really right; init generates SIGCHLD after cleaning up most of
the mess. And the dead child shouldn't hang around. We'll need to show
the remaining process table, too. Make the kernel float in from offside
so we can see that, perhaps.
That's not really right; init generates SIGCHLD after cleaning up most of
the mess. And the dead child shouldn't hang around. We'll need to show
the remaining process table, too. Make the kernel float in from offside
so we can see that, perhaps.
Here's where the doodle breaks down, so time to re-doodle it, using the facts. The exit leaves a return code. But as you and I know, return codes aren't stored in the "dead body" of the child process. It only exists as a zombie - an entry in the process table, which is the only thing left of it after init sweeps away the main process. The process table itself is in the kernel somewhere. So I'm going to need to plot where to sneak in a kernel page. (I imagine a bag of popcorn...
![]() Yes, that will work much better. Let's get the animation between slides
in, then fix up the last part and it's good to go. I found you a nice
gif to flash translator, which we can try on the resulting file for
grins.
Yes, that will work much better. Let's get the animation between slides
in, then fix up the last part and it's good to go. I found you a nice
gif to flash translator, which we can try on the resulting file for
grins.
I don't suppose GIMP can output flash yet?
I'm sure there are more aspects of the process creation and lifecycle that can be drawn. I'm juggling a few things, but I'll post the drawing in progress...
![]() Just stuff them in SysadMoin on the page TaosLinuxTraining, at least
at the moment. When I'm happier with the parts you can split them up
into several images - one per stopping point in our final form. We'll
split the Process Model commentary onto a new page, and the world can
have some fun with it.
Just stuff them in SysadMoin on the page TaosLinuxTraining, at least
at the moment. When I'm happier with the parts you can split them up
into several images - one per stopping point in our final form. We'll
split the Process Model commentary onto a new page, and the world can
have some fun with it.
Sysadmoin is our house wiki, used for our system administration natter. (http://www.starshine.org/sysadmoin) It's based on moinmoin, and I'm pleased to say that our dark theme is actually part of the upstream sources. Very pleased, after all the trouble I went to in order to http://www.starshine.org/sysadmoin/MakeMoinMoinDark in older revisions. The moin people are very active in development, so for this project at least, it's worth popping into #moin on freenode. Helps to show up on European hours though.
Maybe I'll even post the xcf file and let people enjoy paging around in it. I realize xcf isn't readable by anythign but gimp, but that's where the real animation lies, in the seperated frames.
For you dithering vidiots out there, frames of about 50 milliseconds distances seem to be fairly smooth going, slower's a little more obvious but somewhere between that and 140 ms are good for skidding to a halt. Anything slower is painful. Your eyeballs may vary, but recall that american TV is about 24 or 28 frames a second, and more is better. 50ms is a mere 20 frames per. I just don't want my file to get too big.
For gimp folk specifically, adding (50ms)(replace) to the end of the name of your frame gives fine grain control on the animation. You could use (combine) instead when you need it. And gimp does let you resize layers down again (it's tricky) which might save space in the result. The last tip is that (50 ms) with a space doesn't do. Leave the space out. (50ms) (replace) spaced does work though.
Share and enjoy...
Upgrading KDEFrom Tom Brown
Answered By: Thomas Adam, Heather Stern
OK, I'm about at my wit's end here (doesn't take much, I know). I'm currently running KDE 3.1, and want to upgrade it. I've yet to figure out how, even using binary RPM's from Suse (my distro). No matter where I start, I'm getting lots and lots of dependency errors. I've looked on the KDE web site for some sort of help or tutorial, but haven't found anything useful.
![]() First, is there a shell script that will automate the
process (assuming I've downloaded the huge pile of individual KDE
packages), or is there a way to force Suse's YOU to upgrade from KDE 3.1
to either 3.2 or 3.3? Failing that, is there documentation that takes me
step by step through the process without assuming I'm a kernel
programmer or something?
First, is there a shell script that will automate the
process (assuming I've downloaded the huge pile of individual KDE
packages), or is there a way to force Suse's YOU to upgrade from KDE 3.1
to either 3.2 or 3.3? Failing that, is there documentation that takes me
step by step through the process without assuming I'm a kernel
programmer or something?
![]() The best I've found is instructions on installing KDE packages from
source, but nothing I've found tells me in what order the packages go.
I've tried starting with the "base" RPM, but that mustn't be it, since I
get so many dependency errors.
The best I've found is instructions on installing KDE packages from
source, but nothing I've found tells me in what order the packages go.
I've tried starting with the "base" RPM, but that mustn't be it, since I
get so many dependency errors.
#
# KDE 3.2 packages for SuSE distributions
#
Disclaimer:
These packages have NOT been tested at all and SuSE do NOT recommend to
upgrade to these. However we build these packages for convenience, but
it is your risc to use them ;)
You should not update, if you want to have a stable system and expect
to get security updates for your installation.
To install these packages via command line you need to
* rpm -e kdebase3-SuSE kdenetwork3-mail
(kdebase3-SuSE has not yet been ported to KDE 3.2 and plain rpm
can not handle the move from kmail to kdepim3 package correct).
* rpm -Uvh taglib*rpm
* install flac and gnokii from your CD/DVD
* rpm -Fvh *.rpm
An alternative way would be to use the yast_source from ftp.suse.com KDE
update packages.
Known issues:
* Qt 3.3.0 final has not been released yet, we expect it next week
and it will be avaible on ftp.suse.com.
The qt packages in these directories contain a late snapshot
(Qt 3.2 would need many patches, so we decided to go the 3.3 way)
* Several issues with updating old configurations, these will be
addressed with SuSE 9.1. However SuSE 9.1 will not fix these, when
you have already updated to KDE 3.2. So you might backup your
~/.kde directory first.
* kdebindings packages are missing atm, they need further fixes and
will appear on ftp.suse.com later
The effort to stray off the beaten path is paid off in getting the nice new features, fixes, and i18n updates far ahead of your neighbors. With care during setup you can also make it easier to update yourself from the project source trees directly with less fuss. The scuffs and scratches will heal, and you'll learn to hang-glide with open source wings...
Midnight commander (mc) with its ability to pop open rpm files and let you look at the post-install scripts, may be invaluable to helping you play safely on the bleeding edge too; look at what merges are made into menu systems and system-config directories. What you learn from that may help you with merging other off-brand packages from their true sources.
By Tom Brown
[This article is a follow-up to this TAG thread]
There's an old joke about how a burgler makes a cake. The recipe begins "To bake a cake, first steal two eggs". Of course, if you really don't want to do any baking in the first place, and all you really wanted was a simple pre-packaged cupcake, all this recipe stuff (not to mention hunting down the different ingredients needed) may be more trouble than it's worth. Occasionally, that's been my experience migrating from Windows to Linux. One such occasion has been my recent attempt to upgrade KDE from version 3.1 to 3.3. Only in this case, the instructions were: "To install KDE, first find one recipe".
Now, Windows users are a picky bunch. We expect to double-click on an icon, usually "setup.exe", and everything works automagically. The logic of what to uninstall, what to install, and what questions need to be asked of the person doing the installation, are all built into the process. With KDE, there's no such thing. Apparently, nobody feels it's needed, despite the multitude of different packages which must be installed (and uninstalled) in a particular order. But some sort of automation is desperately needed here. There is no excuse, in my opinion, for the installation of software to be difficult. Now, a lot of people who read LG will wonder what the fuss is about. This is Linux, after all, and you need to learn how to do all this. At the risk of being called a troll, I say that's just the wrong attitude to have. Installation (of device drivers as well as software) is an area in which Linux still has a very long way to go. I don't want to bake the cupcake, blast it, I just want to eat it!
First, my thanks go to Faber Fedor for pointing me in the right direction in my KDE upgrade. There are days when my googling skills fail me miserably, and I appreciate Faber's help. I still didn't have an easy time doing the upgrade, and haven't gotten everything working (a few tiny annoyances still remain), but on the whole I managed it.
Technical details: I'm running SuSe 9.0, with the original KDE 3.1 installation that came with the distro. I upgraded using the binary RPM files from the SuSe website. That website still claims the files are for KDE version 3.2, when in fact most of them are now for version 3.3 (dated August 19, 2004). Unfortunately, the KDevelop RPM there has not been updated, and won't install into KDE 3.3. That's one I'll tackle later, since for the moment, I don't need it. Using RPM files built specifically for your distro is the easiest way to do the upgrade, but if you can't find any, then you'll either have to build from source or wait for the right RPMs to become available. Notice that I'm installing the KDE development packages. Even if you don't intend to do any software development in KDE, some of this might be needed if you install software from the sourcecode.
Before beginning, you should backup your system. If you're using drag-and-drop to do this, remember that the ".kde" directory in each user's home directory is normally hidden, so make sure you're showing hidden files in Konqueror before doing so.
Now, because I'm a Windows Defector using SuSe (and therefore, Yast2), I did the entire installation from inside KDE, not the command line. I had to do one extra step at the end to compensate for this rash and risky approach, but the benefit was double-clicking on the RPM file to perform the installation, instead of all that command-line nonsense (sorry, it's a Windows Thing).
Now it's only fair to tell you that a lot of folks recommend a different procedure for installing KDE. First, boot to the Linux command line instead of the GUI. In SuSe's Yast2, click the "System" icon, then the "Runlevel Editor" icon. Select the "Expert Mode" radio button in the subsequent dialog box, then change the drop-down list from "5: Full multiuser with network and xdm" (or what is called "runlevel 5") to "3: Full multiuser with network" (or what is called "runlevel 3"). If you're not using SuSe, then you'll have to edit the bootup runlevel setting in the file "/etc/inittab". Either way, the next time you reboot the machine, you'll get a command-line logon prompt, instead of the GUI one. From here, logon as root, uninstall all of KDE (and QT as well), install the new KDE (in the order I'm about to present), and reset your logon to runlevel 5. If you're running SuSe, you can do this from Yast2, either directly from the command line, or through the GUI by using the command "startx" to run the X server, and KDE. Now that Yast2 has been released under the GPL, hopefully it will be more widely available.
Note: Read this entire document carefully before trying any of it on your computer! Make sure you have all the materials necessary, and don't close any windows or reboot until you're done.
The order in which you install KDE is important, no matter how you do it. The first thing that gets installed isn't KDE, but QT, which is the graphics layer beneath KDE. Install the package "qt3.rpm". In SuSe, this is done by double-clicking on the file's icon. Trying to install this package results in a lot of dependency warnings/errors, which is to be expected for such a low-level package. In Yast2, a dialog box will list these dependencies, and offer three alternatives: don't install, force the install, ignoring the dependencies, and remove the offending packages. The dependency problem with qt3 is primarily with qt3_devel and qt3-non-mt. You're going to replace those two anyway in a moment, so go ahead and remove them before installing qt3 (forcing the install may also be ok in this circumstance, but I thought removal was safer. It might not make any difference). Before you do, though, take a good look at the dependencies on your machine. If you see anything other than QT or KDE stuff in that list, stop right there until you know what it is you're removing. On my machine, Yast2 informed me that 20 packages were in conflict, every one of which being some part of QT or KDE that was going to be replaced anyway.
Once "qt3.rpm" is installed, go ahead and install "qt3-devel.rpm", followed by "qt3-non-mt.rpm". QT has now been updated.
You now have to update arts, the audio support used by KDE. Install "arts.rpm", followed by "arts-gmcop.rpm", and then "arts-devel.rpm. I'm not sure if these last two have to be done in that order, but that's what worked for me.
Next on the agenda are the KDE libs. First install "kdelibs3.rpm", and then "kdelibs3-devel.rpm"
We're getting to the good stuff now. Install the file "kdebase3.rpm". Once more, you will get dependency errors. Two of these, the kate text editor and the konqueror browser you can safely remove, as you're going to replace them with 3.3 versions anyway before you're done. The nasty bit in my case was the reference to "kdebase-suse", which isn't part of the KDE release, but an add-on in the original SuSe distro. In this case, I simply forced the installation, ignoring the error, and Nothing Bad Happened.
Install the file "kdebase3-devel.rpm" to finish the base installation.
Now, re-install kate with "kdeaddons3-kate.rpm" and konqueror with "kdeaddons3-konqueror.rpm", so you don't forget.
Finally, install the remaining KDE packages. It doesn't matter in which order.
If you performed the upgrade from within KDE, as I did, you need to do one more thing, or you'll see lots of error messages that say "Unable to create io-slave". Delete the directory "/tmp/kde-user", where "user" is your login id (for example, I had to delete "/tmp/kde-tbrown"). Log out then back in to restart the X server and KDE. The upgrade is done.
My KDE upgrade works just fine, except for the KDevelop and screensaver issues. I did install an updated "kdeartwork3-xscreensaver.rpm" file, but there must be something that I missed. One additional oddity is that windows generated by Superkaramba are now always on top, with no setting I could find that would make them behave like any other window. Obviously, something has changed between version 3.1 and 3.3 in the way KDE treats those windows, since they worked fine before the upgrade.
I may be in the minority here, but I'd welcome a single-file installer for KDE, however large it would have to be to include all the necessary pieces. Most Linux programs don't need an installer, but KDE isn't one of them. Still, with a little information and experimentation, I managed to do without.
![[BIO]](../gx/2002/note.png) Tom has been a software developer since the early days of the Commodore 64,
with such commercial classics as Prototerm-64 and Colorez-128, and has seen
lots of operating systems come and go. Every one he's liked is either
discontinued (OS/2) or out of business (Commodore Amiga). He currently likes
Red Hat Linux, which won't be supported after April '04. As a result, we've
been trying to get him to fall in love with Windows, but so far no luck.
Tom has been a software developer since the early days of the Commodore 64,
with such commercial classics as Prototerm-64 and Colorez-128, and has seen
lots of operating systems come and go. Every one he's liked is either
discontinued (OS/2) or out of business (Commodore Amiga). He currently likes
Red Hat Linux, which won't be supported after April '04. As a result, we've
been trying to get him to fall in love with Windows, but so far no luck.
By Mike Chirico
Lemon is a compact, thread safe, well-tested parser generator written by Dr. Richard Hipp. Using a parser generator, along with a scanner like flex, can be advantageous because there is less code to write. You just write the grammar for the parser.
Compare this to writing all of the raw code from scratch. For instance, compare the basic C++ desktop calculator to the file below. Below is a syntax file which contains the grammar that the parser uses. "example1.y" is an example syntax file for a very basic calculator.
1 %token_type {int}
2
3 %left PLUS MINUS.
4 %left DIVIDE TIMES.
5
6 %include {
7 #include <iostream>
8 #include "example1.h"
9 }
10
11 %syntax_error {
12 std::cout << "Syntax error!" << std::endl;
13 }
14
15 program ::= expr(A). { std::cout << "Result=" << A << std::endl; }
16
17 expr(A) ::= expr(B) MINUS expr(C). { A = B - C; }
18 expr(A) ::= expr(B) PLUS expr(C). { A = B + C; }
19 expr(A) ::= expr(B) TIMES expr(C). { A = B * C; }
20 expr(A) ::= expr(B) DIVIDE expr(C). {
21 if(C != 0){
22 A = B / C;
23 }else{
24 std::cout << "divide by zero" << std::endl;
25 }
26 } /* end of DIVIDE */
27 expr(A) ::= INTEGER(B). { A = B; }
As you can see, this file is only 27 lines of code, not counting spaces. It is much easer to modify the grammar than it is to rewrite larger sections of raw code.
The parser generator (lemon.c and lempar.c) takes the input from the syntax file "example1.y" and creates the parser file "example1.c", along with two other files "example1.h", which contains definitions for the tokens, and "example1.out", which gives a detailed listing of the shift reduce states for the grammar listed in "example1.y".
Let's run through the steps, starting first with compiling the source code of lemon (available here). The first step is to compile lemon.c:
$ gcc -o lemon lemon.c
Now we have our parser generator, lemon, so run the syntax
file "example1.y" through it.
$ ./lemon example1.y
This will create example1.c, example1.h, and example1.out. What about lempar.c? Compare "example1.c" with "lempar.c", and you will see that it contains a lot of the same code. "lempar.c" is a template file. You can modify the code if you want, and all modifications will be passed to "example1.c" (including any comments).
But "example1.c" is not complete. We'll append the contents of the file "main_part", which contains a main function and tokens. "main_part" is called a driver.
1 int main()
2 {
3 void* pParser = ParseAlloc (malloc);
4 /* First input:
5 15 / 5
6 */
7 Parse (pParser, INTEGER, 15);
8 Parse (pParser, DIVIDE, 0);
9 Parse (pParser, INTEGER, 5);
10 Parse (pParser, 0, 0);
11 /* Second input:
12 50 + 125
13 */
14 Parse (pParser, INTEGER, 50);
15 Parse (pParser, PLUS, 0);
16 Parse (pParser, INTEGER, 125);
17 Parse (pParser, 0, 0);
18 /* Third input:
19 50 * 125 + 125
20 */
21 Parse (pParser, INTEGER, 50);
22 Parse (pParser, TIMES, 0);
23 Parse (pParser, INTEGER, 125);
24 Parse (pParser, PLUS, 0);
25 Parse (pParser, INTEGER, 125);
26 Parse (pParser, 0, 0);
27 ParseFree(pParser, free );
28 }
So, what is main_part doing? Well, line 3 initializes the parser. You'll note that pParser is passed to each call of the "Parse" function starting at line 7. The expression 15/5, or 15 DIVIDE 5, is performed in lines 7 through 10, sending first the INTEGER 15, then the identifier DIVIDE, which doesn't need a value, so 0 is chosen as the third parameter on line 8. Finally, line 10, with 0 as the second parameter in "Parse(pParser, 0, 0);" signals the end of the input for this expression. (Please note that in "example4.y", the grammar will handle this with a NEWLINE, and "Parse(pParser,0,...);" will only be called at the very end of the syntax file.)
"main_part" is appended to "example1.c". You may want to reference the Makefile with the downloadable example, which has this step:
$ cat main_part >> example1.c
Next, just compile example1.c, and it's good to go.
$ g++ -o ex1 example1.c
Now execute "ex1", and we'll see that the result of 15/5 is, of course, 3. And 50+125 is equal to 175, and 50*125+125 is indeed equal to (50*125)+125= 6375. This last result verifies that TIMES has higher precedence than PLUS.
$ ./ex1
Result=3
Result=175
Result=6375
Now for a closer look at the syntax file (example1.y). Why does TIMES have higher precedence than PLUS? Line 3 and line 4 determine the precedence of the operators PLUS, MINUS, DIVIDE, and TIMES.
3 %left PLUS MINUS.
4 %left DIVIDE TIMES.
Lines at the top have a lower operator precedence. This is very important to note. PLUS and MINUS have less operator precedence than DIVIDE and TIMES because PLUS and MINUS are on line 3, whereas DIVIDE and TIMES are on line 4. If, for example, exponentiation (EXP) were added, since EXP has even higher operator precedence than TIMES and DIVIDE, it would be added below line 4.
What if you wanted real numbers in the input, 15.5,5.2 instead of integers? How would you do that? It's easy. These tokens are currently integers because of the following line in "example1.y":
1 %token_type {int}
So to accommodate a double, line 1 would be changed to:
%token_type {double}
Moving further down the lines of "example1.y", there is an "include" directive on line 6. The include statement in "example1.y" passes along any C statements, which are inserted at the beginning of the parse file "example1.c". Again, the contents are inserted into the beginning of "example1.c", which is necessary for declarations and headers.
...
6 %include {
7 #include <iostream>
8 #include "example1.h"
9 }
...
Note that "example1.h" is generated from "$ ./lemon
example1.y". It defines the tokens, or, put another way, assigns
integer values to the token names starting at 1. Why start at 1, and
not 0? Because 0 is reserved for the Parse function. Remember, "Parse
(pParser, 0, 0);", with the second parameter set to zero, signals an end
to the input.
example1.h (note, this is a generated file; do not add code to it):
#define PLUS 1
#define MINUS 2
#define DIVIDE 3
#define TIMES 4
#define INTEGER 5
"example2.y" differs from "example1.y" by defining the token type as a structure. Specifically, this token type is defined in the file "ex2def.h". Defining our own structure can give us flexibility in the semantic action, or the piece of code on the right of the production rule. Here is an example:
expr(A) ::= expr(B) TIMES expr(C). { A.value = B.value * C.value;
A.n = B.n+1 + C.n+1;
}
The token_type in "example2.y" is defined as Token in line 6.
6 %token_type {Token}
This structure Token is defined in "ex2def.h" as follows:
struct Token {
const char *z;
int value;
unsigned n;
};
Special note: "const char *z" is not used in these examples, but I've kept it in this structure, since it's the next logical step in a calculator, assigning an expression to a variable. For instance, variable1=2+5, where variable1 would be some value in a symbol table. See this reference.
Again, note the change in the include directive, the addition of "ex2def.h", which defines struct Token.
1 #include {
2 #include <iostream>
3 #include "ex2def.h"
4 #include "example2.h"
5 }
6 %token_type {Token}
7 %default_type {Token}
8 %type expr {Token}
9 %type NUM {Token}
10
11 %left PLUS MINUS.
12 %left DIVIDE TIMES.
13
14
15 %syntax_error {
16 std::cout << "Syntax error!" << std::endl;
17 }
18
19 program ::= expr(A). {
20 std::cout << "Result.value=" << A.value << std::endl;
21 std::cout << "Result.n=" << A.n << std::endl;
22 }
23 expr(A) ::= expr(B) MINUS expr(C). { A.value = B.value - C.value;
24 A.n = B.n+1 + C.n+1;
25 }
26 expr(A) ::= expr(B) PLUS expr(C). { A.value = B.value + C.value;
27 A.n = B.n+1 + C.n+1;
28 }
29 expr(A) ::= expr(B) TIMES expr(C). { A.value = B.value * C.value;
30 A.n = B.n+1 + C.n+1;
31 }
32 expr(A) ::= expr(B) DIVIDE expr(C). {
33 if(C.value != 0){
34 A.value = B.value / C.value;
35 A.n = B.n+1 + C.n+1;
36 }else{
37 std::cout << "divide by zero" << std::endl;
38 }
39 } /* end of DIVIDE */
40 expr(A) ::= NUM(B). { A.value = B.value; A.n = B.n+1; }
As you can see below, taking a close look at lines 23 through 25, the Token structure A now takes on members "A.value" and "A.n", with ".value" taking on the value of the expression and ".n" the number of times an assignment is made:
23 expr(A) ::= expr(B) MINUS expr(C). { A.value = B.value - C.value;
24 A.n = B.n+1 + C.n+1;
25 }
This is a quick way to see the "shift" and "reduce" dynamically. A "shift"
is the number of times a token is pushed on the stack. A "reduce" is the
number of times an expression rule has been matched. Once it's matched, it
can be reduced. As you will recall, when lemon is run, three
files are normally created: *.c, *.h, and *.out. This ".out" file contains
each step of the grammar, along with the shift and reduce states. If you
want a simple summary, run lemon with the "-s" option:
$ ./lemon -s example2.y
Parser statistics: 6 terminals, 3 nonterminals, 6 rules
11 states, 0 parser table entries, 0 conflicts
Again, as in the previous example, "main_part2", the driver, is appended to "example2.c":
$ cat main_part2 >> example2.c
Now "example2.c" can be compiled and executed:
$ g++ -o ex2 example2.c
$ ./ex2
Result.value=17
Result.n=4
Result.value=-9
Result.n=4
Result.value=78
Result.n=10
One advantage of lemon over bison is the ability to free memory used by
a non-terminal. You can call the function of your choice.
"expr" is an example of a non-terminal. When the program is
done with the non-terminal, the function defined by
token_destructor is called.
1 %include {
2 #include <iostream>
3 #include "ex3def.h"
4 #include "example3.h"
5 void token_destructor(Token t)
6 {
7 std::cout << "In token_destructor t.value= " << t.value << std::endl;
8 std::cout << "In token_destructor t.n= " << t.n << std::endl;
9 }
10 }
11 %token_type {Token}
12 %default_type {Token}
13 %token_destructor { token_destructor($$); }
...
In line 13, token_destructor is the function
"token_destructor($$);". The function
"token_destructor" is defined in lines 5 through 9. For
this simple example, no memory is allocated, so there is no need to call
free. Instead, to see what is happening, output will be
written to std::cout.
After the program is compiled, it can be executed as follows. Note that I have added line numbers to the output of "ex3" for easy reference.
$ ./ex3
1 t0.value=4 PLUS t1.value=13
2 In token_destructor t.value= 4
3 In token_destructor t.n= 0
4 Result.value=17
5 Result.n=4
6 parsing complete!
...
After the expression has been reduced, the destructor is called, but it is only called for the token.value=4. Why? For an answer we will have to take a look at "main_part3".
1 int main()
2 {
3 void* pParser = ParseAlloc (malloc);
4 struct Token t0,t1;
5 struct Token mToken;
6 t0.value=4;
7 t0.n=0;
8 t1.value=13;
9 t1.n=0;
10 std::cout << " t0.value=4 PLUS t1.value=13 " << std::endl;
11 Parse (pParser, NUM, t0);
12 Parse (pParser, PLUS, t0);
13 Parse (pParser, NUM, t1);
14 Parse (pParser, 0, t0);
15 std::cout << " t0.value=4 DIVIDE t1.value=13 " << std::endl;
16 Parse (pParser, NUM, t0);
17 Parse (pParser, DIVIDE, t0);
18 Parse (pParser, NUM, t1);
19 Parse (pParser, 0, t1);
...
Line 14 terminates the grammar with t0 as the third
parameter. That third parameter is passed as "$$" to the
defined destructor function, "token_destructor(...". When
calling "Parse" a second time immediately, it is undefined,
so you should only call the destructor function once after you're done
passing tokens to complete an expression. In other words, you would
never call "Parse (pParser, 0, t0);", immediately followed
by another "Parse (pParser, 0, t0);".
In line 19, token_destructor is called for t1.value=
13. If you look at "main_part3", line 19, you'll see that
Parse is called with t1 as the third parameter
and 0 and the second parameter.
Continuation of the output from the program:
7
8
9 t1.value=13 PLUS t0.value=4
10 In token_destructor t.value= 13
11 In token_destructor t.n= 0
12 Result.value=17
13 Result.n=4
14 parsing complete!
So t0 is called at the third parameter position in line 14
and t1 is called in line 19. This shouldn't be a problem.
One variable could hold the value of the tokens. For instance,
main_part3 could have had Token t0 used for both the values
4 and 14 as follows:
...
struct Token t0;
t0.value=4;
t0.n=0;
Parse (pParser, NUM, t0);
Parse (pParser, PLUS, t0);
t0.value=13;
t0.n=0;
Parse (pParser, NUM, t0);
Parse (pParser, 0, t0);
...
Notice that in the last three examples, Parse(pParse,0..
had to be called to signal the end of the input for an expression. This
is awkward. Instead, the grammar should dictate when the expression can
no longer be reduced.
"example4.y" contains the following lines:
1 %include {
2 #include <iostream>
3 #include "ex4def.h"
4 #include "example4.h"
...
23
24 %syntax_error {
25 std::cout << "Syntax error!" << std::endl;
26 }
27
28 /* This is to terminate with a new line */
29 main ::= in.
30 in ::= .
31 in ::= in state NEWLINE.
32 state ::= expr(A). {
33 std::cout << "Result.value=" << A.value << std::end
34 std::cout << "Result.n=" << A.n << std::endl;
35 }
36 expr(A) ::= expr(B) MINUS expr(C). { A.value = B.value - C.value;
37 A.n = B.n+1 + C.n+1;
38 }
...
Note lines 29 through 35. "main" and "in"
must be defined (lines 29-31). If you're a Bison user, you could get
away without having to define the non-terminal main, but lemon currently
requires it.
With this change made to the grammar in "example4.y", "main_part4" can now terminate each expression by passing the token NEWLINE.
Here is a section of main_part4:
1 int main()
2 {
3 void* pParser = ParseAlloc (malloc);
4 struct Token t0,t1;
5 struct Token mToken;
6 t0.value=4;
7 t0.n=0;
8 t1.value=13;
9 t1.n=0;
10 std::cout << std::endl <<" t0.value=4 PLUS t1.value=13 " << std::endl << std::endl;
11 Parse (pParser, NUM, t0);
12 Parse (pParser, PLUS, t0);
13 Parse (pParser, NUM, t1);
14 Parse (pParser, NEWLINE, t1);
15 std::cout << std::endl <<" t0.value=4 TIMES t1.value=13 " << std::endl << std::endl;
Note that line 14 is passing the token NEWLINE and checking "example4.h". NEWLINE in this case is defined as an integer, 6.
So, looking at the output of "ex4", with line numbers added for clarification, we get the following:
$ ./ex4
1 t0.value=4 PLUS t1.value=13
2
3 In token_destructor t.value= 4
4 In token_destructor t.n= 0
5 Result.value=17
6 Result.n=4
7
8 t0.value=4 TIMES t1.value=13
9
10 In token_destructor t.value= 4
11 In token_destructor t.n= 0
12 Result.value=52
13 Result.n=4
14 parsing complete!
We get the result on line 5, and there was no need to call Parse
(pParser, 0, t0);. Instead, Parse( pParse, NEWLINE,
t0) worked.
The next example takes input directly from the terminal, and flex will create a scanner for finding the appropriate tokens.
First, a quick look at the flex program "lexer.l", again with line numbers added for clarification:
1 %{
2 #include "lexglobal.h"
3 #include "example5.h"
4 #include <string.h>
5 #include <math.h>
6 int line = 1, col = 1;
7 %}
8 %%
9 [0-9]+|[0-9]*\.[0-9]+ { col += (int) strlen(yytext);
10 yylval.dval = atof(yytext);
11 return NUM; }
12 [ \t] { col += (int) strlen(yytext); } /* ignore but count white space */
13 [A-Za-z][A-Za-z0-9]* { /* ignore but needed for variables */
14 return 0;
15 }
16 "+" { return PLUS; }
17 "-" { return MINUS; }
18 "*" { return TIMES; }
19 "/" { return DIVIDE; }
20 \n { col = 0; ++line; return NEWLINE; }
21 . { col += (int) strlen(yytext); return yytext[0]; }
22 %%
23 /**
24 * reset the line and column count
25 *
26 *
27 */
28 void reset_lexer(void)
29 {
30 line = 1;
31 col = 1;
32 }
33 /**
34 * yyerror() is invoked when the lexer or the parser encounter
35 * an error. The error message is passed via *s
36 *
37 *
38 */
39 void yyerror(char *s)
40 {
41 printf("error: %s at line: %d col: %d\n",s,line,col);
42 }
43 int yywrap(void)
44 {
45 return 1;
46 }
The format for flex is basically a rule on the left side followed by C
code to execute on the right side. Take line 9,
"[0-9]+|[0-9]*\.[0-9]+", which will match any of 3, .3,
0.3, and 23.4 and will return NUM. What's the value of NUM? It's taken
from line 3, which includes the file "example5.h", generated from
the lemon parser. On Line 10, yylval.dval is assigned the
value of "yytext" after it's converted to a float. The
structure of yylval is defined in "lexglobal.h" on line 2.
"lexglobal.h" with line numbers added:
1 #ifndef YYSTYPE
2 typedef union {
3 double dval;
4 struct symtab *symp;
5 } yystype;
6 # define YYSTYPE yystype
7 # define YYSTYPE_IS_TRIVIAL 1
8 #endif
9 /* extern YYSTYPE yylval; */
10 YYSTYPE yylval;
yystype is the union of dval and
symtab. Again, symtab is not used in these
examples, but should you move to a calculator with variables that can be
assigned, you'd use this. See Reference 3 for a full calculator example
with flex and bison.
Again looking at lines 9 through 11 in lexer.l;
...
9 [0-9]+|[0-9]*\.[0-9]+ { col += (int) strlen(yytext);
10 yylval.dval = atof(yytext);
11 return NUM; }
...
Both the type of token, NUM, and its value must be passed along. We need to know it's a number, but we also need to know the value of the number.
Unlike what we need with PLUS, MINUS, TIME, and DIVIDE, we only need to know the particular identifier has been found. Therefore, in lexer.l, lines 16 through 19 only return the token value.
16 "+" { return PLUS; }
17 "-" { return MINUS; }
18 "*" { return TIMES; }
19 "/" { return DIVIDE; }
20 \n { col = 0; ++line; return NEWLINE; }
21 . { col += (int) strlen(yytext); return yytext[0]; }
22 %%
Line 20 will match on a NEWLINE. Although not used, line numbers keep
track of the variable "line" and col is used
to track the number of columns. This is a good idea; it is helpful when
debugging.
The driver, main_part5, contains a lot more code. The low level read
statement is used on stdin. This could easily be changed to accept
input coming in on a socket descriptor, so if you had a Web scraping
program that scans input from a TCP socket, the socket descriptor would
replace "fileno(stdin)" on line 33.
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <sys/types.h>
4 #include <sys/stat.h>
5 #include <fcntl.h>
6 #include <stdlib.h>
7 #define BUFS 1024
8 /**
9 * We have to declare these here - they're not in any header files
10 * we can include. yyparse() is declared with an empty argument list
11 * so that it is compatible with the generated C code from bison.
12 *
13 */
14 extern FILE *yyin;
15 typedef struct yy_buffer_state *YY_BUFFER_STATE;
16 extern "C" {
17 int yylex( void );
18 YY_BUFFER_STATE yy_scan_string( const char * );
19 void yy_delete_buffer( YY_BUFFER_STATE );
20 }
21 int main(int argc,char** argv)
22 {
23 int n;
24 int yv;
25 char buf[BUFS+1];
26 void* pParser = ParseAlloc (malloc);
27 struct Token t0,t1;
28 struct Token mToken;
29 t0.n=0;
30 t0.value=0;
31 std::cout << "Enter an expression like 3+5 <return>" << std::endl;
32 std::cout << " Terminate with ^D" << std::endl;
33 while ( ( n=read(fileno(stdin), buf, BUFS )) > 0)
34 {
35 buf[n]='\0';
36 yy_scan_string(buf);
37 // on EOF yylex will return 0
38 while( (yv=yylex()) != 0)
39 {
40 std::cout << " yylex() " << yv << " yylval.dval " << yylval.dval << std::endl;
41 t0.value=yylval.dval;
42 Parse (pParser, yv, t0);
43 }
44 }
45 Parse (pParser, 0, t0);
46 ParseFree(pParser, free );
47 }
Line 16, 'extern "C"', is necessary because "lexer.l" was
run through flex to create C code, as opposed to C++ code:
$ flex lexer.l
See the flex manual, Reference 7. Yes, "flex++" will
output C++ code. However, for complex scanning, C code may be faster.
"main_part5", which is compiled as a C++ program, makes the transition
smoothly.
The parser should always terminate input with 0 in the second parameter
to "Parse(pParser,0,..". When there is no more input
coming into flex, it will return a zero, so the
while loop below on line 38 terminates with a zero. Then
the read statement, line 33, looks for more input. This is
something you would want to do when reading from a socket, since it may
have been delayed.
But if the initial read (line 33 for the first time) isn't successful, flex has no chance of returning a zero. Therefore, line 45 has a zero as the second parameter.
...
33 while ( ( n=read(fileno(stdin), buf, BUFS )) > 0)
...
38 while( (yv=yylex()) != 0)
39 {
40 std::cout << " yylex() " << yv << " yylval.dval " << yylval.dval << std::endl;
41 t0.value=yylval.dval;
42 Parse (pParser, yv, t0);
43 }
...
45 Parse (pParser, 0, t0);
46 ParseFree(pParser, free );
lemon is fast, completely in the public domain, well tested in SQLite, and thread safe. Parser generators can help developers write reusable code for complex tasks in a fraction of the time they would need for writing the complete program from scratch. The syntax file, the file that holds the grammar, can be modified to suit multiple needs.
Although I have had no problems with lemon.c, there are a few compiler warnings regarding signed and unsigned integers when compiling it with the -Wall -W flags:
[chirico@third-fl-71 lemon_examples]$ gcc -Wall -W -O2 -s -pipe lemon.c
lemon.c: In function `resolve_conflict':
lemon.c:973: warning: unused parameter `errsym'
lemon.c: In function `main':
lemon.c:1342: warning: unused parameter `argc'
lemon.c: At top level:
lemon.c:2308: warning: return type defaults to `int'
lemon.c: In function `preprocess_input':
lemon.c:2334: warning: comparison between signed and unsigned
lemon.c:2352: warning: control reaches end of non-void function
lemon.c:2311: warning: `start' might be used uninitialized in this function
lemon.c:2313: warning: `start_lineno' might be used uninitialized in this function
lemon.c: In function `Parse':
lemon.c:2393: warning: comparison between signed and unsigned
lemon.c: In function `tplt_open':
lemon.c:2904: warning: implicit declaration of function `access'
lemon.c: In function `append_str':
lemon.c:3019: warning: comparison between signed and unsigned
lemon.c:3011: warning: unused variable `i'
lemon.c: In function `translate_code':
lemon.c:3109: warning: control reaches end of non-void function
This can be an inconvenience when adding the parse.c file to existing code. A fix is on the way. Since I expect the changes to be cleaned up soon, this version of lemon.c is the same version that you'd get from the author's site, which will make it easier to apply the patch.
There are times when a parser like lemon or bison may be a little too much. These are powerful tools. An interesting alternative, if you're a C++ programmer and you only need to do inline parsing, is the spirit library. See Reference 9.
The complete source for these examples, including the parser itself, can be downloaded here.
![[BIO]](../gx/authors/chirico.jpg) Mike Chirico, a father of triplets (all girls) lives outside of
Philadelphia, PA, USA. He has worked with Linux since 1996, has a Masters
in Computer Science and Mathematics from Villanova University, and has
worked in computer-related jobs from Wall Street to the University of
Pennsylvania. His hero is Paul Erdos, a brilliant number theorist who was
known for his open collaboration with others.
Mike Chirico, a father of triplets (all girls) lives outside of
Philadelphia, PA, USA. He has worked with Linux since 1996, has a Masters
in Computer Science and Mathematics from Villanova University, and has
worked in computer-related jobs from Wall Street to the University of
Pennsylvania. His hero is Paul Erdos, a brilliant number theorist who was
known for his open collaboration with others.
Mike's notes page is souptonuts.
By John Murray
Note: When I wrote the first version of this article in 2001, I was using a 233mhz machine with 32megs of RAM. And while my current box has specs of about ten times those numbers, I mainly still use the same speedy applications covered in the story below...
I first started playing with Linux a few years ago, after reading several Introduction-To-Linux articles in computer magazines and on the web. In almost all of these articles, low hardware requirements are listed as one of Linux's advantages. Usually the authors then go on to show how easy it is to use Linux on the desktop with the GNOME or KDE desktop environments.
So I set up my machine to dual-boot Win95 and Linux, and experimented with several different distros. Initially I was disappointed with the performance of Linux, and it took me a while to discover the performance gains made possible by running leaner software. The fact that most of the newbie-oriented documentation emphasised GNOME/KDE while ignoring everything else only made things harder. That's what this page is all about - a newbie's guide to good, lightweight software that runs well on boxes that are less than state-of-the-art.
GNOME and KDE are good-looking, feature-packed environments that are as easy to use as the desktop on that other OS, but they aren't the best choice for an older machine - they can actually be quite sluggish unless you have some fairly recent hardware to run them. That doesn't mean you're stuck with a text-only console though, as it's easy to set up a nice looking Linux desktop that has plenty of speed on something like an early Pentium with 32megs of RAM, though 64megs is even better.
A speedy desktop is largely just a matter of using a window manager and
applications that suit your hardware. And by the way, just because you don't
use the KDE or GNOME desktop environments doesn't mean you shouldn't install
them, or at least their core libraries. KDE and GNOME apps will run quite well
under a lightweight window manager, so if you have the disk space, I recommend
installing both. In my experience though, GNOME/GTK apps load appreciably
quicker than the KDE equivalents. Listed
below are some suggestions for the type of apps. that most people use
everyday, all of which work nicely on my 233/64 box - and most of this stuff
should be fine with just 32megs of RAM. Keep in mind that these suggestions
are only my own personal preferences; they certainly aren't the only
way to do things.
You'll find a lot of this stuff is included on the installation cd's of most distro's. Wherever possible, I've provided a link to the projects homepage.
The choice of window manager can have a dramatic effect on system performance, and there are several good, lightweight WMs available, my favourite being IceWm . As well as having a small memory footprint, IceWm can be made to look quite good with wallpapers and themes . It also has that familiar Win95 layout with the corner start button, menus, toolbar and so on. There are certainly lighter WMs around, but for me IceWm provides a good balance of useful features and performance - and it is lighter on RAM than some other window managers with far fewer features. Don't assume that IceWm has to be plain or ugly - current versions can support XFT antialiasing, gradients and so on, and with a theme like Silver XP can be quite good-looking.
Configuring IceWm is extremely easy, and while there are graphical tools available for this, it's just as easy to edit its configuration files manually. The global configuration files are usually in /usr/X11R6/lib/X11/icewm/ and are named preferences , menu and toolbar . Make a hidden folder called .icewm in your home directory and copy these three files into it. Then it's just a matter of editing them to suit your own needs and tastes.
IceWm is included with many recent distros, and includes very good documentation in /usr/doc/icewm.
Xfce is another popular, fast window manager, though strictly speaking it's really a desktop environment. Worth a look if you want something with more bells and whistles - but I still prefer IceWm.
I've tried plenty of graphical file managers, but I always come back to XWC (X Windows Commander) because of its speed, stability, and again for its familiar interface. XWC is a clone of the Win95 style Explorer that supports drag'n'drop to copy/move/symlink, file associations and so on. Although it lacks many of the features of say, Nautilus or Konqueror, its got everything I need, without the bloat. Like IceWm, it is very easy to configure using the built in options menu or by editing the ~/.foxrc/XWC file.
While I'd prefer something that doesn't look quite so Windows-like, XWC works very well and is quite speedy. It also includes a handy archiving tool, a media mounting tool and a rather ordinary front end to RPM. XWC can be used in two-panel mode, like all good file managers.
Work has recently resumed on XWC, mainly in an effort to support a greater variety of languages. A couple of file managers have evolved from XWC, namely XFE and Fox Commander, and although they are more modern looking, I still find XWC to be the best for stability and performance.
Another fast, good looking filer that is highly recommended is rox
Forget about the korpulent konsole, rxvt has a combination of features and speed that make it my favourite, plus you can customise its appearance if you are into that sort of thing. An even lighter alternative is aterm.
While XWC comes with its own (very) basic editor, I much prefer Nedit . Nedit is fairly small, is fast and has lots of useful features built in, including: syntax highlighting, search and replace, macro support, shell access and much more. The built in help is very good as well. I know some people get passionate about their editors ( especially the vi crowd ), but if you want a good WYSIWYG style editor, Nedit is very nice indeed.
Another editor that I like to have available is Nano, an exceptionally light, basic app. that will be instantly familiar to Pine/Pico users. Unlike Nedit, Nano will run from a console as well as an X-terminal, and the value of this will be appreciated by anyone who's misconfigured their XF86-Config file to the point that X won't start ;)
Linux users now have a choice of quality browsers that match or beat the performance of those on other platforms, though some are a little resource hungry. These range from basic (but speedy) browsers like Dillo and Links-Graphic to the ones based on a stripped down Mozilla, such as Galeon and Firefox.
At the lighter end of the range, links-graphic is hard to beat. Speedy, and with a small footprint, it is surprisingly capable, and can handle frames and tables as well as javascript. Its interface is a little different to most other graphical browsers, but quite good once you get used to it. Dillo is another one worth trying. Dillo is extremely fast, and quite good looking as well. Still under development, it doesn't yet handle frames, java or javascript, so you probably won't be able to do your online banking with it. It's brilliant for reading local html files (like helpfiles and /usr/doc/html/ stuff).
Opera is a very popular browser that fits somewhere between the superlight apps like links-graphic or Dillo, and the heavy duty Mozilla based browsers. The free-download version of Opera includes banner advertising, though it's not really intrusive. It performs well, and supports most popular plugins.
If you have 64meg or more, you might want to try one of the Mozilla
based browsers. Galeon and
Firefox are two very good browsers based
on the Mozilla engine. Unlike Mozilla, Galeon and Firefox are web browsers only, making them significantly
more usable on slower machines, though they will still be slowish to start on an old machine.
They are exceptionally capable and stable, and support most plugins.
As for email, I like Sylpheed. Sylpheed is very fast, and has a nice clear interface. It is also a basic newsreader. There is also a related mail client named SylpheedClaws that extends the capabilities of Sylpheed via the use of plugins and enables things like HTML and so on.
If you'd like a more fully featured news client, so you might want to try Pan, a GTK news app. capable of handling binary attachments.
I know there are several graphical ftp clients, and I did play
briefly with gFTP (which ran fine), but I
can't really recommend anything else as I still prefer the command-line ncftp.
I use xli as my default image viewer. It's quick, and I like the way I can directly scroll big images with the mouse; qiv (Quick Image Viewer) is nice as well. For simple manipulations xv works well and requires little memory, though the interface is showing its age.
The hugely popular XMMS is a WinAmp clone that can play mp3, ogg-vorbis, wav and cdr files etc. It also supports skins, including WinAmp skins. As for video mpegs, I use mtvp as the default player. It's a free player that's part of the mtv package and works very well on lower end machines. If you view lots of videos in different formats, MPlayer plays nearly all of them and is surprisingly quick on older boxes. The officially supported version is only available as source, though binary packages are available as well. MPlayer can even make use of MS Windows dlls to play Windows media files.
There are also plenty of graphical front ends around for cd recording
software. I have played around with the very popular
xcdroast , but mainly I still use command line tools like cdrecord,
mpg123, bladeenc etc. Again, let me know if you have recommendations.
Abiword is GNOME's word processor, and is notable for its speed and light memory usage. It is also lighter on features than say OpenOffice-Writer or KWrite, but for some this simplicity may be appealing. At present Abiword seems to be able to open the less complex MS-Word documents without problems, but chokes on .doc files with complicated formatting.
TextMaker is a commercial product, and while I haven't tried it personally, it does receive glowing reviews. Both speed and .doc file compatibility are said to be very good, so this should be a good choice for older hardware. If you think this sounds appealing, and you don't mind paying for software, this might be for you. There is a 30 day trial version available from the TextMaker website.
The last available version (version 9, part of WordPerfect Office2000) was actually just the Windows version running under a built-in version of Wine. While this version had a reputation for instability and other problems, an older, Linux native version (Wordperfect8) still enjoys some popularity - some still consider it as the best Linux word processor available. WP8 is stable, fast and full featured, and light on memory usage. The Download Personal Edition is still available, though its age dictates that some older libraries also need to be installed in order to get it working on newer distros - more info here.
KWord is the KDE project's word processor, and it looks and works very well, however it also has limited compatability with MS .doc files at present.
If MSWord compatability is critical, you'll really have no choice but to run OpenOffice.org or StarOffice. These suites are big and extremely slow to load, though recent versions are much improved in this regard. Even so, firing them up on a box with only 32megs of ram may take up to a minute... Once loaded though, they are stable and run fine. They seem to be able to handle nearly any .doc format file much better than any of the others, so even if you choose to use a different word processor for your regular work, it may pay to install Star/Open Office so you can open those difficult .doc files that your usual WP has trouble with.
For those who don't require any MS Word compatability, Netscape (or Mozilla) Composer can do a pretty good job of producing printed documents. While it's not really a word processor, it can do tables, embed images and links as well as spell check. Plus the html output is readable on just about anything. Keep Composer in mind if you just want to write the occasional letter without installing a full-blown WP program.
Gnumeric should probably be your first choice here; it's a mature app. that seems to handle Excel files exceptionally well without hogging resources. KSpread , like KWord, also runs well enough but doesn't completely work with Microsoft formats just yet.
The table below shows the approximate startup times for some of the
software mentioned above. These times were measured on a 233 mHz AMD with
64meg of RAM and Linux 2.2, using the highly unscientific method of clicking
on the button and then counting the delay using the toolbar clock. Of course,
a calendar might be more appropriate for timing Star/Open Office...The figures
are obviously only rough approximations in view of the measurement technique,
but they do give a good indication of just how responsive an old Linux box can
be.
|
Program |
First Startup |
Subsequent Starts |
|
XWindowsCommander |
1 sec |
0.5 sec |
|
Nedit |
2 secs |
1.5 sec |
|
Netscape 4.77 |
9 secs |
4 secs |
|
Dillo |
1 sec |
0.5 sec |
|
Sylpheed |
1.5 sec |
1 sec |
|
xli (XLoadImage) |
<1 sec |
0.5 sec |
|
XMMS |
3 sec |
2.5 sec |
|
mtvp |
1 sec |
0.5 sec |
|
Gnumeric |
6 secs |
4 secs |
|
AbiWord |
2.5 secs |
2 secs |
Screen Savers are probably more of a nicety than a necessity. Xscreensaver works very well with lightweight window managers and is easy to set up. It can run a randomly picked screensaver after a user-set period, and continue to change it at pre-set intervals. Run xscreensaver-demo to set the preferences, or see the man pages for more details. The easiest way to start xscreensaver automatically at login is by adding the xscreensaver & command to your window manager's startup script, eg. /usr/X11R6/bin/icewm.
Unnecessary Services or daemons can slow your machine down and
lengthen bootup times. Default installations often run all sorts of servers
and other stuff that you don't need. As well as using resources, these things
can increase your security risk.
Here are some screenshots of some of
the things mentioned above.
Some sites that might be useful:
LoFat Part 2 - A guide to the post install
tune-up
The Linux Terminal Server Project - a great
way to use those old boxes as thin clients
Comments, corrections and suggestions are welcome. Send them to:

Last modified August 15, 2004
A more-or-less complete listing of the Linux-related stuff that I've written can be found at my homepage.
John is a part-time geek from Orange, Australia. He has been using
Linux for four years and has written several Linux related
articles.
ps binary
with his own to hide his processes, added a new service that was executed
from the binary "/bin/crond " (the space is
intentional - it makes it look like a normal and an expected process in
a running-processes listing and a normal binary in a directory listing).
The "crond " process gathered usernames and
passwords and stored them in a text file in the directory
"/dev/pf0 /
/", (5 and 2 spaces respectively), which also contained a
root shell. The chances of me finding and identifying this intrusion
would have been extremely remote if I had not been running Tripwire.
Tripwire is a file integrity checker for UNIX/Linux based operating systems and works as an excellent intrusion detection system. It will not prevent an intrusion; for this see my previous articles on setting up firewalls and securing a Linux distribution for help.
The idea behind Tripwire is quite simple: it first creates a "baseline" database of the state of the files and directories on your system and then on subsequent runs it compares the current state of the files and directories against this baseline identifying any deletions, additions or changes. The files and directories to be checked are decided by a "policy" file. This file also defines what attributes to compare; this can include access, inode and modification timestamps, owner and group IDs, permissions, file size and type, MD5 and SHA hash values, etc.
In this article I will guide you through the process of getting and installing Tripwire, configuring it and setting it up to run on a daily basis. In the final section I will mention a few additional steps you can take to ensure the integrity of your Tripwire database and thus your file system.
If you cannot locate a precompiled package for your distribution, then you can download the latest source code from http://sourceforge.net/projects/tripwire/. The version available at time of going to press was 2.3.1-2. This version is dated March 2001 and when I tried to compile it on my system I got a myriad of errors. The sources do not use the autoconf/automake build system and this may be the main cause of the errors. I have decided to place the resolution of these problems outside the scope of this article given the availability of precompiled packages for many distributions.
/etc/tripwire. The plain text versions are called
twcfg.txt and twpol.txt, and the encoded and
signed versions are called tw.cfg and tw.pol.
The plain-text version of the configuration file contains key-value pairs
including the following required variables (default values for my
distribution shown):
POLFILE = /etc/tripwire/tw.pol DBFILE = /var/lib/tripwire/$HOSTNAME.twd REPORTFILE = /var/lib/tripwire/report/$HOSTNAME-$DATE.twr SITEKEYFILE = /etc/tripwire/site.key LOCALKEYFILE = /etc/tripwire/$HOSTNAME-local.key
The POLFILE, DBFILE and
REPORTFILE dictate the locations of the policy file, the
database file and the report file respectively. A report file is
generated each time Tripwire is used to check the integrity of the
file system and its name is determined by both the hostname and current
date. The SITEKEYFILE and LOCALKEYFILE variables
hold the locations of the two key files; site keys are used for signing
files that can be used on multiple systems within an organisation such
as the policy and configuration files, while the local key is used for
files specific to this system such as the database file.
Ensure that the $HOSTNAME environment variable is correctly
set to your system's hostname before using any of Tripwire's commands. Also,
the HOSTNAME variable in twpol.txt
must be set correctly so that it matches the system's
hostname. If you are unsure of what the system's hostname is set to, then
execute echo $HOSTNAME on the command line.
Other configuration file values we will use are shown here followed by a description of each:
EDITOR =/bin/vi MAILNOVIOLATIONS =true EMAILREPORTLEVEL =3 REPORTLEVEL =3 MAILMETHOD =SENDMAIL MAILPROGRAM =/usr/sbin/sendmail -oi -t
EDITOR
MAILNOVIOLATIONS
EMAILREPORTLEVEL and REPORTLEVEL
MAILMETHOD and MAILPROGRAM
SMTP (in which case
additional variables have to be set to indicate the SMTP host and port)
or SENDMAIL (in which case we include the
MAILPROGRAM variable).
There are a number of other options and these are explained in the man
page: TWCONFIG(4).
Creating your own policy file is a long and tedious task that is also outside the scope of this article. If you get a packaged version of Tripwire for your distribution then the policy file should already be created. The policy file is essentially a list of rules and associated files which should be checked by Tripwire; the rules indicate the severity of a violation. The text version of the file itself is quite readable and is worth a look to fully understand how Tripwire works. Also, irrespective of your distribution, you will find that Tripwire generates a lot of the following errors when checking the filesystem:
File system error. Filename: XXXXXXXXXXXXX No such file or directoryFor each of these errors there is an entry for the named file in the policy file but this file does not exist on your system. You will have to edit the policy file and comment out these lines.
Tripwire comes with four binary files:
tripwire
twadmin
twprint
siggen
In this section we will set Tripwire up so that you can use it on a
daily basis to check your systems integrity. I am assuming that the
current working directory is /etc/tripwire and that the
following files exist in the specified paths:
/etc/tripwire/twcfg.txt:
| plain-text version of the configuration file |
/etc/tripwire/twpol.txt:
| plain-text version of the policy file |
The first step is to generate the keys to be used when signing the database, policy file and configuration file. You will be asked for a passphrase for each of the local and site keys; it should be greater than 8 characters and include punctuation symbols as well as alphanumeric characters.
[root@home /etc/tripwire]# twadmin --generate-keys --site-keyfile ./site.key (When selecting a passphrase, keep in mind that good passphrases typically have upper and lower case letters, digits and punctuation marks, and are at least 8 characters in length.) Enter the site keyfile passphrase: XXXXXXXXXXXXXXXXXX Verify the site keyfile passphrase: XXXXXXXXXXXXXXXXXX Generating key (this may take several minutes)...Key generation complete. [root@home /etc/tripwire]# twadmin --generate-keys --local-keyfile ./$HOSTNAME-local.key Enter the local keyfile passphrase: XXXXXXXXXXXXXXXXXX Verify the local keyfile passphrase: XXXXXXXXXXXXXXXXXX Generating key (this may take several minutes)...Key generation complete. [root@home /etc/tripwire]#
Now that we have generated our keys, we need to sign the configuration and policy files (after editing them as required):
[root@home /etc/tripwire]# twadmin --create-cfgfile --cfgfile ./tw.cfg --site-keyfile ./site.key \
twcfg.txt
Please enter your site passphrase: XXXXXXXXXXXXXXXXXX
Wrote configuration file: /etc/tripwire/tw.cfg
[root@home /etc/tripwire]# twadmin --create-polfile --cfgfile tw.cfg --site-keyfile site.key twpol.txt
Please enter your site passphrase: XXXXXXXXXXXXXXXXXX
Wrote policy file: /etc/tripwire/tw.pol
[root@home /etc/tripwire]#
Do not leave the plain-text versions of the configuration and
policy files on your hard drive. Move them onto a floppy disk or
encrypt them using a utility such as GPG. Also ensure that the permissions of
the signed files are set such that they are only readable/writable by root:
[root@home /etc/tripwire]# chmod 0600 tw.cfg tw.pol
The last job we must do to complete the set-up is create the baseline database:
[root@home /etc/tripwire]# tripwire --init --cfgfile ./tw.cfg --polfile ./tw.pol \
--site-keyfile ./site.key --local-keyfile ./home.barryodonovan.com-local.key
Please enter your local passphrase:
Parsing policy file: /etc/tripwire/tw.pol
Generating the database...
*** Processing Unix File System ***
Wrote database file: /var/lib/tripwire/$HOSTNAME.twd
The database was successfully generated.
[root@home /etc/tripwire]#
[root@home /etc/tripwire]# tripwire --check Parsing policy file: /etc/tripwire/tw.pol *** Processing Unix File System *** Performing integrity check... Wrote report file: /var/lib/tripwire/report/$HOSTNAME-20040823-210750.twr ... ... ... Total objects scanned: 52387 Total violations found: 0
Each violation (an addition, removal or change) is reported to
stdout and written to the report file as indicated. On this
occasion I have assumed the default locations of the configuration and
policy files. I could have specified these explicitly on the command line
as I have been doing with switches such as --cfgfile, etc.
Your goal should be to set this up to run on a daily basis. This can be done as a cron or an Anacron job; Anacron is the better choice when the computer is not on 24/7. Using either cron or Anacron, the output should be e-mailed to the root user on each run of Tripwire.
In the case of Anacron, create a file in /etc/cron.daily/
called (for example) tripwire-check containing:
#!/bin/bash /usr/sbin/tripwire --check
and ensure that it is executable (chmod u+x
/etc/cron.daily/tripwire-check). If you want to use a cron job, then
add the following line to root's crontab to perform the check every day at
3am (crontab -e):
00 03 * * * /usr/sbin/tripwire --check
-I') or by using the database update mode
of the tripwire command:
[root@home /etc/tripwire]# tripwire --update --twrfile /var/lib/tripwire/report/$HOSTNAME-20040823-210750.twr
< At this point you will be asked to choose which file records to update in the >
< database via the ballot-box mechanism. Unless you specified otherwise, vi >
< will be the editor chosen. If you have not used vi before then I suggest you >
< change it to a pico, nedit or whatever you prefer. Add/remove the x's from >
< the ballot boxes, save and exit >
Please enter your local passphrase: XXXXXXXXXXXXXXX
Wrote database file: /var/lib/tripwire/home.barryodonovan.com.twd
[root@home /etc/tripwire]#
As you can see from the command line above, you must specify a report file to be used when updating the database. Choose the most recently generated report file. If you find yourself having to constantly update the same non-critical files, then feel free to update the policy so as to exclude those files.
If any changes are found you will be presented with a "ballot-box"
styled form that must be completed by placing an 'x' opposite the
violations that are safe to be updated in the database (for example you
updated the Apache web server yesterday and Tripwire is reporting a change in
the binary /usr/sbin/httpd as would be expected). If anything
has changed that you cannot directly account for then you should check it out
as it may indicate that someone has broken into your system.
tripwire command has a policy update mode which means that a
change in policy does not require us to reinitialise the database. The policy
update mode simply synchronises the existing database with the new policy file.
The new policy file expected is the plain-text version - Tripwire will then
ask for the local and site passphrases, synchronise the database and sign both
the new policy file and the database.
tripwire --update-policy --cfgfile ./tw.cfg --polfile ./tw.pol --site-keyfile ./site.key \
--local-keyfile ./$HOSTNAME-local.key new_policy_file.txt
Again, you should not leave the plain-text version of the policy file on the system.
-r-x------); as root execute: chmod 0500
/usr/sbin/tripwire /usr/sbin/twadmin /usr/sbin/twprint /usr/sbin/siggen
-rwx------) and similarly for
its contents; as root execute: chmod -R u=rwX,go-rwx /var/lib/tripwire
- the capital 'X' in the permissions sets the execute (or access if
a directory) bit if the file already has it set or if it is a directory.
The last procedure is something that I would consider a 'must' rather than a 'should'. Tripwire's database must be secure for an integrity check to be sufficiently trustworthy. If you are not updating the database on a regular occasion (such as on a server, etc) then you can keep the database on removable media without too much inconvenience. This can be as simple as leaving a write-protected floppy cantaining the database in the floppy drive, or a re-writable CD in a CD-ROM drive (read-only drive). If the database changes then you can update the database on these mediums by write-enabling the floppy or erasing and burning the new database to the CD-RW; but an attacker will be unable to remove or alter the database in anyway.
A second solution would be to keep the database on another machine and
download it as required. This could be as simple as using wget
to fetch the database from a web server just prior to running the integrity
check and removing it afterwards. For example, change the Anacron script to:
#!/bin/bash # switch to the database directory as specified by the Tripwire configuration file cd /var/lib/tripwire # download the database from a password protected directory (.htaccess) wget http://www.someserver.com/private/$HOSTNAME.twd --http-user=username --http-passwd=password # perform the integrity check /usr/sbin/tripwire --check # remove the database rm -f $HOSTNAME.twd
You can use scp, rsync, etc in a similar fashion.
TRIPWIRE(8) - (i.e. execute man 8 tripwire to
view this man page)
TWINTRO(8) - an introduction to Tripwire
TWADMIN(8)
TWPRINT(8)
SIGGEN(8)
TWCONFIG(8) - information on the Tripwire configuration file
TWPOLICY(8) - information on the Tripwire policy file
TWFILES(8) - information on the various Tripwire files
Barry has been using Linux since 1997 and his current flavor of choice
is Fedora Core. He is a member of the Irish
Linux Users Group. Whenever he's not doing his Ph.D. he can usually be
found supporting his finances by doing some work for Open Hosting, in the pub with friends or running in the local
park.
![[BIO]](../gx/authors/odonovan.jpg) Barry O'Donovan graduated from the National University of Ireland, Galway
with a B.Sc. (Hons) in computer science and mathematics. He is currently
completing a Ph.D. in computer science with the Information Hiding Laboratory, University
College Dublin, Ireland in the area of audio watermarking.
Barry O'Donovan graduated from the National University of Ireland, Galway
with a B.Sc. (Hons) in computer science and mathematics. He is currently
completing a Ph.D. in computer science with the Information Hiding Laboratory, University
College Dublin, Ireland in the area of audio watermarking.
For people who need to use both Windows and Linux, there has never been a better time to combine the two systems. Virtualisation software - software which creates a virtual PC - allows Windows users to run Linux without needing to reboot, or have a separate PC.
VMWare was the first program available which provided this capability, and is still the best known. Microsoft also has Virtual PC (formerly by Connectix), and there are open source solutions available: QEmu and Plex86.
The new version of Plex86 doesn't run on Windows yet, and is therefore outside the scope of this article. In fact, while the original version of Plex86 was designed to be similar to VMWare (the project was originally called FreeMWare), the new version does not perform dynamic translation, or emulate hardware (though as far as I can tell, this is included in Bochs, and Bochs combined with Plex86 provides the same sort of functionality as VMWare).
There is also coLinux, which is similar to User Mode Linux, but runs on Windows 2000 or XP. If this interests you, you might be interested in my article, Introducing coLinux, which can be read at Linux.com.
As I said, VMWare was the first well known piece of virtualisation software, and is still the best known. It is the best choice available for a number of reasons: it offers a greater choice of emulated hardware than VirtualPC or QEmu; it is easier to set up than QEmu; and it provides support for using Linux as a guest operating system, which neither VirtualPC nor QEmu do.
Installing VMWare is no more complicated than installing any other Windows program (though I've still provided step by step screen shots: 1, 2, 3, 4, 5, 6, 7).
Once VMWare is installed, you will want to set up your virtual machine. This is as simple as setting up VMWare itself; from VMWare's main screen, choose "New Virtual Machine" from the main screen (screenshot).
Again, I've provided step by step screenshots (1, 2, 3, 4, 5, 6.) In step 5 - "Network Type" - you'll probably want to leave it at the default ("Use bridged networking") if you are connected to a LAN. Since I use ADSL, which only allows access to one PC, I have chosen "Use network address translation (NAT)".
Step 6 - "Specify disk capacity" isn't really something you'll need to change - apart, perhaps, from the size of the disk. The "Allocate all disk space now" option perhaps requires some explanation - VMWare (and VirtualPC) use Copy on Write disks by default, so their disk images take up only slightly more than the actual amount of disk space required to hold all of their data. (It's worth mentioning here that both Bochs and QEmu have the ability to read VMWare's disk images).
Once you've completed these steps, you should have a blank virtual machine that's ready for use (screenshot). You are now ready to boot it up!
Well, not quite. You're ready to boot up if you have an installation disk in your computer's CD/DVD-ROM drive, but if you want to install from an ISO image, there's one thing you need to change. On the right hand side, there's a list of devices. Select the properties of the CD-ROM device - it'll give you a prompt like this. Click the "Browse" button to locate the ISO, and select it. You can now boot from the virtual image.
There was quite a big deal made when Microsoft bought Virtual PC from Connectix - many users were afraid that Microsoft would remove support for Linux. As this Newsforge story says, Microsoft has not removed support for running Linux on VirtualPC, but they aren't providing tools for Linux to allow you to drag and drop from Windows to Linux, as you can on VMWare with the VMWare tools installed. If memory serves, there was no such Linux support from Connectix either.
The nicest feature of VirtualPC is that all disk writes are copy on write by default - you are asked when shutting down the virtual machine whether or not you want to commit the changes to the main disk image. Other than that, though, VMWare is a better choice at the moment (and not just for Linux users).
Setting up VirtualPC is so similar to setting up VMWare that it's really not worth covering.
QEmu is the only open source virtualisation program currently available for Windows. QEmu has a special version which can run Linux (without process separation) a lot faster than any other virtualisation program, using kernel modules in the guest.
QEmu is slightly more difficult to use than VMWare or VirtualPC. It doesn't have wizards to create disk images for you, but there are plenty of pre-configured images available of various free operating systems available at FreeOSZoo.org.
If you're already familiar with Linux - especially if you're comfortable
with creating disk images using dd - then QEmu may be for you. Otherwise,
you might be better off trying out VMWare or VirtualPC (which are available for
30 and 45 day trials, respectively).
Since I'm running out of time, I'll save writing in depth about QEmu for a future article. Since QEmu also runs on Linux, it might be more fun to write from that perspective anyway :)
Jimmy has been using computers from the tender age of seven, when his father
inherited an Amstrad PCW8256. After a few brief flirtations with an Atari ST
and numerous versions of DOS and Windows, Jimmy was introduced to Linux in 1998
and hasn't looked back.
In his spare time, Jimmy likes to play guitar and read: not at the same time,
but the picks make handy bookmarks.
![[BIO]](../gx/2004/authors/oregan.jpg) Jimmy is a single father of one, who enjoys long walks... Oh, right.
Jimmy is a single father of one, who enjoys long walks... Oh, right.
LaTeX is a document preparation system based on Donald Knuth's TeX. LaTeX provides the facilities needed to typeset articles, books, and other documents. Kile is a KDE-based environment for editing LaTeX documents, which simplifies the process and provides easy access to commonly used commands and tags.
As well as offering short cuts to the various commands used to convert LaTeX documents, and to launch the viewers for these formats, Kile provides an output window, so you can view an errors which may have been present in your document, and an embedded Konsole window, so you can easily launch any other commands you wish without switching windows.
TeX is used by so many of the various documentation tools available for Linux that LaTeX is worth learning, if for no other reason than it's available almost everywhere. TeX (and, by extension, LaTeX) still has the best rendering available for mathematics, so if you ever plan to typeset a complicated formula, you would do well to learn it. LaTeX is being used by Project Gutenberg for mathematical books, and a subset of TeX's math syntax is used by Wikipedia.
If you've written HTML before, basic LaTeX shouldn't be too hard
to grasp. For example, text in italics is written like this
in HTML: <i>text in italics</i>; and like
this in LaTeX: \textit{text in italics}.
Now, there isn't much to be said about using Kile. Kile
is useful - it certainly saves a lot of time to be able to
select the tags you want from a menu. It also saves time to use the
document creation toolbar - the commands these tools invoke can be
summarized, left to right (see below), as follows:

Note that Kile uses pdflatex. This, in my opinion, is not the best way to generate a PDF file from LaTeX. In my experience, pdflatex has failed to include images. My preferred way to generate PDF files (using an article about SuperKaramba that I never got around to finishing as an example) is:
latex sk.tex dvips sk.dvi -o sk.ps ps2pdf sk.ps sk.pdf
Kile is a KDE application, so starting a new document is done
the same way as with any other KDE application:
File->New, or Ctrl-N. Kile offers a
choice of "Empty Document", "Article", "Book", "Letter", or
"Report". I'll presume you want to use "Article" - I'll be using
(parts of) this article as an example - but it shouldn't be too
difficult to use the other templates.
\documentclass[a4paper,10pt]{article}
%opening
\title{}
\author{}
\begin{document}
\maketitle
\begin{abstract}
\end{abstract}
\section{}
\end{document}
Not too scary, I'm sure you'll agree! Most basic commands have
the same formula: \command{parameter}. There are some
differences, like \maketitle, but it's true for most
of the common commands. Filling this out looks like this:
\documentclass[a4paper,10pt]{article}
\usepackage{hyperref}
%opening
\title{Front and Back: Kile and LaTeX}
\author{Jimmy O'Regan}
\begin{document}
\maketitle
\begin{abstract}
Kile is a user-friendly frontend to \LaTeX{}. This article discusses using
Kile, and using \LaTeX{} without it.
\end{abstract}
\section{Introduction}
\href{http://www.latex-project.org/}{\LaTeX{}} is a document preparation
system based on Donald Knuth's \TeX{}. \LaTeX{} provides the facilities needed
to write articles, books, and other documents.
\href{http://kile.sourceforge.net}{Kile} is a KDE-based environment for editing
LaTeX documents, which simplifies the process and provides easy access to
commonly used commands and tags.
Note the \usepackage{hyperref} line: this tells
LaTeX to use the hyperref package, which adds some extra commands
for Web links (I use it for the \href{}{} command).
One difference between HTML and LaTeX is that LaTeX does not
require a command for a new paragraph; you simply leave a blank
line between paragraphs, and LaTeX figures it out. LaTeX has a
number of special characters which HTML doesn't: most of these can
be used by escaping them with a backslash ('\'), but the backslash
itself must be inserted as $\backslash$, because a
double backslash ('\\') is used to force a line break. Here is a
table of some common HTML tags and their LaTeX equivalents:
| HTML | LaTeX | |
|---|---|---|
| Italics | <i>Italics</i> | \textit{Italics} |
| Bold | <b>Bold</b> | \textbf{Bold} |
| Typewriter | <tt>Type</tt> | \texttt{Type} |
| Hyperlink | <a href="http://">text</a> | \href{text}{http://} |
| Heading | <h1>Heading</h1> | \section{Heading} |
| Subheading | <h2>Subheading</h2> | \subsection{Subheading} |
| < | < | $<$ |
| > | > | $>$ |
| & | & | \& |
More complicated things in LaTeX are done in different environments - these commands look like this:
\begin{environment}
...
\end{environment}
Kile helpfully fills in the \end{} part for you
automatically, after a blank line. It's a small time saver, but it
is useful.
Most of these environments can have a \label{}
tag attached, which allows you to set a description which "follows"
the environment. This
file contains an example of the use of the label tag, attached
to a verbatim environment.
Different lists are available as environments, for example;
<ol> in HTML translates to
\begin{enumerate}, and <ul>
translates to \begin{itemize}. The \item
tag is used in place of <li>. This list:
Looks like this:
\begin{enumerate}
\item First
\item Second
\end{enumerate}
Another common HTML equivalent is the "verbatim" environment in
place of the <pre> tag. The "verbatim" environment is
different to HTML's "pre" tag though; HTML elements must be
escaped, whereas in the "verbatim" environment all processing stops
until the \end{verbatim} tag, so nothing need be
escaped.
Because LaTeX is a document preparation system, it has quite a
few commands which have no equivalents in HTML, but which are
useful for creating documents such as books. Tags such as
\chapter{} are self explanatory; one thing which might
provide a little confusion is the use of footnotes.
While in the paragraph environment, a footnote can be inserted
by simply adding \footnote{Text of footnote}. In other
environments, however, you have to use the
\footnotemark tag while inside the environment,
followed by the \footnotetext{Text of the footnote}
when you're outside of that environment. So, if you wanted to add a
footnote inside a footnote (if you're a Terry Pratchett fan, you'll
understand!), it would look like this:
Here you would have your text, as usual\footnote{Or as unusual\footnotemark}.
You can then continue your paragraph text.
\footnotetext{At least I hope you find footnotes within footnotes unusual}
(This file, a version of my RDF article from last month, contains an example of the use of a footnote).
LaTeX supports most modern languages. The most commonly needed symbols (in my part of the world, at least) are the letters of the Greek alphabet, and the various symbols used in the Latin alphabet, such as the umlaut or acute.
Kile helpfully provides a sidepane for Greek, and another with many of the Latin symbols. Here's another table of some symbols, with their HTML and LaTeX equivalents:
| HTML | LaTeX | |
|---|---|---|
| α | α | \alpha |
| ä | ä | \"a |
| é | é | \'e |
| Æ | Æ | \AE{} |
| Ç | Ç | \c{C} |
| ù | ù | \`u |
| ô | ô | \^o |
| ñ | ñ | \~n |
| ß | ß | \ss{} |
| œ | œ | \oe{} |
| å | ˚ | \aa{} |
| ø | ø | \o{} |
I sometimes proofread for Distributed
Proofreaders, where from time to time there are books which use
odd things such as an AE ligature with an acute
(\'\AE{}). One book that was recently posted is JUAN
MASILI Ó Ang pinuno n~g tulisán, which is in old
Tagalog. Old Tagalog uses a g with a tilde. HTML doesn't support
this, but LaTeX does: \~g. There are many, many
strange characters available for use in LaTeX - so many, that I'm
not going to go looking for them all (well... that, and
laziness).
It's probably better to show an example of a table than to try to talk about it too much:
\begin{tabular}{rcl}
1 & 2 & 3 \\
4 & 5 & 6
\end{tabular}
The {rcl} means that there are three columns in
this table, the first is right aligned, second is
centred, and the third is left aligned. Each column
is separated with an ampersand (&); each row is
separated with a newline (\\). The row and column
separation used in tables is also used in similar environments,
such as matrices and equations, so it's important to know how to
use tables if you want to typeset complicated equations in LaTeX.
Let's look at part of the first table, formatted for LaTeX:
\begin{tabular}{cll}
& HTML & \LaTeX{} \\
Italics & $<$i$>$ & $\backslash$textit\{Italics\} \\
Bold & $<$b$>$Bold$<$/b$>$ & $\backslash$textbf\{Bold\} \\
Hyperlink & $<$a href="http://"$>$text$<$/a$>$ & $\backslash$href\{text\}\{http://\} \\
$<$ & \< & \$$<$\$ \\
$>$ & \> & \$$>$\$ \\
\& & \& & $\backslash$\&
\end{tabular}
(And maybe now you see why I didn't redo this whole article as an example, as I had originally intended!)
I mentioned that LaTeX is the typesetting system for mathematics... I also don't want to get into it too deeply, as typesetting mathematical equations in LaTeX is a topic worthy of a book, not an article.
In general, simple maths can be included by enclosing them within dollar signs:
$2 + 2 = 4$This might explain why certain things, such as the "less than" (<) and "greater than" (>) symbols need to be surrounded by dollar signs. LaTeX also allows you to use the "proper" multiplication and division symbols:
$x = 2 \times 3 \div y$Lets look at an image and the LaTeX used to generate it:
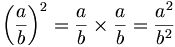
\left(\frac{a}{b}\right)^2 = \frac{a}{b} \times \frac{a}{b} = \frac{a^2}{b^2}
Here we have large parentheses (\left(,
\right)), fractions (\frac{}{}), and
simple superscripts (a^2). To use more than a single
character in a superscript or subscript (_), they are
enclosed with braces: a^{13 + 2}_{4 - 6}. (This
example is taken from A First Book in
Algebra, which was recently posted to Project Gutenberg. If you
want to learn about typesetting mathematics with LaTeX, have a look at the
source of this book).
Let's look at a simple array. As I mentioned earlier, many of the mathematical environments are special cases of tables:
\begin{array}{cc}
3 & 4 \\
4 & 5
\end{array}
Another example is an equation array, which is used to align a
formula, normally to the 'equals' symbol (the convention is to
write this as &=&, to show the alignment more
clearly):
\begin{eqnarray}
a &=& 5 + 6 \\
b + 6 - 3 &=& 2 - a
\end{eqnarray}
This is almost the same as this table, except the equation is centred, and each line is numbered:
\begin{tabular}{rcl}
a &=& 5 + 6 \\
b + 6 - 3 &=& 2 - a
\end{tabular}
LaTeX is a powerful text formatting language, and I've barely covered the tip of the iceberg in this article. Kile is a great tool to assist your use of LaTeX (though I've hardly covered it at all) - it can really save you time remembering which environment you need by offering them from a menu, and for those new to LaTeX, it can be a godsend.
If you don't want to edit LaTeX by yourself, there are tools available which will generate LaTeX from other formats. html2latex, for example, converts HTML to LaTeX, and this site converts Wikipedia articles to LaTeX. (Example).
Jimmy has been using computers from the tender age of seven, when his father
inherited an Amstrad PCW8256. After a few brief flirtations with an Atari ST
and numerous versions of DOS and Windows, Jimmy was introduced to Linux in 1998
and hasn't looked back.
In his spare time, Jimmy likes to play guitar and read: not at the same time,
but the picks make handy bookmarks.
Jimmy is a single father of one, who enjoys long walks... Oh, right.
Last month, I wrote about RDF and the Semantic Web and included a sample FOAF file... that wasn't even valid XML. The worst part of it is, I had a fixed version ready just before publication, but it was too late for publication (partly because, in a sleep deprived haze, I managed to make a mess of the stuff that was there, and Ben had to go with an earlier version). The corrected version is here.
As well as that, Frank Manola (co-editor of the RDF Primer) wrote to make a correction:
I couldn't help commenting on your statement: "Each RDF statement is called a "triple", meaning it consists of three parts: subject, predicate, and object; the subject is either an RDF URI, or a blank node (I haven't seen a good explanation why these nodes are "blank", so I'll just refer to them as nodes). "I guess the Primer didn't make the connection explicit enough. Under Figure 6 in the RDF Primer, the text says "Figure 6, which is a perfectly good RDF graph, uses a node without a URIref to stand for the concept of "John Smith's address". This blank node..." The intent was to indicate that a blank node was one without a URIref. In the figure, the blank node is an ellipse with no label, i.e., "blank". The term "nodes" without qualification refers to all those parts of graphs that aren't arcs, including URIrefs, literals, and blank nodes (see the discussion of the graph model in Section 2.2 of the Primer, or Section 3.1 of RDF Concepts and Abstract Syntax).
I also wrote about RSS last month. In the meantime, I found this page, which explains that there are 9 different versions of RSS. Maybe Atom is a better idea than I had thought!
This is more of a "2 Cent Tip" than anything else, but I've found that a lot of people are unaware that XML can use CSS stylesheets, and that "modern" browsers are able to render this.
To include a stylesheet, just add a line like this to your XML file:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet href="xml-style.css"?>
After that, it's CSS as usual -- the only thing that's different is the tag names.
One nice thing about this is that if you add a stylesheet to your feed files, people can get an idea of what it'll look like in their feed reader if they choose to subscribe to it.
A drawback, especially with feeds, is that there are various ways of representing embedded HTML/XHTML. "Escaped" HTML in particular looks terrible. Because of the various ways Blogger allows people to post to their blogs, my Blogger Atom feed shows both how nice and how horrible this can look.
That aside, though, for an XML file you're generating, and have complete control over, stylesheets can make the difference (and can spare you from having to learn XSL!).
Most Linux users know and love the fortune command, and use it regularly to get a dose of humour, wisdom, or silliness. Now, thanks to A.M. Kuchling's Quotation Exchange Language, it's possible to write your fortunes in XML.
Even if you're not the sort of person who wants to convert everything into XML, QEL has a lot going for it. For one thing, it can generate both standard fortune files and nice HTML. For another, it's politically correct regarding metadata (it'd be a terrible waste of XML if it wasn't, but that hasn't stopped anyone before).
A simple quote in QEL would look something like this:
<quotation> <p> So, throughout life, our worst weaknesses and meannesses are usually committed for the sake of the people whom we most despise. </p> <author>Charles Dickens</author> <source><cite>Great Expectations</cite></source> </quotation>
With a little bit of wrapping, to make valid XML of it, it would look like this:
<?xml version="1.0" encoding="UTF-8"?> <quotations> <quotation> <p> So, throughout life, our worst weaknesses and meannesses are usually committed for the sake of the people whom we most despise. </p> <author>Charles Dickens</author> <source><cite>Great Expectations</cite></source> </quotation> </quotations>
Using the qtformat tool, which is part of the quotation tools the creator of QEL provides here, we get this (qtformat -f for fortune format):
So, throughout life, our worst weaknesses and meannesses are usually
committed for the sake of the people whom we most despise.
-- Charles Dickens, _Great Expectations_
%
As I am in the habit of writing about everything I spend more than 10 minutes doing, I, of course, have a prepared example. Again, this uses CSS, so if you have a browser capable of rendering XML, you can see my quotes file nicely laid out. (Otherwise, you'll see the usual XML gibberish -- sorry 'bout that!). Check it out here
I spent longer than usual using Windows this month, and so started using a Windows-based feed reader. Called FeedReader. (Kudos for using the "Principle of least surprise" in their naming).
While most feed readers I've encountered support exporting their feed list as OPML, FeedReader doesn't. It does, however, keep its list of feeds in a simple XML file. So, after a quick stumble through the basics of XSL, I managed to whip together something that converted the list FeedReader keeps into OPML.
This is a simple example of a FeedReader file (normally kept in [windows mount point]/Documents\ and\ Settings/Owner/Application\ Data/FeedReader/):
<feeds>
<item>
<feedid>63219889590821</feedid>
<title>Linux Gazette</title>
<description>An e-zine dedicated to making Linux just a
little
bit more fun.
Published the first day of every month.</description>
<feedtype>http</feedtype>
<archivesize>8888</archivesize>
<alwaysshowlink>0</alwaysshowlink>
<htmlurl>http://linuxgazette.net</htmlurl>
<image>http://linuxgazette.net/gx/2004/newlogo-blank-100-gold2.jpg</image>
<read>0</read>
<unreadcount>17</unreadcount>
<updateperiod>14</updateperiod>
<LastModified>Fri, 02 Jul 2004 16:42:16
GMT</LastModified>
<link>http://linuxgazette.net/lg.rss</link>
<username></username>
<password></password>
</item>
</feeds>
I don't care about most of this information -- all I want are the
contents of the <title>,
<description>, <htmlurl>, and
<link> tags, so I can have a simple XSL file (Text version):
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<opml version="1.0">
<head>
<title>FeedReader Subscriptions</title>
</head>
<body>
<xsl:apply-templates select="//item"/>
</body>
</opml>
</xsl:template>
<xsl:template match="item">
<xsl:variable name="title" select="title"/>
<xsl:variable name="desc" select="description"/>
<xsl:variable name="site" select="htmlurl"/>
<xsl:variable name="link" select="link"/>
<outline title="{$title}" description="{$desc}" xmlUrl="{$link}"
htmlUrl="{$site}"/>
</xsl:template>
</xsl:stylesheet>
<xsl:template match="/"> matches the top-level
element; I use this to output some header information (in this example,
anything that doesn't start with xsl: is output).
xsl:apply-template tells the XSL processor to apply the
second template on each matching line -- in this case, I have
<xsl:apply-templates select="//item"/>, so it selects
any second level element called <item>. If I wanted to
be more accurate, I'd use <xsl:apply-templates
select="/feeds/item"/>, so it would only match
<item> tags within <feeds> tags.
The xsl:variable lines create a variable based on the
contents of the subtags named in the select attribute, and
then used to create my output.
If you want to find out more about XSL, LG had a good article in issue 89: Working with XSLT. XSL is a huge topic, and one I think I'll be using more of.
Jimmy has been using computers from the tender age of seven, when his father
inherited an Amstrad PCW8256. After a few brief flirtations with an Atari ST
and numerous versions of DOS and Windows, Jimmy was introduced to Linux in 1998
and hasn't looked back.
In his spare time, Jimmy likes to play guitar and read: not at the same time,
but the picks make handy bookmarks.
Jimmy is a single father of one, who enjoys long walks... Oh, right.
As I said in the #102 Mailbag, I've been wanting to try Gentoo. I hesitated to install it because I knew it would take three days since you have to compile your own software, and I assumed I would have lots of compilation errors to troubleshoot. But four of my friends have been running it at their workplaces and say they rarely get compilation errors -- mirable dictu. Three of them are solidly convinced for Gentoo; the other is a little tired of having to wait for a package to compile. But everyone says you just run "emerge PACKAGE" in a shell window and leave it alone, and 90% of the time you end up with a flawlessly installed package. No mess, no fuss, just pure impact. The way Unix was meant to be. This article describes my experience installing Gentoo, some things I learned along the way, and describes the Gentoo features I found the most interesting.
Gentoo brings the concept of BSD ports to Linux. Most Linux distros consist of precompiled binary packages in .rpm or .deb format. Gentoo consists of text configuration files ("ebuilds") that tell the package manager where to download the upstream source from, which patches to apply, and how to compile and install it. The package manager is called Portage (anchors away!), and its command-line tool is emerge. Of course, Debian and Red Hat have similar configuration files, otherwise how could the developers maintain the packages? And emerge does have the ability to install a precompiled package. So the difference between them is less about capability than about cultural emphasis -- and about whether the distros carry binary packages on their mirrors. Gentoo is not the first "compile your own" distro; I installed Rock Linux a couple years ago. But Gentoo has enough documentation and support now for me to actually use it as my desktop, and Rock didn't at the time.
The appeal of compiling software is not to be studly and say I did, but to eliminate a layer of potential problems. Compile-it-yourself distributions usually leave packages close to the upstream's default, compared with the heavy tweaking in some other distros. Debian's build process is so complicated you often get packages in the Unstable distribution that depend on themselves or on something that's not available. Fixing those requires you to second guess both the upstream developer and the package maintainer -- at which point it's often easier just to do a /usr/local/ install. Unless it's a library that other stuff depends on; then you have to deal with dependencies again. Or install those things locally too.
Speaking of dependencies, one of Portage's novel features is USE flags. USE flags are direction from the local sysadmin (me and you) to the package manager about how to handle optional dependencies. This doesn't affect mandatory dependencies (e.g., the GIMP needs Gtk to run), but many programs come with extra utilities or front ends or libraries that depend on third-party stuff, even though the program as a whole does not depend on them.
For instance, a non-interactive daemon may come with a Gnome configuration dialog. Say you hate Gnome and don't want any gnomy things on your system. Other distributions don't have optional dependencies so they have to split the program into 'software' and 'software-gnome' packages. But Gentoo allows you to set a variable in /etc/make.conf specifying which optional stuff you want. For instance,
USE="kde -gnome qt gtk gtk2 -crypt"tells Portage not to install any optional components that require Gnome or encryption dependencies, but to install any other Gtk extensions. "gtk2" means we prefer the Gtk2 library over Gtk1 if the program can be built either way. And you'll want "mysql" in your USE string if you want to build Postfix with the ability to access MySQL tables for virtual users, domains, and the like.
Now say you want to install links but you haven't installed X yet. That's a problem because links has X11 extensions, and since the "X" USE flag is on by default, "emerge links" will install all of X if you don't watch what you're doing. So you set an environment variable to override the USE flag this one time:
USE="-X" emerge linksLater, after you've installed X, you simply "emerge links" again, and it will rebuild itself with the X support.
Also in /etc/make.conf is the variable you configure to instruct Gentoo to build packages to match and make use of the advanced capabilities of your processor. There's a line that starts "CFLAGS =", that's where the work is done. There are a couple of decent examples right there in the make.conf file, and a whole sub-web devoted to configuring good CFLAGS settings over at Freehackers.org. The settings recommended there for my first two Gentoo machines are:
CFLAGS="-march=pentium3 -O3 -pipe -fomit-frame-pointer"
CFLAGS="-march=k6 -O3 -pipe -fomit-frame-pointer"
The first thing I did was to print out the the ninety-page Gentoo Linux/x86 Handbook and read it several times. The Handbook does a good job of predicting what issues you might be concerned about at each step. Gentoo 2004.2 had just come out, but my CD was 2004.1. But the website reassured me that after "emerge system" I would be completely up to date, so I decided to go with the install that had worked on my friend's machine.
But first I had to shrink my NT partition. This was a work computer so I couldn't just get rid of Windows completely. I borrowed PartitionMagic but the version was too old to deal with the current NTFS partitions. I googled and found ntfsresize. It's a bit scary though because ntfsresize only shrinks the filesystem; you then have to delete the partition with fdisk and recreate it with the new size. There's also an ominous warning about getting the cylinder numbers right: if you make the NTFS partition too small, Windows wouldn't boot. I googled some more and found qtParted, a graphical program that handles both parts. Then I found a System Rescue CD that includes qtParted. I figured a rescue disk is always a good thing to have on hand anyway, and I was doubly impressed that it's Gentoo based. The Gentoo install disk is also a rescue CD, but this one has better hardware support and a wider selection of utilities. I availed myself of the hardware detection by watching the boot messages to see which drivers I'd need. Then I ran qtParted without a hitch, created my Linux partitions, and began the install. I wrote down every command I issued in case I had to do it again.
I opted for a stage 3 install, meaning I unpacked a tarball that contains a text-based developer's environment with the standard gcc tools precompiled (and Python, which Portage uses internally). If I wanted to be studlier I could have started at stage 1 where you do absolutely everything from scratch: first compiling a bootstrapper, then gcc, etc. But I didn't want to spend an extra day doing that.
The CD contained the following stage tarballs:
% ls /mnt/cdrom/stages stage1-x86-2004.1.tar.bz2 stage3-pentium3-2004.1.tar.bz2 stage3-athlon-xp-2004.1.tar.bz2 stage3-pentium4-2004.1.tar.bz2 stage3-i686-2004.1.tar.bz2 stage3-x86-2004.1.tar.bz2The computer is a Pentium III at 1 GHz so it was an obvious choice. But it took me quite a while to figure out which tarball to choose for my home computer (AMD K6 Duron at 450 MHz), and there was no compatibility list. I set it up as i686, then read somewhere on the Gentoo site that AMD Durons are i586, and since there wasn't a tarball for that I had to reluctantly re-set it up with the x86 tarball. But I haven't had the time to actually boot it and finish the install.
The biggest thing I was concerned about on the Pentium III was the nVidia video chip. The Answer Gang is constantly getting questions from people who have this chip and can't get their video to work, and you have to go to the nVidia site, find, download and install the politically incorrect binary-only kernel driver. But here I just ran "emerge nvidia-kernel" as the Handbook said and it worked. However, after I updated to the current ebuilds, nvidia-kernel would no longer compile. That's OK though because the old one is still working.
You have a choice of four kernel sources; I chose 2.6.5 with the Gentoo tweaks. You then have a choice to compile it manually or with genkernel. Genkernel creates a kernel with an initrd that does the same hardware detection as the install disk. I tried that first but for some reason it wouldn't create the initrd file. I f*cked around with it for a while and finally just built my own kernel, which went without a hitch. Grub also installed itself smoothly.
Gentoo comes with an initial set of binary packages so you can install KDE and OpenOffice without huge downloads, 1.5 GB free disk space, and an extra day to compile. But I didn't have the disk with those packages, so I just "emerge sync"'d to get the current set of ebuilds and let it run overnight. One night to update the existing installed packages ("emerge world"), and one night for X. I was going to be studly about that and install X.org instead of xfree86. That went OK although the graphical configurator wouldn't work with my system so I had to use the text configurator.
A week after I finished that, my boss told me I was getting a new computer. It's a screamin' Pentium IV black beauty at 2.6 GHz, twice as fast as any other computer I've ever used. Kernel compiles now take two minutes. Fortunately I had written down the commands I had used to install, so I was able to mostly follow them.
This computer has an Intel i810 video chipset. I assumed anything would be better than the nVidia. Wrong. I had to boot the non-framebuffer kernel on the CD in order to install, and it seemed to ignore the VGA mode so I couldn't get the text console above 80x24. Likewise, I couldn't make an X configuration that would go above 640x480; it kept on saying mode "1024x768" doesn't exist even though it's supposed to be a standard VESA mode built into X 4. Googling found contradictory advice, including one message saying i810 isn't supported very well on Linux, and an apparently obsolete HOWTO on Intel's site. Finally I stole a 3dfx (Voodoo) PCI card from an unused computer. That one still took a while to configure but I finally got it up to 1280x1024. Then I moved it down to 1152x864 because that looks better on my 19" monitor. But I still can't get the text screen better than 80x24, and I'm not sure about the framebuffer. Curiously, the BIOS doesn't have an option to disable the i810 chip, you can only set it to "on" or "auto". Leaving it at "auto" makes the PCI card the main one (card 0) and the i810 the secondary (card 1), but both are active. In /etc/X11/xorg.conf you tell it which card and monitor to use. In Windows it assumes you have monitors connected to both cards (I don't) and you want the desktop to span both monitors (so each monitor shows half). The "Monitors" control panel has controls to ignore one card or make it primary. These all work fine although it's disconcerning when the screen suddenly goes dark or the taskbar disappears onto the other screen as you change the settings (because Windows assumes you have a second monitor connected to the other card, which I don't). I hate to say it, but it was easier to configure the two cards in Windows than Linux.
KDE 3.3 came out the day before I did this install, but for some reason it's still in the "masked" section in Gentoo (meaning Unstable), so I'm sticking with 3.2 for now.
Printing was a breeze to set up once I found the Printing HOWTO on the Gentoo site. I had to connect to an HP LaserJet 8000 using IPP (Internet Print Protocol) over TCP/IP. LinuxPrinting.org provided a prebuilt driver, and the Printing HOWTO told me which directory to put it in so CUPS would see it.
The main thing I can't get to work is smbfs. Our shared files are kept on an NT server. My colleague who has Gentoo can do it using Konqueror or this command:
mount -t smbfs //SERVER/directory /mnt/smb -o "ip=111.222.333.444,username=USER%PASSWORD,workgroup=WORKGROUP,fmask=666,dmask=000"
... but for me although I connect without error, "ls /mnt/smb" says permission denied, and "ls /mnt" doesn't even show "smb" while it's mounted. I tried several variations of the network directory and username, with and without the fmask/dmask, but nothing has worked. So I still have to switch to Windows to save my backups to the network, and to run a Java applet that won't run in Firefox or Galeon.
I made a DOS partition to share files between Linux and Windows. That works although it's sometimes surprising when permissions don't work the way you expect, even though you've known about that for years. You set the permissions in the mount command. I finally gave them all permission for all users so I wouldn't have to fuss with them any more.
Here's the non-default packages I've felt the need to install so far:
Gentoo's package query tools (equery and qpkg) aren't complete. They'll list the files a package contains but several other features are marked "not implemented". There didn't seem to be a way to quickly see which version of a package is installed: something equivalent to "rpm PACKAGE" or "dpkg -l PACKAGE". "emerge search PACKAGE" does it, but it takes several seconds, and you have to page through other information and entries for any other packages the substring matches. After a fair bit of trial and error, I found that qpkg can show me the information, but it doesn't take concatenated flags, so I had to type "qpkg -i -I PACKAGE", where -i gets me package info, and -I limits the list to installed packages only. By the way, "emerge info PACKAGE" does not do what you expect. I'd expect it to give extended information about the package à la "dpkg -s PACKAGE", but instead it reports on your installation environment; e.g., which USE flags are in effect.
It's bloody hard to figure out which package you need if you don't know the name. I wish Gentoo had a webpage similar to packages.debian.org you could search. In fact, I still use packages.debian.org to figure out which Gentoo packages I want! The biggest problems I had were finding the package for mkfs.vfat (dosfstools) and host/dig/nslookup (bind-tools). I needed the former to make my DOS filesystem. Finally I found a couple messages in the Gentoo forums with the name of the package, showing that several other people have had the same problem.
"emerge search"'s package descriptions are one-liners rather than the paragraph(s) Debian provides at the web site or via "apt-cache search PACKAGE". The missing info is stuff I want to know to decide whether to install the package.
Gentoo-specific package documentation also seems to be missing -- equivalent to /usr/share/doc/PACKAGE/README.Debian . One would like a file describing the Gentoo way to configure and use the package, especially since Gentoo's configuration framework is different from other distributions. The framework looks impressively flexible; many packages have a separate file for local overrides, so the standard configuration file can be upgraded without stomping on anything. The overrides are almost invariably in the form of variable definitions. To enable SSL and PHP in Apache2, no need to edit the config file, just set:
APACHE2_OPTS="-D SSL -D PHP"... in /etc/conf.d/apache2 . The trouble is, if you forget where to set what, there's a lot of places to look for it: /etc/conf.d/*, /etc/rc, /etc/make.conf, /etc/profile, and there may be more that slip my mind. This is where a README.Gentoo file would come in useful. The init.d scripts are different from other distributions', although they're robust. "rc-update show default" shows which services are set to start at boot, and "rc-update add PACKAGE default" adds it. When an init.d service fails to start, check /var/log/*! That's true for any distro, but I find it quite useful on Gentoo since packages have no README.Gentoo to guide you. Somewhere I set kdm to shutdown when I log out rather than presenting the login dialog. Now I want to change it but darned if I can find the setting.
Another thing I haven't figured out is how to compile a package with different ./configure options than the maintainer set, or how to install a development version that Gentoo doesn't have. I need to reinstall PHP with the msysqli option (an object-oriented MySQL library). I finally found a USE flag called, unsurprisingly, "mysqli", but the general problem remains. Also, I often use alpha versions of Python, which I put in /usr/local now but I'd like to install them like Gentoo packages. I assume I just have to sit down and figure out how to customize ebuilds, and where to put them so they don't get deleted at the next "emerge sync". There's also a nifty "emerge inject PACKAGE" feature that tells Portage you've installed something locally that's the equivalent of PACKAGE. I haven't used it yet but it certainly sounds a lot easier than dpkg-equivs.
For those with lots of disk space but little time, "emerge ccache" sets up a compilation cache that saves intermediate files so you don't have to regenerate them. There's also a distcc package for replicating installs in a network, although I haven't used it.
Although I've found a bunch of little shortcomings in Gentoo, it's still my favorite distro because it has so much potential. Eventually the gaps will be filled, and the lightweight layer they add to packages ensures that upstream versions are quickly ported to Gentoo because there's not much overhead to get in the way.
 Mike is a Contributing Editor at Linux Gazette. He has been a
Linux enthusiast since 1991, a Debian user since 1995, and now Gentoo.
His favorite tool for programming is Python. Non-computer interests include
martial arts, wrestling, ska and oi! and ambient music, and the international
language Esperanto. He's been known to listen to Dvorak, Schubert,
Mendelssohn, and Khachaturian too.
Mike is a Contributing Editor at Linux Gazette. He has been a
Linux enthusiast since 1991, a Debian user since 1995, and now Gentoo.
His favorite tool for programming is Python. Non-computer interests include
martial arts, wrestling, ska and oi! and ambient music, and the international
language Esperanto. He's been known to listen to Dvorak, Schubert,
Mendelssohn, and Khachaturian too.
By Amber Pawar
Anyone who studies the Internet or �Computer Networks� in general comes across some of the RFC�s, which describes the networking protocols and the standards. Many people think that the RFC�s are amongst the most boring documents to read. I know a person who uses RFC�s as a substitute for sleeping pills.
This article is an attempt to change this deadly-boring image of the RFC�s. In this article I give a brief definition of the RFC, followed by an informal classification of the RFC�s. Then the major section contains comments on some of the most interesting RFC�s that I have found. You will find that this article is about the lighter side of the RFC�s.
RFC�s (an acronym for Request For Comments) are the working notes of the Internet research and development community. They contain the description of protocols, systems, and procedures for Internet, or simply reviews, experiments, or information on some topic. All the Internet�s standard protocols are written up as RFC�s.
The RFC�s are in the form of a series of documents, each identified by a unique number. The first RFC was written in 1969. Now there are well over 3800 RFC�s today, and the number is growing. An RFC is for forever. Once published, they can never be changed or modified in anyway. If there is an error in the RFC, then a revised RFC is published that obsoletes the one with the error.
An RFC can be submitted by anyone, Eventually, if it gains enough interest, it may evolve into a standard.
The home page for all RFC�s is here: http://www.ietf.org/rfc.html
Based on their contents the RFC�s can be broadly classified in the following categories.
These documents either specify an Internet standard or a draft of it. These include the official standards for the Internet protocols, defined by the IETF.
These documents describe the Best Current Practices for the Internet Community. They are guidelines and recommendations, but not standards, from the IETF.
The informational RFC�s or the FYIs (For Your Information) documents are a series of the RFC�s that are of particular interest to Internet users.
These are former standards that have been actively deprecated or they are obsolete.
Every year (since 1978) on 1st of April (Fools day), one or more unusual sort of RFC is published. They are amongst the most interesting ones. They are humorous documents sometimes written in very formal way, which makes it hard to differentiate them from the serious stuff. The next section of this article includes a brief description of some of these RFC�s.
Here�s a brief description of some of the interesting RFC�s that I discovered. This include poetries, facts, recommendations, and April 1st RFC�s.
Many of us have been using foo, bar, and foobar as names of absolutely anything, without thinking much about where these names came from. Many of the code samples that we see have filenames or functions named foo, bar or foobar. Over 200 RFC�s have used these words without properly defining them.
A look at the RFC 3092 will tell you the Etymology of �foo�. The RFC reveals half a dozen definitions of the word foo. The RFC gives many traces of origin of word foobar, including comic strips. It reveals that the word foobar is generally traced back to World War II era Army slang, FUBAR, which it seems, was itself derived from German word furchtbar meaning terrible.
Yes, this RFC gives some nice tips on how to better name your Computer. It�s not exactly like the books on choosing names for your babies. The RFC describes in detail what makes a name good or bad, and what things you should consider before naming your computer. The tips include the appropriate length and spelling of name. This RFC is fun to read. The line that caught my eye was the line before the conclusion: �I could go on but it would be easier just to forget this guideline exists.�
This RFC describes the standard for transmission of data on avian carriers, aka birds (pigeons to be specific); although the RFC never uses the latter words. The RFC very formally describes the whole process, from printing the data on paper, to wrapping the piece of paper around the bird�s leg with a duct tape, to removing it at the receiver end. The RFC also mentions that the carrier has got intrinsic collision avoidance system. This is a good RFC to read when you want to know the extreme limits of people's thinking.
This RFC amends the above RFC (1149). It is far more technical in content in comparison to RFC 1149. It goes a step further and explains how the quality of transmission depends on the carrier used. It suggests the use of Ostriches for bulk data transfers, which have a small limitation that they need a real bridge between the domains. With nice ASCII art figure of a bird on scale, it tells that even Weighted Fair Queuing (WFQ) can be implemented. This RFC even defines its own MIB.
This is an April 1st RFC. This RFC defines a security flag, known as the �evil� bit in the IPv4 header. This �evil� bit is to be used to distinguish good packets from the packets with the evil-intent. The RFC describes that the programs should set the �evil� bit to 1 when the packet has evil intent, otherwise the bit should be set to 0.
Another April 1st RFC, this one reveals literary aspect of data transmission technology. It talks about translation of a SONET (Synchronous Optical NETwork) packets to SONNET (SONET Over Novel English Translation). This RFC describes how a 9x90 bytes SONET OC1 frames can be translated to fourteen line decasyllabic English sonnets. Coincidently this RFC�s author shares his name with one of the world's most read authors, William Shakespeare.
Everyone is well aware of the Y2K bug that haunted many COBOL programmers for a long time. The Y2K bug came because of the shortsightedness of the programmers who wrote programs that would fail in the year 2000. The fixes for the Y2K problem were again shortsighted. These programs are again written to fail, this time in the year 10,000. This RFC provides a solution to the Y10K problem. Y10K is also known as the �YAK� problem, as the hex equivalent of 10 is A, or the �YXK� problem, as X is the Roman numeral for 10.
If you think you know a lot (if not everything) about the Networking, then you may like to verify these twelve Networking truths. These truths seems to be very illuminating and enlightening, most especially the one which talks about the flying pigs.
Some people might feel that truth number 2's corollary and truth number 3 are a bit contradictory. But if you read carefully, you will realize that truth number 2 is all about time and speed, whereas truth number 3 has nothing to do with the speed or time. If you don�t understand what I am talking about then go and read the RFC 1925.
There have been several RFC�s that reveals the literary aspects of computing. The following four are the ones which illustrate the poetic aspect of computing.
This one is a collection of poems that were presented at �Act One�, a symposium held partially in celebration of the 20th anniversary of ARPANET. My favorite among the ones here is �THE BIG BANG� (or the birth of the ARPANET) by Leonard Kleinrock.
This is nice poem by Vint Cerf, published in 1985, exposes the dangers of the off-by-one index error in programming. It discusses the problems that may arise and debugging technique used in bringing a new network into operation.
You must have heard the Christmas song, "The Twelve Days of Christmas". Our tech people have released a new and improved version of it. They call it �The 12-Days of Technology Before Christmas�. So don�t forget to update yourself with this new song by reading this RFC.
A brilliant work by Stanley R. Greenfield, this RFC makes us think about the origin of words that we take for granted in the computing world. Words like bus, net, port, bridge, and menu that people have associated with computing are though of entirely differently by non-geeks.
An RFC can be submitted by anyone, but before you publish it as an RFC, you need to publish it as an Internet Draft (I-D). The I-D is made available for informal review and comment by placing them in the IETF�s �Internet-Drafts� directory, which is accessible through number of other hosts also. Once it gets approved, it is published as an RFC. You may refer to RFC 2223 - Instructions to RFC Authors.
April 1st submissions are the only RFC�s-to-be which do not need to be published as an internet-draft. These entries should be sent directly to the RFC Editor. If they find it interesting enough, it will be published as an RFC on April 1st.
In this article I have given a short description of some of the interesting RFC�s that I found. There are many other interesting RFC�s out there. When you actually start reading them, you will find that most of them are very interesting and lively. Go ahead read them and learn some of the protocols, best practices, reviews, experiments, and information on some topic. That�s what an RFC is supposed to contain. Don�t they?
Well, following is list of some more interesting RFC�s.
RFC 602 - The Stockings Were Hung by the Chimney with Care
![[BIO]](../gx/2004/authors/pawar.jpg) Amber Pawar is a software engineer working with an MNC. He is an
alumnus of 'National Center for Software Technology' (NCST). He likes
reading and listens to all kinds of music except the sort which he
better refers to as noise. One thing that he misses the most these days
is the home-cooked food. His interest involves Linux L10N and Data
Structures.
Amber Pawar is a software engineer working with an MNC. He is an
alumnus of 'National Center for Software Technology' (NCST). He likes
reading and listens to all kinds of music except the sort which he
better refers to as noise. One thing that he misses the most these days
is the home-cooked food. His interest involves Linux L10N and Data
Structures.
By Pramode C.E.
A student came and told me that his Linux system was not shutting down automatically when the power button was pressed. It was a problem with ACPI (Advanced Configuration and Power Interface) not being set up properly on his machine. This was an opportunity to learn a bit about power management and its implementation under Linux. I was not particularly interested in the topic, but reading a few files under drivers/acpi convinced me that I could turn this into an interesting demonstration of how to go about reading and deciphering kernel code.
Power management is a serious issue in modern systems - the Operating System should be able to determine things like battery charge level, CPU temperature, etc. and take intelligent actions. ACPI is designed with the objective of giving the OS as much flexibility as possible in dealing with power management issues. This much I was able to understand by doing a quick Google search. When one article mentioned that the complete ACPI spec was well over 500 pages, I concluded that this was not my cup of tea. I just wanted to know what the OS does to shut down and power off my system cleanly when I press the power button; no way I am going to read 500 pages of a manual to understand that.
The first thing was to find out whether my kernel had ACPI code compiled into it. A quick
dmesg | grep ACPIsolved the problem - it is. As with all things complex (say USB), it's a worthwhile guess that the kernel might contain some `core' code to handle all the really tough things like communicating with the ACPI BIOS and finding out what all `events' had taken place (pressing the power switch is one event). The code which `reacts' to these events should be much simpler and would mostly be written as a module. Keeping in mind the basic Unix philosophy of pushing `policy' as much towards the user as possible, you will guess that this `reaction' would be mostly letting a user level process know that something has happened. Now, how does a device driver let a user space process know that something has happened? Two of the simplest ways are using a proc file entry and using a device file - proc file entry being the better bet. Sure enough, looking under /proc, I saw a directory called `acpi'.
The last link in the chain would be a user level program which reads some file under /proc/acpi and performs some actions based on the event information it gets from the kernel - let's say, a program called `acpid'. A `ps ax' showed me that such a program was running. Running an
strace -p <pid>showed the program doing a `select' on two file descriptors 3 and 4. Killing acpid and running it once again like this:
strace acpiddisplayed the following line as part of the output:
open("/proc/acpi/event", O_RDONLY);
So, that's it! Just read from /proc/acpi/event and
you will know what all power management `events'
had occurred. I killed acpid and did a
cat /proc/acpi/eventThe process expectedly blocked. Pressing the power button resulted in the following line getting printed:
button/power PWRF 00000080 00000001The chain is almost complete. How does the core ACPI code know that the button has been pressed? The kernel can't keep on doing some kind of busy loop - interrupts are the only way out. Sure enough, a `cat /proc/interrupts' showed:
CPU0 CPU1
0: 11676819 11663518 IO-APIC-edge timer
1: 8998 7247 IO-APIC-edge i8042
2: 0 0 XT-PIC cascade
8: 1 0 IO-APIC-edge rtc
9: 3 1 IO-APIC-level acpi
12: 84 0 IO-APIC-edge i8042
(other stuff deleted)
Look at IRQ 9 - that's what we are interested in. Pressing
the button resulted in the interrupt count getting
incremented.
Here is the complete chain:
Power Button
|
|
IRQ 9
|
|
Core ACPI Code
|
|
Button Driver
|
|
User Program Reading /proc/acpi/event
A quick look under /usr/src/linux-2.6.5/drivers showed a directory called `acpi' which has a file called `button.c' - surely this must be the `plug-in' driver code which responded to button events. Another file called `event.c' has routines which respond to open/read requests from user space.
A `read' request from userspace on the file /proc/acpi/events results in `acpi_system_read_event' getting invoked. This function in turn invokes `acpi_bus_receive_event' which blocks if no event has been posted by the button driver code. Events are posted by a function called `acpi_bus_generate_event' defined in the file bus.c.
Getting a `high-level' idea of the working of the button driver code is fairly simple. When trying to get a grip on driver code like this, it might be good if you can strip off some lines so that you can better concentrate on the essentials. The functions acpi_button_info_seq_show, acpi_button_info_open_fs, acpi_button_state_seq_show, acpi_button_state_open_fs, acpi_button_add_fs and acpi_button_remove_fs can be safely taken off. A few simple printk's at the beginning of the functions which we find interesting will give us some idea of the flow of control. Here is the first cut-down version of button.c:
Here are the things which I noticed when the module was compiled separately and loaded into the kernel (2.6.5).
static struct acpi_driver acpi_button_driver = {
.name = ACPI_BUTTON_DRIVER_NAME,
.class = ACPI_BUTTON_CLASS,
.ids = "ACPI_FPB,ACPI_FSB,PNP0C0D,PNP0C0C,PNP0C0E",
.ops = {
.add = acpi_button_add,
.remove = acpi_button_remove,
},
};
The guess is that acpi_button_add would be talking with the lower level
`core' code and arranging for some handler functions to be invoked when
events like a power or sleep button activation are detected (well - lots
of vagueness here - the source code talks of a POWER and POWERF button as
well as a SLEEP and SLEEPF button. Can somebody who knows the code better
enlighten me as to what POWERF and SLEEPF are for?). As handlers are to
be invoked for multiple button types, the acpi_bus_register_driver
function would be examining the .ids field of the structure and parsing the
names in it one by one, invoking the acpi_button_add function each
time it encounters another name (this might be a dumb guess - I haven't really looked into
scan.c which implements the acpi_bus_register_driver function. Trouble is,
I don't understand why `add' is getting called only twice).
The next revision of button.c, I keep only one name, ACPI_FPB in the .ids field and trim down acpi_button_add/acpi_button_remove to handle the case of only the power button. The most important line to look for in this function is the invocation of acpi_install_fixed_event_handler which registers the function acpi_button_notify_fixed as a handler to be invoked when the ACPI system detects button activity.
The handler (acpi_button_notify_fixed) calls acpi_button_notify which in turn calls acpi_bus_generate_event. Remember, a read on /proc/acpi/events was blocked by acpi_bus_receive_event. The read (and the user level process) comes out of the block when acpi_bus_generate_event is invoked!
Let's modify the driver so that it uses a different interface for communicating with userland - a simple char driver (well, this is a rather stupid idea - but we have to make some change!). The `read' method of the driver goes to sleep by calling `interruptible_sleep_on' while the acpi_button_notify_fixed function wakes it up.
Let's say the driver is allotted a major number of 254. We make a device file:
mknod button c 254 0and try `cat button'. The reading process goes to sleep. Now, we press the power switch and it immediately comes out of the block!
A simple shell script (lets call it `silly_acpid')
#!/bin/sh cat /home/pce/button poweroffRun this in the background and press the power switch - voila, the system gets shut down and powered off automagically!
The October 2003 issue of ACM Queue has an introductory article on ACPI meant for newbies; it is a good read. The Linux ACPI project has its home page here. The source code of the simple `acpi daemon' program can be downloaded from here. The module compilation process for the 2.6 series kernel is different from that for the 2.4 series. More information is available under /usr/src/linux/Documentation/kbuild/.
I am an instructor working for IC Software in Kerala, India. I would have loved
becoming an organic chemist, but I do the second best thing possible, which is
play with Linux and teach programming!
By Mark Seymour
Last month's column discussed hierarchy, the relationship of one section of information to another, but now you need to arrange your information relative to the size and shape of the document you're creating, whether it's a printed piece or a website. Even on a single page, arranging your data effectively and quickly can be a challenge. One method of simplifying the process is to create a grid that will structure your layout.
A design grid is precisely that: a set of lines, usually horizontal and vertical, that form columns and boxes to which you can align your type and rules and illustrations. The use of grid is far older than those modern designers who claimed to have invented it in the 1950s; as soon as Gutenberg invented movable type, the rectangular alignment of text would gradually replace the far more fluid page design practiced by the calligraphers of the Middle Ages.
As examples of what would disappear with the surplanting of writing by printing, here are pages from the classic Lindisfarne gospel, illuminated in 715 (that's not a typo, by the way; the monks in the Northumbrian monastery at Lindisfarne were working in inks on vellum 700 years before Gutenberg began his career), and a letter by the famed Italian calligrapher Arrighi, written in 1521 (click on the images for a larger view):
Here is Gutenberg's Bible, printed in 1454, and a magnificent work by Arrighi, done in 1513, proving that calligraphy did not die out overnight (click on the images for a larger view):
But the use of grid, however, predates Gutenberg. Note, in this Bible handwritten in France in 1190, how the scribes laid down a grid of pale blue lines to denote the areas where the text should align, as they still did much later in this Spanish breviary and a Book of Hours illuminated in England (though written in Latin), both done in 1450 (click on the images for a larger view):
![[Bible Image]](misc/seymour/Bible1190.png)
![[Breviary Image]](misc/seymour/Breviary1450.png)
![[Book of Hours Image]](misc/seymour/BOH1450.png)
(For more examples of classic calligraphy, browse Dartmouth's collection, or that of the British Library.)
If the French bible is not the first use of grid, it's a very early example. It's also a very complicated 6x11 grid, with precise spacing; it could easily be used to lay out a sophisticated book or magazine page today. While the large "white space" borders would now usually be seen only in art or photography books, they allowed for the marginal notations (corrections, additions, or observations) often added by later scribes or owners of the manuscript; the study of 'marginalia' is used by scholars to track both textual and political changes to ancient works.
The use of white space is fast becoming a lost art, now usually seen only in the design of hardback books. My calligraphy and book design professor, Arnold Bank, was explicit about margins or borders: gutter margins (the left hand area in the French bible photo; it's a right-hand page) were '1', top margins were '2', outside margins (the right hand area in the French bible) were '3', and bottom margins were '4'. These are not absolute numbers, like inches or picas, but relative numbers: once you decided the width of one margin, based on the size and shape of the page, the others computed themselves. They provide an elegant, if increasingly unused, look to the page.
Most margins in our four design paradigms - books, newspapers, magazines, and catalogs - are set mechanically these days; a half inch or three-quarters of an inch is common, and the same dimension is often used all the way around the page. Corporate designs (letterhead, newsletters, etc.) are even more uniform; you can assume a half inch margin on almost any piece you pick up.
Web design, of course, is both more flexible and more imprecise. It's more flexible, in that every page in a site can have (not that it should have) a different set of margins, as can each paragraph on the page. It's more imprecise, in that it's very hard (even with CSS) to specify the exact dimensions or position of any object on the page; every combination of OS and browser will produce a different result, some slight and some horrific.
To see the effects of grid on information, check out these simple ungridded and gridded versions of the Gettysburg Address. While readable, the ungridded version does not present Lincoln's words with the gravity they deserve, and the photographs are not in any recognizable order. The gridded version, though not terribly sophisticated graphically, provides a clear path for the reader to acquire the information, and reinforce the somber dignity of his speech. Adding more data, or more complex imagery, would make the ungridded page even more difficult to read.
There are grids in use around us all the time, some so familiar that we fail to notice. Cities like New York, of course, whose streets are laid out in equally spaced, right-angled rows, exemplify the grid; how else could you have 'gridlock'? The layouts of almost all printed periodicals are based on grids; as noted in last month's column, newspapers have been gridded for hundreds of years. Comic strips, while not typically thought of as mainstream design metaphors, are commonly drawn using grids; one of the criticisms of 'underground' comics was that they refused to keep their material "in the box" like their more mainstream cousins. While magazines have taken to breaking the grid of late (Wired magazine is an excellent example, though their website is pretty gridded up), there usually remains an underlying grid which provides the stable base from which the designer can then depart.
Alignment and consistent spacing is the key to an effective grid. Going back to our prototype grid, note how a simple set of columns and rows provide a very complex set of possible alignments:
Now let's use that same grid in a modern context. (As html-generating software for web design is still in the Dark Ages, well before Gutenberg's time, relative to page-layout software for print design, the sample pages below were created off-line using graphic software.) I've recreated the 800-year-old French grid, 6 columns wide by 11 rows tall (click on the image for a larger view):
Now let's take that grid and stretch it into modern (5.50 x 8.50 inch) dimensions; this is a half-sheet of letter-sized paper, thus a common page size (click on the image for a larger view):
Then let's put our Gettysburg Address text and photos into this grid (click on the image for a larger view):
It's much better graphically than our first attempt, and it can also be rapidly shifted, if the layout of the document requires a different look (though the long line length of the Address text in this version is problematic, an issue we will cover in a future column) (click on the image for a larger view):

We could stir this page any of a half dozen ways, still using our eight-century old grid, and achieve equally good-looking solutions. But these examples will hopefully illustrate the power and the glory of using grids. It's a simple way to make your work cleaner, faster, and more professional looking.
I'm not going to over-analyze these grid-using sites, but they're a good place to start your own study into the use of grid:
http://www.airbagindustries.com/; an extremely elegant personal site. Many bigger sites could learn a lot from this guy.
http://www.lacountyarts.org/; this site is (perhaps) excessively gridded. It seems to use the boxed grid even in instances where it's more awkward or confusing than another visual construct might prove.
http://www.eskimo.is/news.asp; a simple set of grids, but effective. Note that there are at least four grids at work here: the text & photos grid in 'News', the text-only variant in 'The Company', the photos-only grid in 'Models', and the data collection grid in 'Request'.
http://hitchhikers.movies.go.com/hitchblog/blog.htm; a small site that uses its grid effectively, with good navigation tools that let you move quickly through the site.
http://www.idmodels.com/; a hard-gridded site, with only three grids in use. Fortunately, they leave Flash animations behind on the landing page, but their other pages are very rigid, with text and photos absolutely identical on every page that uses the same grid.
For further study, there are numerous works available on the use of grid in graphic design. Check out the gridded structure of these book covers; the authors (or their jacket designers) practice what they preach:






Note that several of these books were written by German or Swiss authors; if you've ever been to either country, you'll know why. If you haven't, imagine extreme tidiness as a national characteristic...
There is also grid-producing software available, though you can create your own (or at least a semblance of a grid) in most layout applications these days, whether print or web.
Now, go and grid some more.
I started doing graphic design in junior high school, when it was still
the Dark Ages of technology. Bill Gates and Steve Jobs were both eleven
years old, and the state of the art was typing copy on Gestetner masters.
I've worked on every new technology since, but I still own an X-acto knife
and know how to use it.
I've been a freelancer, and worked in advertising agencies, printing
companies, publishing houses, and marketing organizations in major
corporations. I also did a dozen years [1985-1997] at Apple Computer; my
first Macintosh was a Lisa with an astounding 1MB of memory, and my current
one is a Cube with a flat screen.
I've had a website up since 1997, and created my latest one in 2004. I'm
still, painfully, learning how web design is different from, but not
necessarily better than, print.
![[BIO]](../gx/authors/seymour.jpg)
The Ecol comic strip is written for escomposlinux.org (ECOL), the web site that supports es.comp.os.linux, the Spanish USENET newsgroup for Linux. The strips are drawn in Spanish and then translated to English by the author.
These images are scaled down to minimize horizontal scrolling. To see a panel in all its clarity, click on it.
![[cartoon]](misc/ecol/ecol-160-e.png)
![[cartoon]](misc/ecol/ecol-165-e.png)
All Ecol cartoons are at tira.escomposlinux.org (Spanish), comic.escomposlinux.org (English) and http://tira.puntbarra.com/ (Catalan). The Catalan version is translated by the people who run the site; only a few episodes are currently available.
These cartoons are copyright Javier Malonda. They may be copied, linked or distributed by any means. However, you may not distribute modifications. If you link to a cartoon, please notify Javier, who would appreciate hearing from you.
You may have noticed a difference in this month's Laundrette - that it's got an author credit. This is entirely because of this foreword; it normally seems inappropriate to me to take credit for merely quoting the Answer Gang, but this month I want to talk about why I do it.
Those with long enough memories will remember that this used to be the "Not the Answer Gang" section, which Mike included in his Back Page from time to time. I always found this amusing, and because I wanted to see it continue I picked up from where Mike left off. Literally - the first Linux Laundrette was almost entirely made up of material Mike had selected.
What prompted this foreword was a comment in this thread: "You are really serious about this 'Making Linux a little more fun' thing, aren't you?"
Yes, we are.
Mature manhood: that means to have rediscovered the seriousness one had as a child at play.
--Friedrich Nietzsche, "Beyond Good and Evil", Aphorism 94
In almost every volunteer effort, a core group forms of those who are most interested in maintaining the effort. Although the cliché goes that familiarity breeds contempt, the opposite is true - familiarity breeds friendship. The very existence of a core group, who regard each other as friends, is to be expected, though can lead to accusations of cliquishness.
Fortunately, I have never seen these accusations made against LG. In general, regular readers tend to want to help, by writing articles, sending tips or news, or by joining the Answer Gang. Again, this is easily explained by the idea that familiarity breeds friendship (in his book "Get Anyone To Do Anything", David J. Lieberman calls this "The Law of Association"). Part of the reason for the Linux Laundrette is to show that the Answer Gang is not a closed group - we welcome anyone who wants to make a contribution. More than that, the Laundrette is meant to show that TAG goes offtopic - it's not all technical talk, so there's no need to feel intimidated if you're not the most knowledgable person around. Everyone has something to teach, and hopefully a smartass comment or two to make.
So, to sum up, if you've got a tip or an article to share, send them in. But don't forget our mission - if you've got something fun to share, we want that too!
You may have seen Sluggo's mention of Pie-thon in the mailbag this month. Those of you who don't get NTK (and why not, I ask?) can look at their take, which I've conveniently quoted here:
>> HARD NEWS <<
Perl hullabaloos
Last year, DAN SUGALSKI, lead developer of the forthcoming
Perl6 virtual machine, Parrot, bet the Python developers
that he could run Python faster on the fledgling VM - and the
creator of Python could throw a pie at him at the next OSCON if
he didn't. He didn't; the pie-ing was duly arranged. As
everyone knows, while Perlites are chaotic/good trickster
archetypes who love such events, Pythonistas are peaceful,
have-their-glasses-on-a-little-string types, like hobbits or
the Dutch. In the end, Guido van Rossum refused to throw the
pie, and instead offered to share it as food with the Perl
developers. Nothing, of course, could have been more
guaranteed to throw Perlsters into violent rage. An extended
period of acrimonious bargaining followed, in which the Perl
crew grew more and more insistent that their own chief
developer be humiliated, with many walking out of the
session, muttering about "all foreplay and no sex". Later,
the Perl faction took it upon themselves to pie Sugalski -
much, we are sure, to the shock of the pacifistic Pythonese,
who may well have planned that using their psychomathematics
and indented whitespace necromancy all along. (Mind
you, that didn't stop Guido finally joining in. Feel the
punctuation rising in you, Guido!)
http://www.sidhe.org/~dan/blog/archives/000372.html
- Dan gets last laugh later in August
There are pictures are here: http://www.oreillynet.com/pub/a/oscon2004/friday/.
You can also read the story on Dan Sugalski's blog: "Mmmm, pie!", "After the pie-thon", and "Pies away anyway"
The most amusing thing I've come across this month is Spamusement - badly drawn comics inspired by Spam subject lines. There's even an RSS feed available. Try the super pill will help you, quantities of a ruddy-brown fluid were spurting up in noisy jets out of the, remember your teen years?, and She's got a suprise in her pants ;)
Another thing I found amusing, but for entirely different reasons, was that Microsoft have patented sudo. (It was made more amusing by the amount of e-mail I got from my college friends after I submitted the story to Slashdot).
After last month's spam joke, we were sent another by the same people:
An engineer died and ended up in Hell. He was not pleased with the level of comfort in Hell, and began to redesign and build improvements. After a while, they had toilets that flush, air conditioning, and escalators. Everyone grew very fond of him. One day God called to Satan to mock him, "So, how's it going down there in Hell?" Satan replied, "Hey, things are great. We've got air conditioning and flush toilets and escalators, and there's no telling what this engineer is going to come up with next."
God was surprised, "What? You've got an engineer? That's a mistake. He should never have gotten down there in the first place. Send him back up here."
"No way," replied Satan. "I like having an engineer, and I'm keeping him." God threatened, "Send him back up here now or I'll sue!" Satan laughed and answered, "Yeah, right. And just where are YOU going to get a lawyer?"
As you may have read in the mailbag, Ben has had "difficulties" this month, so we've unfurled the red carpet to welcome back Sluggo, who sportingly agreed to step in and edit this beast and deal with inconsiderate gits trying to make last minute changes (/me tries to look innocent).
With Sluggo back, we have some spam to throw out there... yay!
[Sluggo] And what is a "qualified" website, pray tell?
[Jimmy] One with a degree? (Bought from one of the various spammers, obviously)
---- Forwarded message from Tom Seely ----- Subject: *****SPAM***** Client Referral Dear Customer, Be the very first listing in the top search engines immediately. Our company will now place any business with a qualified website permanently at the top of the major search engines guaranteed never to move. This promotion includes unlimited traffic and is not going to last long. If you are interested in being guaranteed first position in the top search engines at a promotional fee, please reply us promptly to find out if you qualify. This is not pay per click. The following are examples on Yahoo!, MSN and Alta Vista: Company: Oahu Dive Center URL: http://oahudivecenter.com keyword: oahu scuba diving Company: California Moves.com URL: http://steph.cbsocal.com/ keyword: find a home southern california Company: Dana Hursey Photography URL: http://www.hursey.com keyword: location photographer Sincerely, IGN The Search Engine Promotional Consultants
[Predrag Ivanovic (Pedja)] In article "Which window manager" in #105 of LG MGM was mentioned. It looked interesting enough, so I looked it up.
I found it on http://www.linuxmafia.com/mgm
My mistake was that I started reading the FAQ
while drinking coffee... ![]()
[Thomas]
It is amusing, isn't it. ![]() I remember it from way back. I do have
to thank Rick Moen for resurrecting it.
I remember it from way back. I do have
to thank Rick Moen for resurrecting it. ![]()
[Ben] Whups. We should probably warn people about that. Me, I cautiously set aside any drinks and dangerous objects (err, well - except my mind) before opening any mail prefixed with [TAG]; I know this bunch.
[Pedja]
Classic case of C|N>K
My nose is much better now, thank you...
[Ben] Let me tell ya, be glad you weren't eating raisins or peanuts. Those can really hurt your nasal passages, and leave dents in your walls and furniture!
[Pedja]
You are really serious about this 'Making Linux a little more fun' thing,
aren't you?
Thank God for that.
[Thomas]
We have to be, Predrag, otherwise we'd be YAMP (Yet Another Man
Page). ![]()
[Ben] [grin] That's the LG to a tee. 'Fun' isn't our middle name - it would involve all sorts of boring paperwork, people would ask pointed questions about changes in marriage status, and applying to courts in various countries would be a real hassle - but we do enjoy ourselves, usually.
[Rick] You're very welcome, Predrag. Furthermore, I'll take this opportunity to declare you an official Linux Gazette Evil Genius. We'll be sending you your white Persian cat and monocle via separate attachment. Go forth[1] and conquer.
[1] Or FORTH, perhaps.
[Jimmy] test.php:
[Ben]
Whups! [sound of me running away] ![]()
[Jimmy] Huh?
[Ben] PHP and I don't see eye-to-eye - never have. We've agreed to stay in our respective corners and ignore each other (I'm still planning on catching it alone after school, though.)
[Jimmy] Ah. I thought it was horror at the very idea of doing something like that. Well, I wouldn't rate PHP too highly as a language, but back when I did web design it was part of the spec on enough jobs that I stuck to it. Ruby looks nice, but it wouldn't have been an option back then, as too much of the stuff I had to do was for sites hosted on Cobalt RaQs,
[Thomas] Oh, ick. My condolences.[Jimmy] Heh. I'd much rather spend a decade using them than spend another week doing what I'm currently doing.
[Thomas] You still work in a... meat factory, if memory serves?
[Jimmy] Yep. Though I think it's less soul-destroying than being a COBOL programmer would have been.
[Jimmy] which didn't come with a compiler, so I was stuck with what came with the box - PHP or Perl - I still get nightmares about the time I had to tamper with Sendmail - the box didn't have the M4 files (probably didn't have M4, for that matter).
[Brian] I found this great quote while researching for the book about 4 years ago:
"He who has never hacked sendmail.cf has no soul;
he who has hacked sendmail.cf more than once has no brain."
- Old Hacker Proverb
[John] And I've found this one lying around:
"sendmail"'s configuration file looks like someone's been banging
their head on the keyboard. And after looking at it... I can see why!
- Anonymous
[Jimmy] Coming out the other side of that definitely had the "Today, you are truly a man, my son" feel to it. Sendmail: putting the SM into SMTP.
[Rick]
The mere fact that distros for Cobalt RaQ and Qube hosts were perenially
obsolete, underequipped, and unmaintainable didn't actually make them
completely useless: If nothing else, they made dandy honeypots.
![]()
[Jimmy] Yeah. I'd feel sorry for any poor script kiddie who got lured to one of those. "Yay! I got root. Now what the hell can I do with it?". They were fun to configure. The web-based configuration thing liked to either break or dump any manual changes. I received a lot of angry e-mail when something like changing a user's quota stopped sendmail.
[Brian] And here I thought that the purpose of breaking sendmail was to not receive anymore complaints via email...
My least favorite bit about the Cobalts was that when they DID finally put out an update for a particular broken and/or vulnerable package, either (A) the GUI package updater would only work halfway, leaving the system in a state nearly requiring reimaging, or if updated sanely (from the ill-documented CLI tools, would break something else in a way that has my traffic management buddies shouting, "Spectacular Kill!!!".
A specific example was the kernel update for the RaQ 550 that would report perfectly good RAIDs as borked, then fail (also spuriously) during the rebuild. That necessitated two seqentially replaced hard drives before a tech called back and said, "Oh. Um. You might want to downrev your kernel before returning a third drive." Sigh.
[Jimmy] I was put off Perl for years after trying to learn how to do CGI when I was in college, as the tutorials I read thought manually processing form data was OK, and I didn't.
[Thomas] I agree. Why keep a dog and bark yourself.....
[Jimmy] I have to be honest; I'd have done it, but I just didn't get regexes. Didn't get it until last month, in fact, when whatever it was that was confusing me jumped off the screen and slapped me - now I can't remember what it was that I thought was confusing.
[Thomas] That would be one of Ben's fishes that leapt away...
[Jimmy] Leapt away? Yes, I believe that. Hmm... is that Ben's name I see on the list of world fish throwing champions?
[Ben] Oh, sure, go ahead and pick on the Floridian. Just because I live in mullet-throwing country... http://www.florabama.com/Special%20Events/Mullet%20Toss/mullet_toss_faq.htm
[Jimmy] Oh, that kind of mullet. I was thinking that was a little extreme
[Jimmy] It was probably a Pavlovian reaction after some of the abysmal Perl I've seen.
[Thomas]
Pavlovian? Hmm, I'd watch out for that meringue, if I were you. ![]()
[Jimmy] Groan.
[Ben] Aw, c'mon, Jimmy. You're a pTerry fan, and know all about the Pavlovian experiments; whenever a dog rings a bell, a behaviorist has to gobble an Aussie meringue dessert...
And that quote is:It was an almost Pavlovian response.*
* A term invented by the wizard Denephew Boot**, who had found that by a system of rewards and punishments he could train a dog, at the ringing of a bell, to immediately eat a strawberry meringue.
** His parents, who were uncomplicated country people, had wanted a girl. They were expecting to call her Denise.
-- Terry Pratchett, "Jingo".
[Thomas]
Your observations are correct about LGang. That list don't hunt at the
moment.
Faber and I (poor sod ![]() ) had been in contact with me;
) had been in contact with me;
[Sluggo] "I had been in contact with me." Is this some Jekyll & Hyde thing?
[Thomas]
Nah, just me poor grammer innit, guv. ![]()
[Thomas]
I'd been trying to
subscribe via a dynamic IP... but he's been quiet since then. Time for some
ass-kicking, methinks. ![]()
[Sluggo] Like Edward Norton in Fight Club where he hit himself....
[Thomas]
Just call me Tyler.... ![]()
[Sluggo] Where are we at with HTML checking? Is anybody coordinating it?
[Thomas]
Well, I'm at [address], in my bedroom... I assume you're at your desk?
![]() (/me hides as the "joke" may or maynot be realised).
(/me hides as the "joke" may or maynot be realised).
[Sluggo] /me sees a joke is there, but its nature is mysterious. I guess I'd better file "where... at" next to "like" under "phrases not understood by/offensive to British".
[Brian] From that, I thought that you had spent time at the [snip] Grammar School (carefully found as the first four Google links for "[address]"), a place where no doubt the Nuns who "teach" the grammar do so with long, sharp, metal rulers vigorously applied to any handy body part...
[Thomas] Hahahahaha. No such luck. As I'm sure you guessed, that was just the first line of my mailing address. Although I do like the thought of such a school. Not sure about the rulers though...
[Jimmy] I went to such a school. A convent school for 4 years, and a Christian Brothers school for 5, though the nuns and brothers had mellowed out by the time I got there so we took it upon ourselves to hit each other with steel rulers.
[Sluggo] OK, I need to organize proofreaders and HTML checkers. Is Rick Moen around? He's the proofreading coordinator.
[Rick] Um, yes. Hit me. But I should mention....
[Thomas] You need excuses now? Pfft.
[Rick] Fun stuff to know and tell<tm>. Ye spouse and I will be flying to Boston, tomorrow (and boy, will our arms be tired!) to attend the World Science Fiction Convention, which runs Thursday noonish through the holiday weekend. http://www.worldcon.org/
Any Bostonians-or-therabouts, please feel welcome to drop by at the Boston Sheraton.
In consequence, because I'll not only be a tourist and attending a convention at all hours, but also will be staff for that volunteer-run convention, I will of necessity be Not On The Net at times, etc.
[Thomas]
Just make sure you have fun... that is why you're going, after all. ![]()
[Rick] Indeed. I believe they have good tea there, for starters. Albeit, perhaps a bit salty....
Sluggo wrote:
- Simplify long or complex sentances so the article is readable
^^^^^^^^^
[Jimmy] sentences?
[Thomas]
No, I believe he was right the first time. He said they're complex. Or
maybe
they're so complex, Mike's hand was shaking from the thought and it wobbled
to
the 'a' key. It does happen... honest. ![]()
[Sluggo] I always forget whether it's an 'a' or an 'e' and I have to look it up. I thought I'd finally memorized it correctly but I guess not.
[Sluggo] http://slashdot.org/comments.pl?sid=120341&cid=10138761
"I'm mildly annoyed because a 72hr outage was caused by a cow (supercow powers) munching through some BT cable. Don't they bury these things?"
"Yes. The cow was given a proper funeral, with all appropriate honours. It was very mooving."
[Jimmy] That's more worthy of Fark. "Cow chews through phone cables. France surrenders."
One Sat'day morning I woke up late I found a little monkey outside me gate I went outside to investigate The monkey was doing the latest dance craze I don't know what to say the monkey won't do I don't know what to say the monkey won't do (dit-dit-dit-da-dit, dit-dit, dit-da-dit) Now when I dance the ska Monkey dance it too And when I wash-wash Monkey wash-wash too I don't know what to say the monkey won't do I don't know what to say the monkey won't do (dit-dit-dit-da-dit, dit-dit, dit-da-dit) When I rub-en-toff Monkey do it too And when I whoop and I wawm Monkey whoop-wawm too I don't know what to say the monkey won't do I don't know what to say the monkey won't do (dit-dit-dit-da-dit, dit-dit, dit-da-dit) And when I dance the ska monkey dance it too....
[Neil] http://boards.fool.co.uk/Message.asp?mid=8697979&sort=whole
[Ben] Mmmm, some of the recipes sound really good.
My favorite comment in the thread:
"Do the bottles really explode? (I live in a one bed flat and can't really afford to be bombed out by volatile soft drinks.)"
There's something about things that grow and explode in the kitchen that I've always found strangely attractive...
When I was sailing in the Bahamas, my gf and I always kept a sourdough starter going. Actually, it died once - grew black mold - but I just mixed up a fresh batch of flour and water and let it sit for a week, and it got nice and bubbly. There's enough yeast in the air everywhere - this was in an anchorage in Georgetown, Bahamas, surrounded by the ocean. If there was enough there, then anywhere else would work... so much for all the mummery and mystique of "true Alaskan starter" or "passed down to me by my great-great-grandmother in her last will and testament".
We kept it in a little cheese crock, about a pound of it, max, at any one time, and gave some away (or had a baking spree) whenever it threatened to overrun the boat. Giving it away was trivial, once people tried our bread... Interestingly enough, "Recessional" didn't have an oven aboard (or a fridge either, FTM), so we "baked" it on the stovetop in a heavy-walled pressure cooker (valve open.) Takes a heat diffuser and a little extra care but is no problem otherwise.
Oh, and if you've never had sourdough pancakes... you have my condolences. It may well be the reason that girl turned you down for a date, why you were refused credit at that store, and probably the real reason that they wouldn't accept you for astronaut training... The happy news is that it's never too late!
THE SPONGE: Mix starter, water, and about 3 c of flour in a large ceramic mixing bowl. Mix well with a fork or wire whisk. Put it aside to work for 2-24 hours (determines how "sour" the bread will be. Overnight gives an 'average' (like store-bought) sourdough flavor.)
THE DOUGH: After sponge has bubbled merrily, blend salt, sugar, and baking soda into 2 c of flour, and mix this progressively into the sponge. When dough becomes stiff enough to hold together without sticking to your hands, turn it out onto floured board and knead it for 3 or 4 minutes. Give the dough a rest (10-30 minutes) and clean out the bowl. Knead again, place the dough back in the bowl, and let rise for 2 to 4 hours.
THE PROCESS: Knock down the dough and shape it into 2 long loaves. Place them in greased and cornmeal-sprinkled baking pans, cover and let rise for another 2 hours or so. Toward the end of the rising period, preheat your oven to 450F. Just before you put them in the oven, slash the tops of your loaves diagonally with a knife 1/4" deep every two inches and sprinkle with water. Put the loaves on the middle rack and bake for about 25 minutes.
OPTIONS: Sourdough is very forgiving of additional ingredients; unlike a lot of the more refined breads, it's hard to screw up. My favorite ones, IIRC, were:
...but it's awesomely good just plain, with a little butter on top.
Sourdough pancakes, well... a man's got to have his secrets, y'know.
It's one of my secret weapons in the battle of the sexes, and I'm not
just giving that away. ![]()
Jimmy has been using computers from the tender age of seven, when his father
inherited an Amstrad PCW8256. After a few brief flirtations with an Atari ST
and numerous versions of DOS and Windows, Jimmy was introduced to Linux in 1998
and hasn't looked back.
In his spare time, Jimmy likes to play guitar and read: not at the same time,
but the picks make handy bookmarks.
Jimmy is a single father of one, who enjoys long walks... Oh, right.

![[Lindisfarne Image]](misc/seymour/Lindisfarne715.png)
![[Arrighi Image]](misc/seymour/Arrighi1521.png)
![[Gutenberg Image]](misc/seymour/Gutenberg1454.png)
![[Arrighi Image]](misc/seymour/Arrighi1513.png)
![[Grid Example Image]](misc/seymour/Grid1190Small.png)
![[Modern Grid
Example Image]](misc/seymour/GridModernSmall.png)
![[Gettysburg Grid
Image]](misc/seymour/GridAddressSmall.png)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
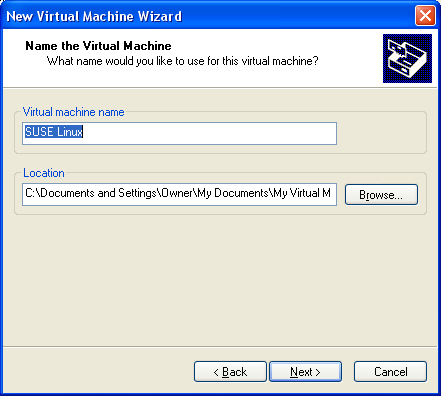{kind=link}
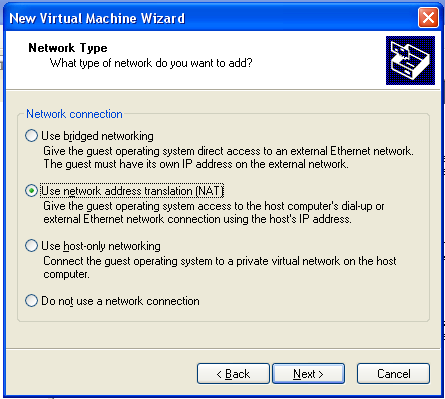{kind=link}
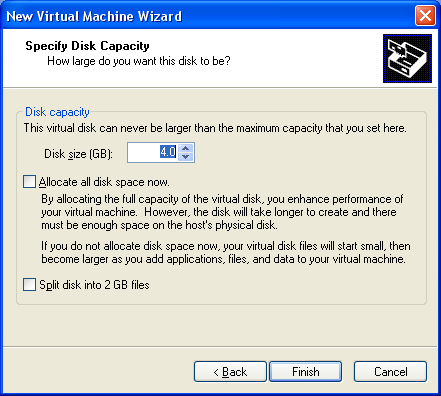{kind=link}
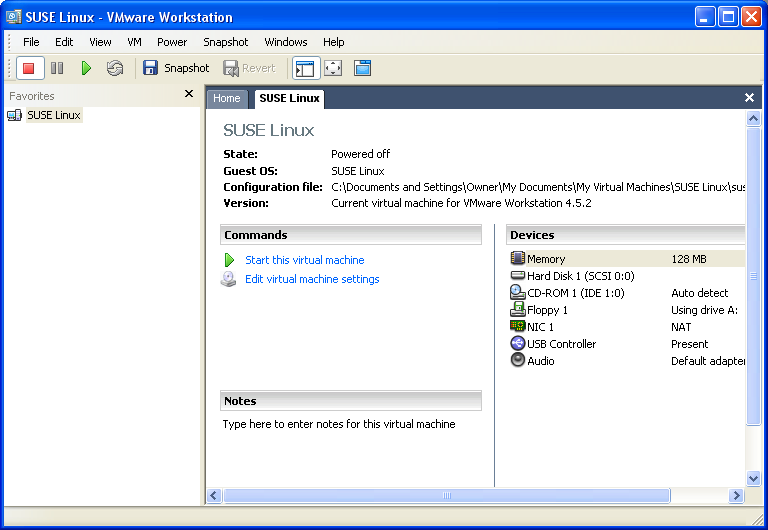{kind=link}
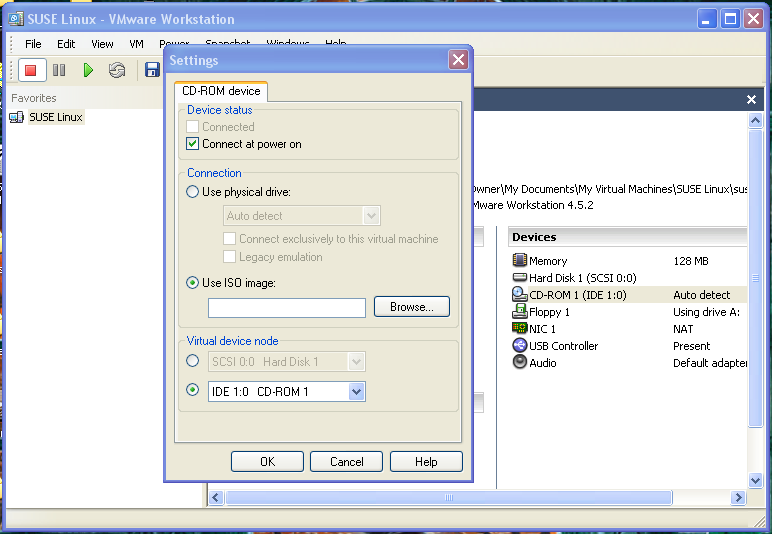{kind=link}
{kind=link}