
...making Linux just a little more fun!
Ben Okopnik [ben at linuxmafia.com]
...and it's quite the story. Not because of us specifically, but because theplanet is such a huge data center - i.e., it's causing a huge outage all over the place.
To quote Doug Erwin of theplanet (issued at 10:46 PM, May 31 2008):
This evening at 4:55pm CDT in our H1 data center, electrical gear shorted, creating an explosion and fire that knocked down three walls surrounding our electrical equipment room. Thankfully, no one was injured. In addition, no customer servers were damaged or lost. We have just been allowed into the building to physically inspect the damage. Early indications are that the short was in a high-volume wire conduit. We were not allowed to activate our backup generator plan based on instructions from the fire department. This is a significant outage, impacting approximately 9,000 servers and 7,500 customers. All members of our support team are in, and all vendors who supply us with data center equipment are on site. Our initial assessment, although early, points to being able to have some service restored by mid-afternoon on Sunday. Rest assured we are working around the clock.
Our publication process is rolling on regardless of this, of course. In principle, we should be back up pretty much as soon as theplanet is. For the moment, if anyone needs to contact me, I'll be monitoring this linuxmafia.com address.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://linuxgazette.net *
[ Thread continues here (6 messages/4.61kB) ]
Ben Okopnik [ben at linuxgazette.net]
Hi, Nicola -
On Mon, Jun 09, 2008 at 09:28:54PM +0200, nicola giacobbe wrote:
> Hello, > I have just discovered your webzine (it is that the name?), it is fresh > and full of nice goodies and I am eager to get all past issues. Of course > they are available but just downloading it without a thanks or a hug > seemed rather rude.
Actually, we make them available for exactly that purpose; we even have a repository with all the issues compressed into tarballs for downloading.
http://linuxgazette.net/ftpfiles/
> Are you willing to sell them on DVD for a nominal sum (let's say $10+S&H)?
Nope - it's all free!
> Or is there any other way to even your good job? > Just let me know...
Nicola, you've just "paid". Thank you for your considerate question, and you're more than welcome. I hope you enjoy reading LG!
Best regards,
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
Simon Lascelles [simon.lascelles at rems.com]
We are looking for a version of Linux we can use legally in Syria. Do you know of a list of all Linux variants and their country of origin or do you know of a variant that is export compliant?
-- Simon Lascelles Managing Director REMS International Email: <blocked::mailto:[email protected]> [email protected] Web Site: <http://www.rems.com/> http://www.rems.com/ Mobile: 07956 676112 Telephone: 01727 848800Yahoo: [email protected]
Mobile communications are changing the face of business, and organisations that deploy mobile solutions will reap the greatest competitive advantage
_________________________________________________
[ Thread continues here (10 messages/35.63kB) ]
Rick Moen [rick at linuxmafia.com]
Recently received Chez Moen, and I replied back saying it's indeed an astute and elegant idea, which I might very well adopt for my own domains. (In the absence of an MX = mail exchanger record in the DNS for a mail-receiving machine on the Internet, RFC 2821 specifies that the sending host should fallback on the "A" = forward lookup record, instead. This was also true with the original SMTP-defining RFC, RFC 821.)
And, in case anyone is wondering, Gokhan Gucukoglu's name is Turkish. He seems to be based in the UK, and is one of those protean characters active broadly across free / open source software, just to make the rest of us look bad by comparison. ;->
----- Forwarded message from Sabahattin Gucukoglu <[email protected]> -----
Date: Wed, 11 Jun 2008 09:48:55 +0100 From: Sabahattin Gucukoglu <[email protected]> To: [email protected] Subject: Spam Prevention by Enforcing StandardsHi,
I notice that linuxmafia.com has just one MX, linuxmafia.com. See RFC 2821
section 5: remove your MX record; there is an implicit MX rule. Good MTAs
know it, most spammers, their spamware, their agents, etc, etc, still
don't. It's a great little trick and is doing me bloody wonders. (It may
on very, very rare occasions break mailers which insist that there be an
MX record when you issue MAIL FROM linuxmafia.com; such mailers are broken
and you really don't want to talk to them anyway  .)
.)
(If you wonder why I noticed at all, it's your multiline greeting.)
Cheers, Sabahattin
-- Sabahattin Gucukoglu <mail<at>sabahattin<dash>gucukoglu<dot>com> Address harvesters, snag this: [email protected] Phone: +44 20 88008915 Mobile: +44 7986 053399 http://sabahattin-gucukoglu.com/
[ Thread continues here (13 messages/28.27kB) ]
dar ksyte [dksyte at googlemail.com]
Google brought me to you. You might be interested in this new resource for experimenting with crontab commands.
For most of us, setting up a new cron job is not something we do every day. So we can easily forget the details.
Cron Sandbox at HxPI offers an opportunity to play with the crontab scheduling commands in safety.
Type in the 'm h D M Dw' parameters and see a calendar of job execution times/dates.
http://www.hxpi.com/cron_sandbox.php
Regards
Dar Ksyte
[ Thread continues here (9 messages/8.87kB) ]
don warner saklad [don.saklad at gmail.com]
For users of RMAIL in Emacs, how do you deal with spam messages?...
Not all messages appear with SpamAssassin headers.
[ Thread continues here (6 messages/5.86kB) ]
Amit k. Saha [amitsaha.in at gmail.com]
On Mon, May 19, 2008 at 9:54 PM, Amit k. Saha <[email protected]> wrote:
> Hi Ben, > > On Sun, May 18, 2008 at 9:56 PM, Ben Okopnik <[email protected]> wrote: >> On Sun, May 18, 2008 at 02:51:36PM +0530, Amit k. Saha wrote: >>> Hello all, >>> >>> I have installed Ubuntu 8.04 (32-bit) beta on my 32-bit notebook and >>> the Ubuntu 8.04(64-bit) on a friend's 64-bit laptop. I am using Acer >>> laptops. >>> >>> In both cases, using the touchpad to click (single/double-click) is >>> pretty troublesome and needs a rather "hard" hit on the pad. I have >>> tried setting the mouse preferences similar to the one on Ubuntu 7.04 >>> (which I use), but to no avail.
I upgraded to the final release of Ubuntu 8.04 and things are fine now!
-Amit
-- Amit Kumar Saha http://amitksaha.blogspot.com
Hi Guys,
I was finally able to do the compilation process. Thanks for the help.
Another question:
1. I am using a tcpdump network sniffer to capture packets of the tcp header. I wanted to analyze a specific variable like smoothed rtt (srtt). I already changed the header file to include this new srtt variable into the option side of the tcp.h header file and also change the tcp_input.c source code to incorporate the said variable into the options side. I am confused whether tcp_input.c is the correct code to change since tcp_output.c and tcp.c is also in the linux kernel code. I am also confused how to output this new srtt variable into the tcp header so as to be captured by the tcpdump and be seen in the tracefiles.
Is there a specific function in the code to be manipulated to do the task? Any help would be appreciated.
Thank you very much in advance.
Cheers,
Dom
[ Thread continues here (2 messages/2.96kB) ]
René Pfeiffer [lynx at luchs.at]
Hello, Gang!
I am trying to compute a SHA1 hash inside a C++ program without linking to additional libraries. There are some SHA1 code snippets around and they seem to work. So far so good. In order to compare SHA1 sums it's nice to have them in hexadecimal representation. The SHA1 code I used holds the sum in a byte array which is basically an array of unsigned chars. Creating hexadecimal output can be done as follows:
// Filename: hex_output.cc - cout test firing range
#include <iomanip>
#include <ios>
#include <iostream>
#include <stdlib.h>
using namespace std;
int main(int argc, char **argv) {
unsigned char array[10];
unsigned short i;
// An array with a French accent (sorry, SCNR)
array[0] =3D 'A';
array[1] =3D 'L';
array[2] =3D 'L';
array[3] =3D 'o';
array[4] =3D ' ';
array[5] =3D 'O';
array[6] =3D 'r';
array[7] =3D 'l';
array[8] =3D 'd';
array[9] =3D '!';
for( i=3D0; i<10; i++) {
cout << hex << setfill('0') << setw(2) << nouppercase << array[i];
}
cout << endl << endl;
return(0);
}
Unfortunately this outputs: 0A0L0L0o0 0O0r0l0d0!
As soon as I change the cout line to
cout << hex << setfill('0') << setw(2) << nouppercase << (unsigned short)array[i];
it works and produces: 414c4c6f204f726c6421
It's late and I still lack my good night coffee, but why is that? I didn't expect this behaviour.
Best, René.
[ Thread continues here (4 messages/5.91kB) ]
Good day!
I am adding new variables to the tcp header(tcp.h) of the linux kernel and reflect this changes to the source code .Kindly shed light to my confusions below:
1. Do I have to recompile the whole kernel to reflect the changes in the header files and source code(i.e., tcp.c, tcp_input.c, etc)?
2. If so, what are the necessary steps involved( i.e., re-compile process) to reflect the new variables I added to the header file and the source codes?
3. Thank you very much in advance for the support.
Cheers,
Dom
[ Thread continues here (6 messages/7.81kB) ]
Mahesh Aravind [ra_mahesh at yahoo.com]
Dear TAG,
I was playing around the command line (learning), and I came across df(1) reporting block size in "1k-blocks". But my dumpe2fs(8) says the block size is 4096 (4K). Shouldn't it be doing thus by default?
It seems this is filed as a Bug under Ubuntu (Bug #180415).
One suggestion is for the install program to calculate the blocksize at install time, and put it somewhere safe (immutable). Like 'export BLOCKSIZE=<whatever>' in /etc/profile.
I also saw that adding ' (apostrophe) before the block size will yield you a digit separator -- cool, eh?
I did:
BLOCKSIZE="'4096" ls -l
^ <- see this?
and it gave me size figures separated by commas!
My $LANG is en_IN.UTF-8
YMMV
Regards,
Mahesh Aravind
[ Thread continues here (8 messages/8.55kB) ]
Ben Okopnik [ben at linuxgazette.net]
[[[ This had some other Subject line when the spammer sent it out. I chose to replace it with something more accurate. -- Kat ]]]
On Tue, May 27, 2008 at 03:03:29PM -0600, XXXX XXXXXX wrote:
> > Hello, > > My customer located in West Austin is searching for a recent graduate > that has significant academic / internship experience with embedded > software development. They seek someone with C programming experience > in a Linux / QNX environment. > > If you or someone you know qualified, please call me or have them call me directly. > > My number is XXX-XXX-XXXX
Thanks for letting us know... that you're a spammer. I will not, for the moment, report you to the Federal Trade Commission's "[email protected]", the FBI's Internet Fraud Complaint Center, or your state's attorney - but that's only because this is the first time you've done this here. For now, I'll grant you the courtesy of believing you to be completely clueless and ignorant rather than assuming that you knowingly violated Texas law (http://www.spamlaws.com/state/tx.shtml) as well as your network provider's Acceptable Use Policy.
I have, however, blocked you from this mailing list. Have a pleasant day.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (18 messages/30.46kB) ]
Terence Timburwa [invitation at ASPAMMERNETWORK.invalid]
Terence Timburwa has added you as a friend on [a spammer network]
[[[ Rest of the message with all the spammy splendor of bogus claims of "you have 6 messages" and "click here to remove" "click here for this" "click here for that" removed. -- Kat ]]]
[ Thread continues here (4 messages/2.72kB) ]
don warner saklad [don.saklad at gmail.com]
What other hints, tips or pointers are there with RMAIL in Emacs?... about how to refine a spam delete technique for beginners, emphasis on beginner.
For example...
. by using
C-c C-s C-s
C-c C-s C-L
. by using
Esc C-s rolex
Esc C-s viag
Esc C-s pharm
and so forth
and referring to charts at
http://www.barracudacentral.com/index.cgi?p=spam
online pharmacies
replica products
other spam
illegal advertising
casino and gaming
software sales
spam insurance
credit and debt relief
bank phishing
job offers
. or ...?
...?
For beginners with dotfile and programming skills below minimal, if at all !
Rick Moen [rick at linuxmafia.com]
Quoting Terence Timburwa ([email protected]):
> Dear tag, > Terence Timburwa
[[[ There was more to this, but I've stripped it out. -- Kat ]]]
That's funny: I'd already permanently consigned to the outer darkness the domain that sent us this rubbish last month, but neglected to do likewise with two other variants. I'm attending to that oversight, now.
Smile Maker [britto_can at yahoo.com]
Folks:
I have recently upgraded all of my jsp's to php's and pointed my rr to the new server. But for the backward compatibility How do i say to apache "if it finds request for any "jsp " go to this php page"
-- Britto
[ Thread continues here (8 messages/5.55kB) ]
Hi guys,
Good day!
I am currently doing my phd in telecommunications working on tcp. I found the document tcp_input.c and tc.c source code document at a website but browsing through my kernel, I cannot find the source codes mentioned. Thus, this inquiry.
It would be appreciated if you can kindly help me on my questions since I am new to tcp.
1. I am using fedora core6 linux and I cannot find the file tcp_input.c and tcp.c in the kernel. Where can I find this code in the kernel since I need to do some modification on the tcp header as part of my thesis?
2. What are the steps in inserting an estimated value into a kernel variable?
I have already visited the linux kernel faq and I cannot find the answer
to my questions ( or maybe I need to browse more ). I hope you can
shed light on the above queries. Thank you very much in advance.
). I hope you can
shed light on the above queries. Thank you very much in advance.
Cheers,
Dom Ignacio
[ Thread continues here (11 messages/13.96kB) ]
Amit k. Saha [amitsaha.in at gmail.com]
Hello TAG,
I have a text file from which I want to list only those lines which contain either pattern1 or patern2 or both.
How to do this with 'gre'p?
Assume, file is 'patch', and 'string1' and 'string2' are the two patterns.
The strings for me are: 'ha_example' and 'handler'- so I cannot possibly write a regex for that.
Thanks, Amit
-- Amit Kumar Saha http://blogs.sun.com/amitsaha/ http://amitksaha.blogspot.com
[ Thread continues here (3 messages/2.70kB) ]
[ In reference to "A Short Tutorial on XMLHttpRequest()" in LG#123 ]
Jimmy O'Regan [joregan at gmail.com]
I was trying to remember how to use XMLHttpRequest, and just wanted to pop a note to say thanks for a useful article!
One thing: if you're trying to test something offline, Firefox will disallow any open() requests (to try to prevent XSS). http://www.captain.at/howto-ajax-permission-denied-xmlhttprequest.php has some details about it.
Or, better yet, here's the test page I was using (the rest of 'base' is 'webservice/ws.php' - I don't think Apertium's server is quite up to widespread use of the webservice yet):
<html> <head> <title>Translate as you type</title> <script language=javascript type="text/javascript"> <!-- var base = "http://xixona.dlsi.ua.es/" var http_request; function GetTranslation(dir, data) { // For offline testing: // (see: http://www.captain.at/howto-ajax-permission-denied-xmlhttprequest.php) //try { // netscape.security.PrivilegeManager.enablePrivilege("UniversalBrowserRead"); //} catch (e) { // alert("Permission UniversalBrowserRead denied."); //} if (window.XMLHttpRequest) { http_request = new XMLHttpRequest(); } else if (window.ActiveXObject) { http_request = new ActiveXObject ("Microsoft.XMLHTTP"); } if (!http_request) { alert ("Cannot create XMLHttpRequest instance"); return false; } else { var url = base + "?mode=" + dir + "&text=" + escape(data); //alert(url); http_request.abort(); http_request.onreadystatechange = GetAsync; http_request.open("GET", url, true); http_request.send(null); } } function GetAsync() { if (http_request.readyState != 4 || http_request.status != 200) { return; } document.getElementById("translation").innerHTML= http_request.responseText; //alert(http_request.responseText); setTimeout("GetAsync()", 100); return; } // --> </script> </head> <body> <!-- direction hardcoded --> <textarea id="input" onkeyup='GetTranslation("en-es", document.getElementById("input").value)'> </textarea> <p id="translation"></p> </body> </html>
[ In reference to "/lg.tips.html" in LG#151 ]
Thomas Bonham [thomasbonham at bonhamlinux.org]
Ben Okopnik wrote:
> On Tue, May 27, 2008 at 03:41:01PM -0700, Thomas Bonham wrote:
>
>> Hi All,
>>
>> Here is a 2 cent tip which is a little Perl script for looping through
>> directory's.
>>
>
> Why not just use 'File::Find'? It's included in the default Perl
> install, and is both powerful and flexible.
>
> ```
> use File::Find;
>
> find(sub { do_whatever_you_want_here }, @directories_to_search);
> '''
>
> For more info, see 'perldoc File::Find'.
Perl File::Find didn't have everything that I want to be able to do this function. I was not just trying to find files with this but also was try to find items that was in different directory's.
When looking around on the internet for that I want to do everything thing that I was able to find said not to use file::find because it wasn't powerful enough for that I was doing so I just create that function to do some different things along the way.
Thomas
[ Thread continues here (21 messages/26.84kB) ]
[ In reference to "Monitoring Function Calls" in LG#151 ]
Francesco Russo [francescor82 at email.it]
About the article http://linuxgazette.net/151/melinte.html, there's a typo: the architecture name is x86_64, not x86_86.
-- Francesco Russo The White Rabbit put on his spectacles. 'Where shall I begin, please your Majesty?' he asked. 'Begin at the beginning,' the King said gravely, 'and go on till you come to the end: then stop.' Version: GnuPG v2.0.9 (GNU/Linux) Comment: Using GnuPG with Mozilla - http://enigmail.mozdev.org
[ Thread continues here (2 messages/1.38kB) ]
[ In reference to "USB thumb drive RAID" in LG#151 ]
s. keeling [keeling at nucleus.com]
This was just too cool not to try it. It works great. I now have a 7 Gb RAID 5 on three 4 Gb pendrives.
Caveats:
- make sure the hub you buy leaves enough room between slots to
insert your keys. Some can be pretty tight. Keys are all
shapes and sizes, and some are pretty fat. That tiny, elegant
little hub may be cute, but is it usable? I got the skinny Sony
4 Gb MicroVaults, but still their button controlling the
retractable connector gets in the way. Staples generic Relay
keys are too wide to use with this hub.
- The price range on this stuff is all over the map too, so best
to shop around. I bought a Targus hub for ca. $40, then found
an Illum for $17. Nowhere on the Targus does it mention USB
2.0. Is it? Dunno. It's going back.
- Just to be different (yet again), Debian Etch/Stable barfed on
your mdadm syntax. It insists on "-l 5" instead of "-l=5",
ditto "-n 3" instead of "-n=3".
- I notice my copy of Sidux LiveCD does not contain mdadm, drat.
Haven't looked at Knoppix yet.
- echo "(3 * 39.94) + 17" | bc -l == 136.82. I just bought an
Acomdata USB external 320 Gb 7200 rpm hard drive for 139.85.
320 for $140, vs. 7 for $137, doesn't really make much sense,
but it's still fun.
Thanks for helping me make a fun toy, and for a nicely written and
enjoyable article.
-- Any technology distinguishable from magic is insufficiently advanced. (*) - -
[ In reference to "USB thumb drive RAID" in LG#151 ]
Mohammad Farooq [farooqym at gmail.com]
This PCI card is an alternative to USB. It can support up to 4 CF cards. http://news.cnet.com/8301-13580_3-9803084-39.html
[ Thread continues here (2 messages/0.96kB) ]
[ In reference to "Mailbag" in LG#151 ]
Benno Schulenberg [bensberg at justemail.net]
[[[ In re: 'lang="utf-8" makes Firefox use an ugly font' from LG#151 -- Kat ]]]
Hmm, not very nice of you to not CC me on the continued discussion.
Benno Schulenberg wrote:
> However, I'd still like to suggest you replace "utf-8" in the > 'lang' attributes with "en", because utf-8 is not a language, and > the language the Linux Gazette pages are written in is English.
As Kapil Hari Paranjape said, my main point was that "utf-8" is not a language name. But unlike Kapil says, lang is a _language code; it has nothing to do with the encoding.
http://www.w3.org/TR/REC-html40/struct/dirlang.html lang = language-code [CI] This attribute specifies the base_language of an element's attribute values and text content. Language information specified via the lang attribute may be used by a user agent to control rendering in a variety of ways.
The base language of the Linux Gazette looks to be English. So use "en". If you want to be perfect, mark any snippets in other languages with the appropriate lang attribute.
http://www.w3.org/TR/xhtml2/mod-i18n.html
Benno
[ Thread continues here (3 messages/5.68kB) ]
Yannis Broustis [broustis at gmail.com]
Hello,
I ran the tcpsnoop on two machines, and, similarly as in Pfeiffer's example, the contention window does not get larger than 2, as time progresses.
Any ideas why?
Thanks, Y.
[ Thread continues here (2 messages/1.15kB) ]
Thomas Bonham [thomasbonham at bonhamlinux.org]
Hi All,
I will share the socket code that I wrote for checking to see if your http server is running. This will need to be run from a remote computer.
There will be something that you may need to change some things around for your needs and at this time it will not work with https it is only for http.
Here is the code I have put a few notes in where you may need to change for your needs.
#!/usr/bin/perl
use Socket;
$host = $ARGV[0];
$port = $ARGV[1];
$iaddr = inet_aton($host) || die "Unable to determine address for $host";
$paddr = sockaddr_in($port, $iaddr);
$proto = getprotobyname('tcp');
socket(SOCKET, PF_INET, SOCK_STREAM, $proto) ||
return "Unable to create a new socket: $!";
connect(SOCKET, $paddr) || die "Connection refused by $host: $!";
select(SOCKET);
$| = 1;
select(stdout);
print SOCKET "GET / HTTP/1.1\n";
print SOCKET "Host: $host\n";
print SOCKET "Connection: close\n";
print SOCKET "\n";
my $i = 0;
while (<SOCKET>) {
if($i < 1) {
# May need to change to match what header you would like back
if($_ !~/^HTTP\/1.1 200 OK/) {
# Do something here
}
break;
}
$i++;
}
Thomas
Ben Okopnik [ben at linuxgazette.net]
----- Forwarded message from Oscar Laycock <[email protected]> ----- I run a Knoppix CD on an old PC with only 128 meg of RAM. To speed things up, to reduce the swapping, I cut down on the memory set aside for my work: mount -t tmpfs /ramdisk /ramdisk -o remount,rw,size=15m,mode=755 Maybe you can do something similar on other live CD's? ----- End forwarded message -----
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
Thomas Bonham [thomasbonham at bonhamlinux.org]
Hi All,
I thought I would sure this little perl script that will remove the comments out of a configuration file.
#!/usr/bin/perl -w
# Thomas Bonham
# 06/06/08
if($#ARGV !=0) {
print "usage: path to the configuration\n";
exit;
}
$fileName=$ARGV[0];
open(O,"<$fileName") || die($!);
open(N,">$fileName.free") || die($!);
while(<O>) {
next if($_ =~/^#.*/) ;
print N $_
}
Thomas
[ Thread continues here (16 messages/15.65kB) ]
By Deividson Luiz Okopnik and Howard Dyckoff

|
Contents: |
Please submit your News Bytes items in plain text; other formats may be rejected without reading. [You have been warned!] A one- or two-paragraph summary plus a URL has a much higher chance of being published than an entire press release. Submit items to [email protected].
 Nokia on Open Cell Phone Systems
Nokia on Open Cell Phone SystemsAfter acquiring full ownership of Symbian, an operating system for cell phones, Nokia changed the product to a royalty-free model, following the market trend away from closed systems, contributing the operating system to Symbian Foundation, a newly-created open source Community.
Several cell phone providers, including AT&T, Sony Erickson, LG Electronics, Motorola and Samsung Electronics have already shown interest in the single platform, signing up to form the Symbian Foundation.
More information about Symbian OS can be found here: http://www.symbian.com/
and on the
Symbian Foundation Web page: http://www.symbianfoundation.org/ .
HP Open-sources AdvFSHP announced on June 23 that it is releasing the Tru64 Unix Advanced File System source code free to the Linux community, providing a reference implementation for an enterprise Linux file system.
More information about the AdvFS can be found at HP's page, at http://h30097.www3.hp.com/unix/advfs.html.
Kernel Developers Sign up a Letter Against Closed-Source DriversSeveral of the Linux Kernel Developers signed a letter directed to hardware vendors, showing several disadvantages of closed-source drivers to the Linux Community. The letter says, among other things, "We have repeatedly found them [closed source drivers] to be detrimental to Linux users, businesses, and the greater Linux ecosystem. Such modules negate the openness, stability, flexibility, and maintainability of the Linux development model and shut their users off from the expertise of the Linux community." It was signed by 170 kernel developers.
You can find the full text here: https://www.linuxfoundation.org/en/Kernel_Driver_Statement.
Openmoko's Linux-based
cell phone started shippingOpenmoko's Neo Freerunner is an open hardware design cell phone that runs a Linux-based operating system, which users are free to modify (and encouraged to do so!). This is the first official release of OpenMoko to the market, as the phone was mostly sold to mobile phone software developers before. The hardware consists of a 500MHz Samsung processor, 128MB of RAM, 256MB of flash memory, and a 4.3-inch 640x480 VGA touch screen LCD. It runs on the open source mobile phone software stack, maintained by the OpenMoko project, along with the open source Jalimo Java Virtual Machine.
More information about the cell phone can be found here: http://wiki.openmoko.org/wiki/Neo_FreeRunner.
LinuxWorld Partners on Global Installfest for SchoolsIDG World Expo announced it will partner with Untangle, a pioneer in open source network gateway platforms, to host an Installfest for Schools at this year's LinuxWorld Conference & Expo. Installfest is an event that drives the refurbishment of older, discarded computers, with Free and Open Source Software (FOSS) and then donates the restored computers to schools in need. LinuxWorld is scheduled to take place August 4-7, 2008, at San Francisco's Moscone Center.
Building on the success of the first Installfest for Schools, which refurbished 350 computers with Ubuntu 7.10 for schools in March of 2008, the LinuxWorld event will have local and global components. LinuxWorld attendees will be able to participate by hacking older hardware and installing the operating systems at work stations set up on the show floor. In addition, LinuxWorld will host a collection site by the Alameda County Computer Resource Center (ACCRC) to collect old computers donated by LinuxWorld attendees. The Installfest will go global by posting the scripts, ISO images, tips, and collateral online for Linux users groups (LUGs) to host Installfest for Schools in their own neighborhoods. Volunteers in Bellingham WA, and Portland OR, have already signed up to organize Installfests for Schools in their neighborhoods.
"Installfest is a tremendous effort that brings the Linux community together for a great cause, by providing computers to underprivileged schools, and promoting the use of open source software to new users," said Melinda Kendall, Vice President and General Manager of LinuxWorld Conference & Expo. "Installfest also keeps tons of toxic electronic waste from entering our landfills so it's a win-win situation for the event, the community, the schools, and the environment. We are really excited to have the opportunity to play a role in this endeavor."
Volunteers can help the effort by donating an old computer, helping to
refurbish computers on site at LinuxWorld, or by helping to organize an
event in their neighborhood. For more information or to learn how you can
help, please visit:
http://www.untangle.com/installfest/
LinuxWorld to host Free Community Days at SF ExpoIDG has announced several open Community Days slated for the upcoming LinuxWorld conference and expo. Registrants for a Community Day can attend community sessions, keynotes and community BOFs for free.
Currently there are four community conferences scheduled on separate days at LinuxWorld:
Go to this link for more information: http://www.linuxworldexpo.com/live/12/ehall//SN460564/
In another new item for LinuxWorld, The Open Voting Consortium (OVC) has teamed-up with LinuxWorld to host a demonstration of open source voting at this summer's LinuxWorld event. Attendees will have a unique opportunity to use an open source voting system to cast a mock ballot for the 2008 Presidential election, as well as witness how the votes are tallied and available for recount using this system.
oCERT keeps Open Source SecureA volunteer-based open source security clearinghouse for security vulnerabilities helps large and small FOSS efforts. The Open Source Computer Emergency Response Team, or oCERT, provides security support to Open Source projects affected by security incidents or vulnerabilities, in the same way that national CERTs offer security services for their respective countries.
While open source code is assumed to be more secure because more eyeballs get to look at it, not all projects have the requisite security experience to understand infrastructure level security concerns. oCERT can help smaller FOSS projects with security vulnerability research and assessment. The oCERT effort has attracted organizations such as Google and the Open Source Lab as sponsors.
From their website:
"The service aims to help both large infrastructures, like major distributions, and smaller projects that can't afford a full-blown security team and/or security resources. This means aiding coordination between distributions and small project contacts. The goal is to reduce the impact of compromises on small projects with little or no infrastructure security, avoiding the ripple effect of badly communicated or handled compromises, which can currently result in distributions shipping code which has been tampered with."
"oCERT also provides security vulnerability mediation for the security community, having reliable security contacts between registered projects and reporters that need to get in touch with a specific project regarding infrastructure security issues. "
Since their March launch, oCERT has issued 5 security advisories, the most
recent in June.
http://www.ocert.org/ocert_advisories.html
Sun Breaks Into Top 5 on Supercomputer ListThe Top 500 Supercomputers list was released at the International Supercomputing Conference (ISC) in Dresden, Germany in June. Sun took the #4 position with its deployment of the Sun Constellation System at the Texas Advanced Computing Center (TACC) in Austin.
New additions to the Sun Constellation System family announced at ISC are the Sun Blade X6450 server module which features 2 or 4 quad core Intel Xeon processors, providing up to 7.37 TFlops in a single Constellation System Rack and the Sun Datacenter Switch 3x24 (a smaller version of the Sun Datacenter Switch 3456), which features 72 DDR 4X Infiniband ports. Together, these new additions to the Sun Constellation System allow customers to build mid-size clusters using the same architecture as that deployed at the Texas Advanced Computing Center (TACC).
The Lustre File System is an open source solution for easy aggregation of tens of thousands of cluster nodes and petabytes of storage into one file system. Lustre can achieve >90% of raw bandwidth I/O.
Other key Sun note-worthies:
For more info on Sun at ISC: http://www.sun.com/aboutsun/media/presskits/2008-0618/
Join top security researchers and practitioners in San Jose, CA, for a 5-day program that includes in-depth tutorials by experts such as Simson Garfinkel, Bruce Potter, and Radu Sion; a comprehensive technical program including a keynote address by Debra Bowen, California Secretary of State; invited talks including "Hackernomics," by Hugh Thompson; the refereed papers track including 27 papers presenting the best new research; Work-in-Progress reports; and a poster session. Learn the latest in security research including voting and trusted systems, privacy, botnet detection, and more.

DeepSec IDSC is an annual European two-day in-depth conference on computer, network, and application security. In addition to the conference with thirty-two sessions, seven two-day intense security training courses will be held before the main conference. The conference program includes code auditing, SWF malware, web and desktop security, timing attacks, cracking of embedded devices, LDAP injection, predictable RNGs and the aftermath of the OpenSSL package patch, in-depth analysis of the Storm botnet, VLAN layer 2 attacks, digital forensics, Web 2.0 security/attacks, VoIP, protocol and traffic analysis, security training for software developers, authentication, malware deobfuscation, in-depth lockpicking and much more.
The Call for Papers is open until July 15, 2008, 23:59 CEST, and welcomed by Web form https://deepsec.net/cfp/ or by email [email protected].
openSUSE 11.0 is Out!This version, released on June 19, comes with several software updates,
including Firefox 3, KDE4, Gnome 2.22, OpenOffice.org 2.4, and many new
features, including:
Read the full announcement here: http://news.opensuse.org/2008/06/19/sneak-peeks-at-opensuse-110-a-plethora-of-improvements/
Downloads here: http://software.opensuse.org/
Kurumin NG 8.06Kurumin, a Brazilian desktop distro, just presented its first stable release, Kurumin NG 8.06. Unlike its predecessors, Kurumin is now based on Kubuntu, but keeping most of the features and enhancements developed for the project.
Some of the changes for this version are:
The release announcement is available (in Portuguese) here: http://www.guiadohardware.net/comunidade/v-t/877071/
And you can download the ISO here: http://kurumin-ng.c3sl.ufpr.br/ISO/kurumin-ng_8.06.iso
linuX-gamers Live DVD 0.9.3linuX-gamers, a "boot-and-play" distro containing several games to be played directly from the CD, just got updated on June 13. The changes include:
More information can be found on the project page: http://live.linux-gamers.net/
The release notes: http://www.linux-gamers.net/modules/news/article.php?storyid=2447
Download links: http://live.linux-gamers.net/?s=download
Games list: http://live.linux-gamers.net/?s=games
Have fun! :)
NexentaCore Platform 1.0.1On June 9, Nexenta announced the release of NexentaCore Platform 1.0.1, a distro combining the OpenSolaris kernel packaged with Debian utilities and Ubuntu software packages.
This release includes ZFS write-throttle fixes, a significant improvement on boot speed, and support for new SAS/Sata controllers.
The full release notes can be read here: http://lists.sonic.net/pipermail/gnusol-users/2008-June/001326.html
And the system can be downloaded here: http://www.nexenta.org/os/DownloadMirrors
ArtistX 0.5Marco Ghirlanda has announced the release of ArtistX 0.5, a full distro that includes most of the free audio, 2D and 3D graphics and video software for the GNU/Linux computing platform. As stated on the distro's page, "ArtistX is a free live GNU/Linux DVD which turns a common computer into a full multimedia production studio".
Main features of this release are:
Download page: http://www.artistx.org/site2/dowload.html
StartCom Enterprise Linux 5.0.2Eddy Nigg has announced the release of StarCom Enterprise Linux 5.0.2, an update to the distro built from the source code of Red Hat Enterprise 5.2. This version comes with several improvements, including performance improvements for virtualization clients, updated software (Firefox 3, OpenOffice.org 2.3, Thunderbird 2 to name a few), and Compiz Fusion.
The full press release can be found here: http://linux.startcom.org/?app=14&rel=29
And the software can be downloaded from here: http://linux.startcom.org/?lang=en&app=15
Canonical Showcases 'Ubuntu Netbook Remix'At the Computex conference in Taiwan, Canonical announced a reworked desktop image of Ubuntu built specifically for a new category of ultra-portable Internet devices netbooks. These are affordable, power-efficient, small screen devices, based on low-power architectures like the Intel Atom processor. This version of Ubuntu allows consumers to send e-mail and instant messages, and to surf the Internet with small and lightweight devices.
Ubuntu Netbook Remix is built to provide a great user experience leveraging Ubuntu's reputation for delivering operating systems that "just work" in the desktop environment. The Remix is based on the standard Ubuntu Desktop Edition with a faster access launcher allowing users to get online more quickly. It will also enable device manufacturers to get to market rapidly with netbooks. Canonical is also working with ISVs to ensure that popular desktop applications are certified on Ubuntu, and will run on the Ubuntu Netbook Remix. Canonical is already working with a number OEMs to deliver the software on devices later in 2008.
Ubuntu Netbook Remix leverages Moblin technologies optimized for the Intel Atom processor. Intel and Canonical are working to create a next generation computing experience across a new category of affordable Internet-centric, portable devices including Mobile Internet Devices (MIDs), netbooks, nettops and embedded devices.
OEMs looking to ship Ubuntu Netbook Remix should contact [email protected]. More information on the product can be found here: www.canonical.com/netbooks
Firefox 3Firefox 3 is officially out with great fanfare and an attempt to enter the Guinness Book for most downloads on a single day, with the amazing mark of over eight million downloads in 24 hours. The Guinness World Records has been asked to certify this result; this may take until sometime in July. Log files are being audited at Open Source Labs at Oregon State University to remove duplicates and failed downloads.
The peak rate claimed was 17,000 downloads a minute. The download servers were overwhelmed in the first few hours, but they were able to meet the demand after some reconfiguration.
A web research firm, Xiti, reported in March that Firefox had about a 30% share of the European browser market. With the latest version out, and many local languages supported, that percentage should climb.
New features of this release includes better overall performance, integrated phishing protection, a smart location bar with better auto complete functions, anti-virus software integration, a re-designed download manager that supports resuming downloads, and much, much more.
One long-sought feature now in FireFox 3 is the ability directly send an e-mail from on-line services such as Yahoo Mail by clicking on a "mailto" link. Previously, "mailto" links would open desktop programs.
In his ZDnet blog, Adrian Kingsley-Hughes ran the SunSpider JavaScript benchmark against FireFox 3 RC1 and RC3 and compared this to his results with Opera 9.5, Safari 1.5, IE 7 and the IE 8 beta. All tests were done on the same hardware. FireFox 3 swept the Javascript benchmark. Here's the test result chart:
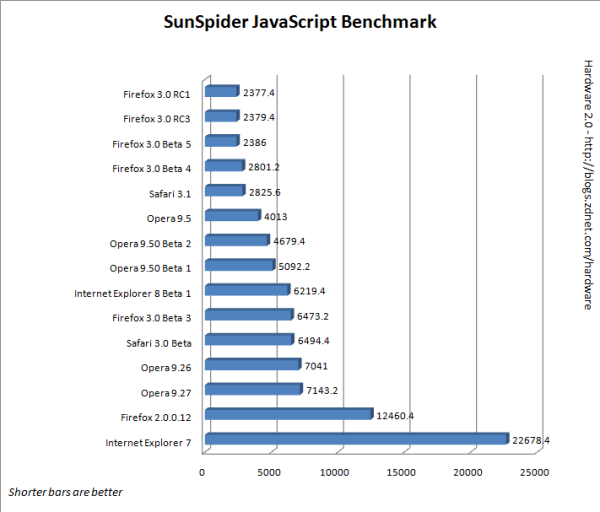
Read all about the new Firefox: http://www.mozilla.com/en-US/firefox/features/
Or download it: http://www.firefox.com/
Mandriva Flash 2008 SpringMandriva announced the launch of the Mandriva Flash 2008 Spring, a new product in the popular "Mandriva Flash" family. It's an 8GB USB flash drive, pre-loaded with the latest release of Mandriva Linux. Differences from the Mandriva Flash to the Flash 2008 Spring version include doubled capacity (from 4GB to 8GB), a migration tool to import settings and documents from Windows, NTFS read and write capacity, plus all the software from the Mandriva distribution.
Owners of the older Mandriva Flash products will have the option to upgrade their Flash to 2008 Spring free of charge, using an upgrade image. More information will be emailed from Mandriva to the previous Flash purchasers, including download links and install instructions.
More information can be found in the press release: http://club.mandriva.com/xwiki/bin/view/Main/Flash2008Spring
Wine 1.0After 15 years of active development, the first stable version of Wine was released on June 17, offering an extensive list of compatible applications, including the long-awaited Photoshop CS2, Microsoft Office, several games and much more.
You can check out a list of compatible applications on Wine AppDB: http://appdb.winehq.org/
More
information about the project on the webpage: http://www.winehq.org
Jaspersoft Business Intelligence Suite v3 Professional EditionJasperSoft just released a new version of its open source business intelligence software- JasperSoft Business Intelligence Suite v3 Professional Edition, this time with easier-to-use Web2.0 interfaces.
New features for this release include:
The full release notes can be read here: http://www.jaspersoft.com/nw_press_jaspersoft_jbis_v3.html
More information (including demos of the system) on Jaspersoft Webpage: http://www.jaspersoft.com/
Subversion 1.5 releasedSubversion 1.5 is now available from the CollabNet-sponsored Subversion open source community. With a special focus on productivity, performance and improved integrations, this release is arguably the most significant Subversion release in the last 4 years. CollabNet Subversion has certified binaries and installers for Linux, Wind0ws, and Solaris.
CollabNet also announced its intention to open source the Subversion Merge Client for Eclipse. This client will provide a rich graphical interface for the latest Subversion 1.5 features including merge tracking and interactive conflict resolution. Try an early version of the Merge Client for Eclipse here: http://www.collab.net/subversion15/
Red Hat's new oVirt Virtualization PlatformIn mid-June announcements at the Red Hat Summit, the company reported on a new stand-alone hypervisor offering and a virtualization management platform. The core technology was developed by the Red Hat's sponsored oVirt open source project.
Red Hat's oVirt management platform delivers a cross-platform management solution allowing customers to centrally manage their entire virtual infrastructure, crossing hypervisor and vendor boundaries to provide a solution that eliminates the complexity of managing virtualization across the enterprise.
oVirt uses Red Hat's open source libvirt management framework that provides hypervisor-agnostic management interfacing, allowing the same tools to manage multiple different hypervisors. Libvirt already supports six hypervisors: Xen, KVM, QEMU, OpenVZ, Linux Containers (LVX) and Solaris LDoms and the list is growing. The libvirt standard has been embraced by leading OEMs, ISVs and operating system vendors.
The beta can be downloaded from http://ovirt.org/.
JBoss in the CloudRed Hat also announced that the JBoss Enterprise Application Platform has become the first supported Java application server available on Amazon EC2, joining Red Hat Enterprise Linux. Developers, enterprises and startups can now use JBoss Enterprise Application Platform on Amazon EC2 for on-demand compute processing. This is currently in Beta.
JBoss Enterprise is the second Red Hat solution to be offered through Amazon EC2. Red Hat Enterprise Linux was made available on-demand on EC2 in November 2007.
Sun VirtualBox Breaks Five Million Downloads; Supports All Major
OSesSun's xVM VirtualBox open source desktop virtualization software has surpassed five million downloads in 18 months. xVM VirtualBox 1.6 is the first free hypervisor to support all major host operating systems, including Mac OS X, Linux, Wind0ws, Solaris and OpenSolaris. The software can be downloaded free of charge at www.virtualbox.com and www.openxvm.org .
xVM VirtualBox software lets users create virtual machines for whichever operating system they choose. The software supports everything from the latest Micr0s0ft Vista and OpenSolaris applications to old Wind0ws 98, OS2 or DOS alongside Apple applications on a new Mac laptop, for example. A 20 megabyte download, xVM VirtualBox software installs in less than five minutes. It is licensed under GPLv2 as well as in its binary form under a Personal Use License.
For additional information visit: http://www.sun.com/virtualbox/ and to download the software from Sun.com go to: http://www.sun.com/software/.
New Red Hat Middleware ArchitectureRed Hat has created a new middleware architecture for their internally-developed applications that further casts a unique Red Hat development strategy.
The new middleware architecture is broadly based on JBoss technology. It includes an Enterprise Service Bus implementing a Services Oriented Architecture (SOA); Seam, of course, the JBoss integration framework; the JBoss Business Process Modeling suite (JBPM); and Drools, the JBoss rules processing environment. The entire stack runs on Red Hat Enterprise Linux, taking advantage of the operating system tools for virtualization, provisioning, configuration, and other functionality. The full technical architecture incorporates Cobbler/Koan for network booting,JBoss SOA, Xen, LVM, Git for distributed, offline source code management, Maven, and more.
According to Lee Congdon, Chief Information Officer at Red Hat : "Cobbler is a provisioning and update server that supports deployments via network booting, virtualization, and reinstalls of existing systems. A significant advantage of Cobbler is that it integrates multiple technologies and reduces the need for the user to understand the details of each. The update features of Cobbler integrate yum mirroring and kickstart."
"Koan, which is an acronym for 'Kickstart over a Network', is an emerging technology that configures machines from remote Cobbler servers. Koan also enables the use of virtualization and re-installs from a Cobbler server. When launched, it requests install information from the server and creates a virtual guest or replaces the machine it is running on. "
Sun Announces Carrier Grade MySQL Cluster 6.3 at NXTcommAt NXTcomm, Sun announced the latest version of its open source database platform for carrier grade telecommunications environments: MySQL Cluster Carrier Grade Edition 6.3. MySQL Cluster is a high availability "shared nothing" database and is at the heart of subscriber data management systems for leading network equipment providers including Alcatel-Lucent, Nokia, Siemens Networks, and Nortel.
Sun Chairman Scott McNealy took the stage at NXTcomm to deliver a keynote address which touched upon the arrival of convergence in the telecom space and the importance of sharing in this new environment. His main charge for network operators was that they should strive harder to package and offer services and content directly to customers, rather than offering them network access and connectivity alone. "Become a destination site, or the destination site will become you," McNealy told the audience.
During a private lunch with press and industry analysts later that afternoon, McNealy expounded upon the potential for open source software to be a "game-changer" in the communications market as it has in other markets. As the industry becomes more software-driven, he said, more players in the space need to take advantage of the technical and cost advantages of free, open source software. McNealy repeated the point many times during his NXTcomm keynote saying, "Did we mention it's free?"
MySQL Cluster 6.3 includes geographical replication, 'five nines' (99.999%) availability, online schema management, and disk-based data capability that allows for storage of both highly transactional and persistent data.
MySQL Cluster is available under the open source GPL license for a range of popular operating systems, including Solaris, RHEL and SUSE Linux, and Mac OS X. Sun also offers commercial licensing, expert consulting, and technical support for MySQL Cluster. More information is available at http://www.mysql.com/cluster/.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/dokopnik.jpg)
Deividson was born in União da Vitória, PR, Brazil, on 14/04/1984. He became interested in computing when he was still a kid, and started to code when he was 12 years old. He is a graduate in Information Systems and is finishing his specialization in Networks and Web Development. He codes in several languages, including C/C++/C#, PHP, Visual Basic, Object Pascal and others.
Deividson works in Porto União's Town Hall as a Computer Technician, and specializes in Web and Desktop system development, and Database/Network Maintenance.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.

By Ben Okopnik
Some months ago, Plat'Home sent us a press release detailing their new product, the Plat'Home Open Micro Server [1]. The writeup seemed promising - lots of keywords designed to ping a geek's heart, warm his kidneys, and titillate his imagination:
> Hi Ben, > Wanted to introduce you to Plat'Home [www.plathome.com], the company > that introduced the fledgling Linux operating system to Japan in 1993 and > is now offering its flagship product, the OpenMicroServer, in the U.S. > Their current customer list is quite impressive * NTT, Japan's largest > company, KDDI, Sony, Fujitsu, and Toshiba, among others. > Plat'Home designed the customizable SSD/Linux operating system for the > OpenMicroServer. OpenMicroServers can be fully administered over the > network, and do not require a connection to display or I/O devices such as > a monitor, keyboard or mouse. > The neat thing about the OpenMicroServer is that it fits in the palm of > your hand, so it's quite portable. And thanks to integrated Power over > Ethernet (PoE) functionality, it can even work without a separate power > supply cable. This means no mangy cables and no need to be next to a > power outlet. Additionally, it does not contain a cooling fan, so it's > quiet, and has the ability to operate in super hot* 104+ > degree* conditions.
Since it sounded like a flexible and interesting gadget, I volunteered to review it (despite already having way too much to do, on the principle that one more task in the huge flood wouldn't be noticeable. :)
When I received it, my first reaction was "Whoa, that's a lot bigger than I expected!" Then I realized that I'd been misled by the hype. I quote, again:
The neat thing about the OpenMicroServer is that it fits in the palm of your hand, so it's quite portable.
Perhaps I'd misinterpreted the above statement, and "fits in the palm of your hand" actually means "in the palm of King Kong's hand" - although it's arguable whether this unit is smaller than Fay Wray's waist. I'd bet on Fay, myself. In reality, it's about half the size of an average laptop, although a bit lighter. Add in the cables and the power adapter (which, despite the claims about Power Over Ethernet (PoE), was indeed required - I, at least, could not get PoE to work), and the weight/size of the unit is something they should have buried in the documentation instead of boasting about it. On the other hand, I may be looking for restraint where only over-enthusiasm abounds...
(Doing a bit more digging on the Net turned up a reference in which they had indeed buried the size data, coyly mentioning a "1U rack mount size". This turns out to be 17.3" x 7.3" x 1.8" inches, a.k.a. 440x184x44mm overall! That same reference uses the term "tiny" in addition to "palm of your hand".)
Next, like a good lad, I attempted to read the documentation. Frankly, I felt like just plugging it in and having a go - this would be a certain sort of test of its own, since a stand-alone computer should work intuitively in many ways - but I was already getting a certain feeling about this, and decided to treat it with maximum latitude and circumspection.
A large number of the initial pages of the printed (actually, photocopied) manual were consumed in warnings. In fact, in a long life of reading equipment manuals for a variety of things - power tools, welding equipment, sailing gear, scuba gear, large power systems, computers, etc. - I've never seen anything like it; there were warnings about leaking capacitors as well as warnings about placing the unit on top of things (I was fascinated and read the details - it seems that it could actually fall and hurt someone. Who would have thought it???) Most people, after reading this part, would be too terrified to ever come near it again... but after many repetitions of a calming mantra, I was able to go on with the process - only to scratch myself on a badly-finished corner of the case. It seems that it's easier to write warnings than to make a metal case that won't attack the user.
Once past that initial hurdle, I started delving into the meat of the docs - which were written in Japanese. Actually, the words used were English, and so was the grammar - but the structure and the phrasing were pure 日本語 (Nihongo). The spelling was excellent, too - and yet, it was nearly incomprehensible; many of the paragraphs were repeated, and the structure was indefinite and vague (there was no hierarchy of any sort.)
However, I had a secret weapon: my wife happens to be of Japanese extraction, and so I had a ready-made translator and partner in exploration of this deep, dark cave. Take that, you manual-manglers! :) She read the Japanese version of the manual, translated it into English, and we went merrily rolling along - except in the many cases where the Japanese didn't make any sense either. Some of which could then be resolved by reading the English version. Woo-hoo, linguistic adventures Indiana Jones style!
To be completely fair about this, it really wasn't about the language - although that by itself would be a "do not pass 'GO', do not collect $200" factor. The problem was that the organization of the manual was so poor that no amount of translation would have made it work. E.g., if you wanted the password for logging in via the serial interface, you had to figure out that you should go forward a few chapters into the Ethernet section and use their web password to do so. On the other hand, if you had the facility for remembering every single fact in a manual, I suppose you could read the entire thing and somehow cross-reference everything in your mind. I will admit that I am explicitly not a paragon of such virtues; if I can't find it in the relevant section pointed to by the index, I tend to take 'strace' (or perhaps 'ldd', or sometimes an axe) to the thing. In this case, Plat'Home had supplied me with a 4" or so Ethernet cable, so I decided to try that route first.
Armed with the minimal amount of information that the two of us were able to glean, I went poking and prodding at the 'soft' end of this box. 'nmap' showed that the appropriate listeners (plus a few others - none of which were documented) were indeed running on it; however, plain old port 80 was not available - theoretically because you'd want to leave it available for standard HTTP service to the world from this box - and 880 was handling web administration logins. A technically odd choice, that, since 880 is still a low (i.e., privileged) port and requires root permissions to access; this is the common reason for using port 8080, or other ports above 1024, for similar situations. By the same token, the pre-allocated IP addresses for this box were a little unusual: "192.168.252.254" constrains you to either have your own address in the xxx.xxx.252.xxx IP range or to use an odd netmask - neither of which is normally necessary or desirable, and is certainly not common practice.
ben@Tyr:~$ nmap 192.168.252.254 Starting Nmap 4.20 ( http://insecure.org ) at 2008-04-14 14:02 EDT Interesting ports on 192.168.252.254: Not shown: 1692 closed ports PORT STATE SERVICE 21/tcp open ftp 23/tcp open telnet 37/tcp open time 111/tcp open rpcbind 880/tcp open unknown
Surfing over to http://192.168.252.254:880, I found a very crude, early-days-of-the-Web page - <FONT SIZE="-1"> tags and all, with no styling or anything resembling an attempt to make it pleasant or professional-looking - redirecting me to the Web interface. Which was just as crude looking, and - crowning touch - with all the link text written in Japanese. The effect was somewhat spoiled by the fact that I could roll over the links and see the names of the links ('password.html', etc.), but except for that, it was a complete and perfect mystery. Doubly so, since I thought I was reviewing a computer. Perhaps I was mistaken, and it was a new puzzle game?
Since the web username was 'root' (at least somewhat startling, in the context of a box the services of which you're supposed to expose to the world), I decided to immediately change the password, and went to the 'パスワード' ('password') link... which contained nothing beyond the page title and a copyright bar. Looking at 'View source' revealed the reason - the page consisted of only the following HTML:
<h1>password</h1> <!--password--> <hr><B>© 2001-2005 Plat'Home CO., LTD., Heart Internet Service</B><BR><FONT SIZE="-1">OpenMicroServer Auto Configuration, Version: 4.00, Last Build: Sun Dec 18 15:47:39 JST 2005</FONT><BR> </body></html>
In other words, the page did exactly nothing useful - there wasn't even any form input HTML that would accept a new password.
Somewhat discouraged by now, I checked out the remaining links, guessing -
and sometimes being wrong about - their functions. The configuration
options for the servers, the DNS config, etc. were mostly either crude,
incomplete, ineffective, or all three. Just for comparison, a typical
Linksys router interface is slick, intuitive, and rather complete in its
functionality; if Plat'Home had simply ripped it off used
it as an inspiration, they would have been much, much better off - even
before they made any changes or improvements. Given the many excellent
examples of router UI out there today, there's literally no reason for
anything this poor.
Just for kicks, I decided to see if the console interface was any better... and couldn't get in, even armed with the root password, and despite the fact that I'd just exchanged some email with their technical contact person.
ben@Tyr:~$ telnet 192.168.252.254 Trying 192.168.252.254... Connected to 192.168.252.254. Escape character is '^]'. Linux 2.6.12 (LinuxServer) (ttyp0) LinuxServer login: root Password: Login incorrect <Ctrl-C> ben@Tyr:~$ ftp 192.168.252.254 Connected to 192.168.252.254. 220 ssd-linux FTP server (tnftpd 20040810) ready. 530 User anonymous unknown. Login failed. Remote system type is UNIX. Using binary mode to transfer files. ftp> user root 331 Password required for root. Password: 530 User root may not use FTP. Login failed.
Contacting Plat'Home's technical experts didn't produce any good results - except, perhaps, a confirmation that I wasn't crazy and the interface was this bad (their attitude seemed to be "That's not a problem, sir - that's a feature!") They were quite nice, and very polite, but an excuse like "you can't log into FTP or telnet via Ethernet, only via the serial interface - that's a security feature!" indicates either a completely wrong-headed idea about what is necessary for a web server, or a stuck excuse mechanism. Again, there's no justifiable reason for either of these in a company in the computer field today.
As a last, vain hope, I tried connecting to the box via a serial interface. Due to my fairly extensive experience with serial/cellphone connections in my early days of mobile Linux connections, I consider myself quite knowledgeable about it... but this box defeated me; I could never get it to talk to me either via 'minicom', 'kermit', or any of my other serial configuration tools. (For the doubting Thomases among us - yes, the port was configured and enabled. Yes, I have serial support compiled in the kernel. Yes, "serial.o" was loaded.) I gave up, and shipped it back to Plat'Home.
In conclusion, I have to say that the Plat'Home OpenBlockS appears to be a prototype that's about 3/4 of the way through development rather than a market-ready product. I'd have enjoyed playing with it if it had been the nifty toy represented by their PR department... but I saw nothing that justified the hype. For the moment, my impression of this product is anything but positive.
Talkback: Discuss this article with The Answer Gang

Ben is the Editor-in-Chief for Linux Gazette and a member of The Answer Gang.
Ben was born in Moscow, Russia in 1962. He became interested in electricity at the tender age of six, promptly demonstrated it by sticking a fork into a socket and starting a fire, and has been falling down technological mineshafts ever since. He has been working with computers since the Elder Days, when they had to be built by soldering parts onto printed circuit boards and programs had to fit into 4k of memory (the recurring nightmares have almost faded, actually.)
His subsequent experiences include creating software in more than two dozen languages, network and database maintenance during the approach of a hurricane, writing articles for publications ranging from sailing magazines to technological journals, and teaching on a variety of topics ranging from Soviet weaponry and IBM hardware repair to Solaris and Linux administration, engineering, and programming. He also has the distinction of setting up the first Linux-based public access network in St. Georges, Bermuda as well as one of the first large-scale Linux-based mail servers in St. Thomas, USVI.
After a seven-year Atlantic/Caribbean cruise under sail and passages up and down the East coast of the US, he is currently anchored in northern Florida. His consulting business presents him with a variety of challenges such as teaching professional advancement courses for Sun Microsystems and providing Open Source solutions for local companies.
His current set of hobbies includes flying, yoga, martial arts,
motorcycles, writing, Roman history, and mangling playing
with his Ubuntu-based home network, in which he is ably assisted by his wife and son;
his Palm Pilot is crammed full of alarms, many of which contain exclamation
points.
He has been working with Linux since 1997, and credits it with his complete loss of interest in waging nuclear warfare on parts of the Pacific Northwest.
Apertium is an open source shallow-transfer machine translation (MT) system. In addition to the translation engine, it also provides tools for manipulating linguistic data, and translators designed to run using the engine. At the time of writing, there are stable bilingual translators available for English-Catalan, English-Spanish, Catalan-Spanish, Catalan-French, Spanish-Portuguese, Spanish-Galician, and French-Spanish; as well as monolingual translators that translate from Esperanto to Catalan and to Spanish, and from Romanian to Spanish. There are also a number of unstable translators in various stages of development. (A list of language pairs, updated daily, is available on the Apertium wiki).
In other words, Apertium is the open-source Systran (the engine that powers Babelfish).
Apertium version 1 was based on existing translators that had been designed by the Transducens group at the Universitat d'Alacant, and funded by the OpenTrad consortium. Subsequent development has been funded by the university, as well as by Prompsit Language Engineering. While Apertium 1 was designed with the Romance languages of Spain in mind, Apertium 2 added support for less-related languages (Catalan-English); Apertium 3 added Unicode support.
Apertium is designed according to the Unix philosophy: translation is performed in stages by a set of tools that operate on a simple text stream. Other tools can be added to the pipeline as required, and the text stream can be modified using standard tools. There is also a wrapper script (called simply apertium) that takes care of most of the details.
$ echo 'Esta es Gloria, mi amiga argentina'|apertium es-en This is Gloria, my Argentinian friend
(That example was picked at random from 'Teach Yourself Spanish Grammar' - translation quality is not always that high, though).
Apertium packages are available for Debian and Ubuntu (apt-get install apertium); packages are not yet available for other distributions, though it has been used successfully on several distributions. The mildly curious may prefer to try the Surf and Translate demo on the Apertium Web site.
I intend to follow this article with articles of a more tutorial nature; the rest of this article is intended to give an explanation of the most common terms in machine translation.
Machine translation systems differ in sophistication, and there are several basic approaches to translation. At the basic level, any translation system has to include dictionary lookup; however, this can also use a stemmer to find the basic form of a word (instead of looking up 'beers' in the dictionary, it looks up 'beer'), or a morphological analyser (which operates much like a stemmer, but also includes grammatical information - Apertium's analyser would return beer<n><pl> from the word 'beers', to tell the rest of the system that the word is a noun, and plural).
Rule-based systems were the first 'real' kind of machine translation system. Rather than simply translating word to word, rules are developed that allow for words to be placed in different places, to have different meaning depending on context, etc. The Georgetown-IBM experiment in 1954 was one of the first rule-based machine translation systems; Systran and Apertium are RBMT systems.
Example Based Machine Translation (EBMT) systems translate using the results of previous translations. Translation Memory systems are the most basic example of EBMT; more complicated TM systems (such as OmegaT), which use techniques such as fuzzy matching to suggest similar translations, are closer to the original idea behind EBMT.
Statistical Machine Translation (SMT) is, at its most basic, a more complicated form of word translation, where statistical weights are used to decide the most likely translation of a word. Modern SMT systems are phrase-based rather than word-based, and assemble translations using the overlap in phrases. Google Translate is based on SMT; there is also an open-source system for SMT called Moses.
Interlingua systems are an extension of rule-based systems that use an intermediate language instead of direct translation. Systems based on Interlingua can then more readily translate between various combinations of languages. OpenLogos is an open-source Interlingua-based machine translator, based on the Logos system; a competitor of Systran.
Transfer-based systems are another approach to rule-based machine transfer, influenced by the Interlingua idea. Instead of using a whole language, an intermediate representation of equivalent pieces is used. This still uses language-pair-specific translation, but the amount of language-specific rules are reduced to a minimum. There are two kinds of transfer-based translation: shallow transfer (syntactic), where words are translated based on combinations of word types; and deep transfer (semantic), which uses a representation of the meaning of each word as a basis for how it should be translated.
Most current machine translation systems are hybrid systems: Moses is primarily SMT, but can use morphological analysers to add extra confidence in translation options; Apertium uses statistical methods for word sense disambiguation.
SMT is the current focus of most serious research in MT, but rule-based systems still have a number of advantages. First and foremost, SMT systems require the availability of a large amount of text in both languages1, which for most language pairs is not available. Secondly, the generated dictionaries contain all likely word combinations for both languages, which both consume a lot of memory and take much more processing time than do the kind of dictionaries used in rule-based systems (which also have the advantage of being useful as human-readable dictionaries - TinyLex is a Java ME program for bilingual dictionaries that uses Apertium data).
Another aspect of SMT that may or may not be a drawback, depending on your perspective, is that they use monolingual models as a way of determining how to combine the phrases they translate. The upside is that, unless they encounter words that don't exist in their dictionaries, the output will be of better quality than with rule-based translation. The downside is that this translation may bear very little relation to the source sentence. With a rule-based system, a bad translation will look like garbage.
The best translations depend on the closeness of the languages involved: all other things being equal, a Spanish - Portuguese translator will give a better translation than a Spanish - English translator. Another factor is the domain: words that could be ambiguous in general use may only have one meaning in a specific context. This is well known, and for this reason, most commercial translation systems provide the ability to choose specific domains, and to specify meanings in a user-defined dictionary that can override the system dictionary.
What they don't provide, however, is a way to specify custom rules.
In the majority of machine translation uses, documents are translated in bulk, and later edited. Human translators are expensive, and machine translation is used to reduce this cost, or even to remove it entirely. In the majority of cases, the human editor will be expected to follow an in-house style guide; even if the translation is accurate and clear, it would most likely still require editing to conform to this style guide. Even if the translator can't give better accuracy, it can still reduce expense by reducing the amount of editing a document requires.
The usual solution to this is to combine translation memory with automatic translation. A better solution would be to combine translation memory with a fully customisable machine translator - an open source machine translator.
SMT is starting to be used by companies who seek to provide 'bespoke' machine translators with example-based features, which can adapt as corrections are made to the translation. However, as the selection of a phrase is based on the amount of occurrences, the same correction has to be made a number of times - potentially hundreds or even thousands of times.
Consider this example:
Wolę piekło chaosu od piekła porządku.2
In Polish, the preposition 'od' means 'from', with a few exceptions. The above sentence is one example of such an exception:
I prefer the hell of chaos to the hell of order.
Writing a rule in Apertium to say that the preposition 'od' is 'to' following the verb 'woleć' is quite simple, and takes a lot less time than does writing enough examples for an SMT-based translator to infer the same, and doesn't carry the risk of harming cases that were previously handled correctly.
I hope I've made some of you more interested in Apertium: my next article will be a tutorial covering the creation of morphological analysers in Apertium. Anyone too impatient for that can find more information on the Apertium wiki, and there are usually a number of people available on #apertium on irc.freenode.org available to answer questions.
1 In a paper from Google Research, they describe a method of overcoming this problem by using the statistical translation probabilities of multiple languages (which they have used recently, in their newest language additions); essentially, cross-referencing multiple bilingual dictionaries to create new ones. The tool that does this in Apertium is called apertium-crossdics. (The paper also suggests that "One solution is to create such parallel data by automatic translation and then retaining reliable translations by using confidence metrics", which is a bit like saying that infinite monkeys can at least translate the works of Shakespeare).
2
Wisława Szymborska,
Możliwości
(English)
Talkback: Discuss this article with The Answer Gang
Jimmy has been using computers from the tender age of seven, when his father
inherited an Amstrad PCW8256. After a few brief flirtations with an Atari ST
and numerous versions of DOS and Windows, Jimmy was introduced to Linux in 1998
and hasn't looked back.
In his spare time, Jimmy likes to play guitar and read: not at the same time,
but the picks make handy bookmarks.
 Jimmy is a single father of one, who enjoys long walks... Oh, right.
Jimmy is a single father of one, who enjoys long walks... Oh, right.
By Joey Prestia

Linux has the ability to use access control lists at the file level. This allows file owners and system administrators to define who has access and what level of access they have beyond the level of fliesystem permissions.
Assume that a company has a team of employees working on a project. Each employee, depending on their role and level of responsibility, needs a different set of permissions; this can be implemented via access control lists (another, and perhaps better term is discretionary access control lists.) In the event that the material is classified to some but not to all, these ACLs make things easy for the company in that security can be handled without the need to involve more people other than those directly concerned.
ACLs are available with the ext3 file system. By default, Red Hat Enterprise Linux 5 sets the capability for ACLs on all the ext3 partitions at install time. What this means is that if you create a new partition that was not in existence at install time and try to use access control lists on it, you can't: you will have to add the mount option ACL in the /etc/fstab file to make that feature available.
Most relevant commands support ACL lists, but some don't; if you're in doubt, you should check the man pages to make sure. "tar", for example, does not support access control lists.
Let's walk through setting up and using ACLs to get the feel of the fine grained-level of control that is available by using access control lists. Since I have unpartitioned space on this drive, I will run through the process of setting up ACLs on the new partition:
[root@localhost ~]# fdisk /dev/hda [root@localhost ~]# partprobe [root@localhost ~]# mkfs.ext3 -L /srv/data /dev/hda10
Next, I need to edit the /etc/fstab file and add the new partition and the mount options for access control lists.
[root@localhost ~]# vi /etc/fstab LABEL=/ / ext3 defaults 1 1 LABEL=/boot /boot ext2 defaults 1 2 devpts /dev/pts devpts gid=5,mode=620 0 0 tmpfs /dev/shm tmpfs defaults 0 0 LABEL=/home /home ext3 usrquota,grpquota 1 2 proc /proc proc defaults 0 0 sysfs /sys sysfs defaults 0 0 LABEL=/tmp /tmp ext3 defaults 1 2 LABEL=/usr /usr ext3 defaults 1 2 LABEL=/var /var ext3 defaults 1 2 LABEL=SWAP-hda3 swap swap defaults 0 0 LABEL=/srv/data /srv/data ext3 defaults,acl 1 1
After that, I'll make a directory and mount our new partition.
[root@localhost ~]# mkdir /srv/data [root@localhost ~]# mount -a
Now, I'll add a group called "programming", and create several users belonging to that group: "teamleader", "prog1", "prog2", and "tech". I'll also need to change the ownership and permissions on this directory to those appropriate for our new group. As a result, files created in this directory will belong to group "programming".
[root@localhost ~]# groupadd programming [root@localhost ~]# chown .programming /srv/data [root@localhost ~]# chmod 2770 /srv/data [root@localhost ~]# useradd teamleader -G programming [root@localhost ~]# passwd teamleader [root@localhost ~]# useradd prog1 -G programming [root@localhost ~]# passwd prog1 [root@localhost ~]# useradd prog2 -G programming [root@localhost ~]# passwd prog2 [root@localhost ~]# useradd tech -G programming [root@localhost ~]# passwd tech [root@localhost ~]# cd /srv/data [root@localhost data]# ls lost+found [root@localhost data]# su teamleader [teamleader@localhost data]$ [teamleader@localhost data]$ touch project [teamleader@localhost data]$ chmod 700 project
At this point the teamleader has created a project and restricted access to it via the filesystem.
The command "getfacl" shows the ACL/permission information for a specified file or directory:
[teamleader@localhost data]$ getfacl project # file: project # owner: teamleader # group: programming user::rwx group::--- other::---
This command sets access controls. There are three fields on the command line that you need to be aware of:
identifier:user/group:permissions
The identifier can be expressed as:
u - will affect the access rights of the specified user g - will affect the access rights of the specified group o - will affect the access rights of all others m - will affect the effective rights mask
user/group is the intended username or groupname, which can also be expressed as a UID or GID.
permissions are:
r or 4 - read access w or 2 - write access x or 1 - execute permission - or 0 - no permissions
Of course permissions may be combined such as r-x or 5 depending on what you want. Using the command in its simplest form looks like this:
setfacl [options] identifier:user/group: permissions filename
[teamleader@localhost data]$ setfacl -m u:prog1:rwx project [teamleader@localhost data]$ setfacl -m u:prog2:rw- project [teamleader@localhost data]$ getfacl project # file: project # owner: teamleader # group: programming user::rwx user:prog1:rwx user:prog2:rw- group::--- mask::rwx other::---
At this point we promoted our programmers permissions: "prog1" can now read, write, and execute; and "prog2" has read and write access. Notice also that the output from "getfacl" now has a "mask" field at the bottom: the mask is a maximum rights level and can be used to immediately restrict the permissions on this file. In addition, if you do an "ls -l", the listing will show a "+" at the end of the permissions for each filename that has ACLs enabled:
[teamleader@localhost data]$ ls -l total 13 drwx------ 2 root programming 12288 Mar 19 21:59 lost+found -rwxrw----+ 1 teamleader programming 0 Mar 22 20:30 project [teamleader@localhost data]$
The "programming" group needs at least read permissions on this file, since other programmers will need to see what is in the document. If we do not specify the group explicitly when we execute the "setfacl" command, it is assumed as you can see below:
[teamleader@localhost data]$ setfacl -m g::r project [teamleader@localhost data]$ getfacl project # file: project # owner: teamleader # group: programming user::rwx user:prog1:rwx user:prog2:rw- group::r-- mask::rwx other::---
By changing the mask, I can change the current effective permissions to the most restrictive level as defined by the mask and have those become the effective permissions. Even if a user or group has permissions in excess of what the effective mask is set to, the mask will restrict their effective rights.
[teamleader@localhost data]$ setfacl -m mask::r project [teamleader@localhost data]$ getfacl project # file: project # owner: teamleader # group: programming user::rwx user:prog1:rwx #effective:r-- user:prog2:rw- #effective:r-- group::r-- mask::r-- other::---
If we want to remove one of our programmers - e.g., "prog1" - from the ACL for this project and revert his permissions back to what the group has, this would be done as follows:
[teamleader@localhost data]$ setfacl -x u:prog1: project [teamleader@localhost data]$ getfacl project # file: project # owner: teamleader # group: programming user::rwx user:prog2:rw- group::r-- mask::rw- other::---
The "-x" switch removes the associated user, group, or other, from the associated access control list - so "prog1" now only has group level access (and probably a pay cut to go with it).
What if we were to store our ACL attributes in a file containing the line "u:prog1:rwx"? We could use the "-M" switch to pass the attributes on to a new file.
[teamleader@localhost data]$ touch file [teamleader@localhost data]$ echo "u:prog1:rwx" > acl [teamleader@localhost data]$ setfacl -M acl file [teamleader@localhost data]$ getfacl file # file: file # owner: teamleader # group: programming user::rw- user:prog1:rwx group::rw- mask::rwx other::r--
We have successfully transferred the ACL attributes in the file "acl" to the empty file "file". Did you notice how the effective rights mask jumped up from "rw-" to "rwx"? If you did not want the effective rights mask to change when you modify permissions you could use the "-n" option alongside your other options to prevent it.
To copy a file's ACL to another file you would execute "getfacl
filewith.acl | setfacl -b -n -M - fileneeding.acl" as I will show
below. The last "-" is important; it tells "setfacl" to read the data from
standard input, which is being supplied by the preceding pipe.
[teamleader@localhost data]$ getfacl filewith.acl # file: filewith.acl # owner: teamleader # group: programming user::rw- user:prog1:rwx group::rw- mask::rwx other::r-- [teamleader@localhost data]$ touch fileneeding.acl [teamleader@localhost data]$ getfacl filewith.acl | setfacl -b -n -M - fileneeding.acl [teamleader@localhost data]$ getfacl fileneeding.acl # file: fileneeding.acl # owner: teamleader # group: programming user::rw- user:prog1:rwx group::rw- mask::rwx other::r--
Directories can have a default ACL, which defines the access permissions that files under the directory inherit when they are created. A default ACL affects subdirectories as well as files. First, let's set up a directory with a set of default permissions. Access defaults are created by using the "-d" switch when modifying a directory.
[teamleader@localhost data]$ mkdir work [teamleader@localhost data]$ setfacl -d -m g::r-x work/ [teamleader@localhost data]$ getfacl work/ # file: work # owner: teamleader # group: programming user::rwx group::rwx other::r-x default:user::rwx default:group::r-x default:other::r-x
Observe as I create a child directory below, "work/week1". Notice that "week1" will inherit the default ACL permissions of the parent directory "work":
[teamleader@localhost data]$ mkdir work/week1 [teamleader@localhost data]$ getfacl work/week1/ # file: work/week1 # owner: teamleader # group: programming user::rwx group::r-x other::r-x default:user::rwx default:group::r-x default:other::r-x
Last of all, let's see how these defaults propagate to a simple file created in the "work/week1" directory. I'll show the parent's ACL first, then create the file:
[teamleader@localhost data]$ getfacl work/week1/ # file: work/week1 # owner: teamleader # group: programming user::rwx group::r-x other::r-x default:user::rwx default:group::r-x default:other::r-x [teamleader@localhost data]$ touch work/week1/day1 [teamleader@localhost data]$ getfacl work/week1/day1 # file: work/week1/day1 # owner: teamleader # group: programming user::rw- group::r-- other::r-- [teamleader@localhost data]$ umask 0002
Note that the file was created with an active umask of 0002. This means that the file should have had permissions of 664; instead it was created with default permissions of 644 because of the default ACL on the directory and the inheriting of the ACL from the parent directory.
This is not an exhaustive list of all the possibilities; however, just these basics should be enough to get you started using access control lists. ACLs can be used to regulate permissions for special situations where regular Linux permissions will not quite handle the job; they can also lighten the administrative overhead when project-level managers learn to use them correctly and effectively. In addition, ACLs can be a valuable tool in any administrator's toolbox to help regulate security.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/prestia.jpg)
Joey was born in Phoenix and started programming at the age fourteen on a Timex Sinclair 1000. He was driven by hopes he might be able to do something with this early model computer. He soon became proficient in the BASIC and Assembly programming languages. Joey became a programmer in 1990 and added COBOL, Fortran, and Pascal to his repertoire of programming languages. Since then has become obsessed with just about every aspect of computer science. He became enlightened and discovered RedHat Linux in 2002 when someone gave him RedHat version six. This started off a new passion centered around Linux. Currently Joey is completing his degree in Linux Networking and working on campus for the college's RedHat Academy in Arizona. He is also on the staff of the Linux Gazette as the Mirror Coordinator.
"Anyone who has never made a mistake has never tried anything new." -- Albert Einstein
Let me start with pointers to the two most valuable (in my personal view) resources that I constantly referred to prior to deciding which PCI wireless card would be the best fit for my home system running Fedora Core 5.
URL A: Madwifi Compatible Cards from Netgear
URL B: Comprehensive List of cards from all vendors
Buying a USB-based wireless card, however, was not on my list; after much deliberation, I decided to buy NETGEAR's WG311 card. In hindsight, I do agree that I should have been careful to check (at the above URLs) whether this model/product from NETGEAR had the necessary drivers for the GNU/Linux space. Since it didn't, I ended up having to make it work by using "ndiswrapper".
From the project page, http://ndiswrapper.sourceforge.net:
"Many vendors do not release specifications of the hardware or provide a Linux driver for their wireless network cards. This project implements Windows kernel API and NDIS API within Linux. A Windows driver for wireless network card is then linked to this implementation so that the driver runs natively, as though it is in Windows, without binary emulation."
Nothing against USB wireless cards... but I needed to hook my desktop system to the broadband. Given the physical distance separating the desktop and the broadband tap provided by the local ISP, I did not want to spoil the beauty of our home with internal wiring exposed all over the place. Who would want to do that?
From the project page of madwifi, http://www.madwifi.org:
madwifi.org is [...] a team of volunteer developers working on Linux Kernel drivers for Wireless LAN devices with Atheros chipsets. We currently provide two drivers, MadWifi and ath5k.
Well, that's direct - and I should have realized that madwifi drivers support Atheros chipsets but not the chipsets (from Marvell) that come with NETGEAR's WG311 PCI wireless card. It did occur to me - as soon as I started having trouble while configuring the wireless card.
As soon as I got the PCI wireless card, I started with configuration tasks after ensuring it was physically installed in the PCI slot.
Starting from http://madwifi.org, I downloaded the sources of 0.9.4 (latest version as of this article) and followed the steps available at the Madwifi Newbie Doc. The first part was typical of installing software from sources:
[root@thinnai /tmp/madwifi]# ./configure && make && make install [root@thinnai /tmp/madwifi]# modprobe ath_pci
Then, I proceeded to create the interface - and this is where things started turning ugly (to be correct, where there was careless blunder on my part).
[root@thinnai ~]# wlanconfig ath0 create wlandev wifi0 wlanmode sta wlanconfig: ioctl: No such device
At this point, I referred back to the URLs mentioned at the beginning of this article. Both had clearly indicated that the PCI wireless card, WG311 from NETGEAR, is supported by "ndiswrapper" - but not "madwifi".
I knew of only one remaining way of configuring my PCI wireless card - i.e., by using ndiswrapper. After reading through the basic documentation available at the ndiswrapper wiki, I understood that this is done as a two-step process:
First, install ndiswrapper from its sources. Then, download
and install the appropriate Windows driver.
How did I decide which Windows driver to download? Simple - I identified the revision of the chipset available on the PCI wireless card, then just followed these steps listed below:
NOTE: Prior to configuring and installing the PCI wireless card in GNU/Linux, I had installed the drivers in Win2k and found them to be working perfectly.
Here is the Wiki
page detailing the steps for installing ndiswrapper from
sources, including the Windows driver amongst other things.
In these installation steps, it is mentioned that one should try the WinXP driver in preference to the Win2k drivers; under another section ("Install Windows driver"), it is also mentioned that if the Windows driver provided by the vendor worked, that specific driver files can be re-used. These statements had driven me to download the Windows driver from the URL given earlier rather than re-use the driver files from the existing Windows installation.
[root@thinnai:~]#/sbin/lspci|grep -i wireless 01:07.0 Ethernet controller: Marvell Technology Group Ltd. 88w8335 [Libertas] 802.11b/g Wireless (rev 03) [root@thinnai ~]# lspci -n|grep 01:07 01:07.0 0200: 11ab:1faa (rev 03)
From the ndiswrapper project Wiki, I downloaded the tarball of the latest release. As it had been my regular practice, prior to installation, I read through the documentation carefully (at least the initial sections of the INSTALL file.) In this case, the initial steps to compile the sources and install the binaries were quite straightforward.
With current working dir as /root/ndiswrapper-1.20, I executed the following commands:
[root@thinnai ndiswrapper-1.20]# make && make install [...] *** WARNING: Kernel is compiled with 4K stack size option (CONFIG_4KSTACKS); many Windows drivers will not work with this option enabled. Disable CONFIG_4KSTACKS option, recompile and install kernel [...]
If you happen to see warnings at the end of "make" similar to the above, you can safely ignore them. This warning has not affected the functionality of the wireless card, at least for the PCI wireless card with the chipset revision shown above.
As discussed previously, I downloaded the Windows driver and religiously followed the instructions in the "Install Windows driver" section of the INSTALL file. After extracting the Windows driver to another directory, I went through the following steps:
[root@thinnai ndiswrapper-1.20]# ls ../ENLWI-G_Driver_Utility_98SE-ME-2000-XP/V1.10/DRIVER/Windows\ XP/
Mrv8000c.cat Mrv8000c.inf Mrv8000c.sys
[root@thinnai ndiswrapper-1.20]# cp ../ENLWI*/*{inf.sys} . # Copy the drivers into the current dir
[root@thinnai ndiswrapper-1.20]# ndiswrapper -i Mrv8000c.inf # Install them
Installing mrv8000c
Forcing parameter AdhocGMode|1 to AdhocGMode|0
Forcing parameter AdhocGMode|1 to AdhocGMode|0
[root@thinnai ndiswrapper-1.20]# ls /etc/ndiswrapper/ # Confirmed the installation
mrv8000c
[root@thinnai ndiswrapper-1.20]# ls /etc/ndiswrapper/mrv8000c/
11AB:1FAA.5.conf 11AB:1FAB.5.conf mrv8000c.inf mrv8000c.sys
[root@thinnai lnx_data]# ndiswrapper -l
Installed drivers:
mrv8000c driver installed, hardware present
The next step is to configure the wireless interface, scan for access points, and attach to one. Prior to these steps, though, I checked the version of wireless tools:
[root@thinnai ~]# rpm -qa | grep -i wireless
wireless-tools-28-0.pre13.5.1
[root@thinnai ~]# iwconfig --version
iwconfig Wireless-Tools version 28
Compatible with Wireless Extension v11 to v19.
Kernel Currently compiled with Wireless Extension v19.
wlan0 Recommend Wireless Extension v18 or later,
Currently compiled with Wireless Extension v19.
After the confirmation, I wrapped the following commands up in a shell script to ease the wireless card driver installation and activation after every system boot (as a step forward, I could have re-written the script so that the wireless interface is activated from /etc/init.d):
echo "Activating wireless interface on your computer ..." modprobe ndiswrapper echo "====================================================================" echo "Status of your ethernet interfaces ... " /sbin/ifconfig echo "====================================================================" echo "Activating the wireless interface ... " /sbin/ifconfig wlan0 up echo "====================================================================" echo "Status of your wireless interfaces ... " /sbin/iwconfig echo "====================================================================" echo "Scanning your wireless networks, joining available n/w also ..." iwlist wlan0 scan /sbin/iwconfig wlan0 essid default /sbin/iwconfig wlan0 echo "====================================================================" echo "Acquiring IP address for the wireless interface ... " dhclient wlan0
Below, I have listed the commands that I used to verify the status of the PCI wireless interface with ndiswrapper installed and activated. I did this via the "dhclient" command:
Acquiring IP address for the wireless interface ... Internet Systems Consortium DHCP Client V3.0.3-RedHat [...] Listening on LPF/wlan0/00:1e:2a:35:2a:79 Sending on LPF/wlan0/00:1e:2a:35:2a:79 Sending on Socket/fallback DHCPREQUEST on wlan0 to 255.255.255.255 port 67 DHCPACK from 192.168.0.1 bound to 192.168.0.147 -- renewal in 39 seconds.
Results of simple check to validate the connectivity:
[ram@thinnai ~]$ host linuxgazette.net linuxgazette.net has address 64.246.26.120 linuxgazette.net mail is handled by 10 genetikayos.com. [ram@thinnai ~]$ ping -c 5 www.eham.net PING www.eham.net (69.36.242.135) 56(84) bytes of data. 64 bytes from atlanta.eham.net (69.36.242.135): icmp_seq=1 ttl=50 time=297 ms 64 bytes from atlanta.eham.net (69.36.242.135): icmp_seq=2 ttl=50 time=298 ms 64 bytes from atlanta.eham.net (69.36.242.135): icmp_seq=3 ttl=50 time=298 ms 64 bytes from atlanta.eham.net (69.36.242.135): icmp_seq=4 ttl=50 time=298 ms 64 bytes from atlanta.eham.net (69.36.242.135): icmp_seq=5 ttl=50 time=298 ms --- www.eham.net ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 3998ms rtt min/avg/max/mdev = 297.142/298.288/298.837/0.617 ms
Patiently and carefully read through the wireless support URLs (listed in the Intro section of this article) prior to deciding which card to buy. If you have to set up and configure a PCI/USB wireless card in a GNU/Linux environment that isn't supported by madwifi, don't feel let down; ndiswrapper is there to help you out of the quagmire.
I would be happy to hear from the community if there are better and proven ways to set up and configure PCI wireless cards under GNU/Linux!
Talkback: Discuss this article with The Answer Gang

Ram works for an SOC test company in Chennai with the head office based in Boston. In his free time (when his daughter gets busy with her friends), he likes to spend time reading books on world history, solving crosswords, and, if possible, get his hands dirty with FOSS.
"It is the little things that make up great men."
This introduction is about the little things. Things that help ease everyday tasks but go a long way into making you a better user, editor, programmer - a better computer user.
This piece started out as a 'write-while-you-learn' exercise while reading a vim tutorial. As I kept writing, I felt that with a little more work, and some polishing, this could be turned into vim introduction of sorts.
This is not a five minute introduction to vim for a complete newbie. I presume you have used vim before and are comfortable with moving around, and making changes. Although :vimtutor is not a prerequisite to this tutorial, I highly recommend it.
This document contains some mnemonics, and some slightly advanced features of vim that can help the average vim user/programmer increase his/her productivity by leaps and bounds.
I find a large number of people around me who have used vim a few times while writing programs. Very few of them have grown into becoming effective vim users. The majority drop out because of its initially daunting interface. A good number of the interested users switch to emacs, because they think the 'power' just isn't there with vim. I am not saying emacs is bad, but I just cannot stand decisions made on lack of information.
This document is written with an aim to convert the odd "I-just-use-vim-over-ssh" user to a full-fledged user, and to illustrate the kind of power that vim provides.
Most importantly, vim is not just for programmers; it can be used by anybody and everybody who deals with text in any form. Vim runs on many platforms including Mac, Windows, and Solaris, and is a standard on every Linux machine. Someday you might find yourself sitting on a terminal with only vim installed.
Any command mentioned here is to be typed in the normal mode. The normal mode is the mode one gets when he/she presses <Esc> in vim. There are three main modes in vim: insert, normal and visual (vim documentation says there are six BASIC and five Additional modes...)
Commands are generally indented with respect to the rest of the text. Any command prefixed by a ":" is also to be typed in the normal mode, with the colon. Of course they have to be suffixed by an 'Enter' or carriage return.
In cases where a command has to be typed in the visual mode, it will be mentioned explicitly.
The commands described here should work with any recent version of vim, or gvim. I used vim 7.0 for this, and some features like omni-completion and spell checking are available only on it. If several commands in this document do not work, you might wish to try :set nocompatible followed by a carriage return or 'Enter' in your vim.
Just in case you are new to vim, or have completely forgotten the vim commands, and are still brave and enthusiastic to try reading this, I won't leave you behind. Here is a five minute tutorial to vim.
Type 'vim' followed by a filename in your prompt to bring up vim.
$ vim filename # Or, for a GUI interface: $ gvim filename
This will launch vim with the default directory in vim set to the directory the terminal was in.
You can quit vim by typing
:q # Or, for the 'quit without saving' mode: :q!
Once, in vim, you can move around using h, j, k, and l.
h - left
j - down
k - up
l - right
Try to refrain from using the arrow keys. These keys were chosen, because they lie on the home row and save the user a lot of time, and unnecessary fumbling with the arrow keys. After you get used to them, you'll hate having to use arrow keys in other text editors.
To insert text at a location, hit i. This will put you into insert mode. The bottom left of your screen should read something similar to
-- INSERT --
[ This presumes that 'showmode' has been set. If you don't see the above, and would like to, add 'set showmode' to your ~/.vimrc file. -- Ben ]
Type in text till you are done. Use backspace if necessary. Avoid using delete and the arrow keys. If you are done, or you think you need to navigate elsewhere, hit <ESC>. Control+[ should also do. I do not recommend the second however, since it is present only as backward compatibility on several old machines that did not have the Esc Key.
You are now back into the normal mode. You can move around with h, j, k, l again. That should be just enough. Spend some time trying to get comfortable with it.
Save and exit with
:w followed by :q
or simply :wq
Let's begin!
Several people around me often tell me that their greatest difficulty with a major-mode editor like vim, is that they never know which mode they are in.
If you are one like them, the answer is pretty simple. Vim was not designed to be used the way you are using it. Vim was designed for short bursts of insertion. Vim was designed around the idea that people tend to type text for a much shorter time than they spend reading, editing, and revising it. Therefore if you need to get up for coffee, or pick up the phone, or are done with that sentence of yours, hit the Esc button.
Vim provides several keys to help you get to the right cursor position to insert characters. We list some of the more useful ones here.
i insert BEFORE Cursor
a insert AFTER Cursor (append)
shift+i (or I) insert at BEGINNING of line
shift+a (or A) append at the END of line
Noticing similarities? Good, because that is what vim is about. A lot of vim is actually very intuitive.
Great! So how do you go about creating new lines?
o create a new line BELOW the current line, and put the cursor at the start of
the new line.
shift+o (or O) create a new line ABOVE the current line, and put the cursor at the start of
the new line
Wonderful! I do not have to <End><Enter> or <Home><Shift+Enter>. How do I edit text?
r replace the char at the cursor position and come back into escape mode.
In other words, replace a char
shift+r (or R) go into what people would generally call the replace mode. Vim is pretty
intelligent. Have a look at how the backspace works in this mode.
Ok! How do I remove characters?
x remove char under the cursor. Similar to delete.
shift+x (or X) remove char before cursor. Works like backspace.
Selecting in vim, can be done with the mouse, if mousemodel is set properly. See :help mousemodel on this. But the recommended way of selecting is to use the visual mode.
In normal mode, hit v . You will notice at the bottom left of your screen
-- VISUAL --
or something similar.
Moving around with h, j, k, l will now select text. You can delete (cut) the selection with x, or copy, paste, them with keys y and p. As soon as you have done any of these, you should be out of visual mode. To otherwise exit visual mode, you can hit the magic key, Esc.
y stands for Yank and p for Paste. Try them out. More on this will follow.
With all that copying and pasting, you are bound to make mistakes. So how do you undo? Control+Z? No. In normal mode simply hit u . Are you beginning to see the power of major modes here? Keys are often very short and intuitive.
How do you redo? r? No, both r and R were taken by replace modes. You do Control+R to redo.
How much can you undo? Quite a lot actually. In the more recent versions, you can undo to any point since the current session of vim was started.
The latest version of vim at the time of writing, vim 7.0 even has support for undo branches.
You can say something like
:earlier 10m # or :earlier 2h
and it would take you to 10 minutes or 2 hours ago. (If vim was open two hours ago.)
Similarly :later.
What we have covered so far, are just the mere basics. This is stuff that most people know. If you didn't, you do now! What comes from here on is the important part. Learning to use vim as a Swiss Army knife for text and programming.
In vim, a selection can be copied by yanking, or y. This is different from emacs' yank, which pastes. In vim, the paste command is p. Pasting and yanking can be done into registers too. There are no deletes in vim. Everything goes into the paste buffer - or, optionally, into a register named with a single character from the {a-zA-Z0-9} list.
y : copy selection. (Use visual or implicitly copy like yas to yank a sentence - see
Mnemonics below)
yy : copy current line.
Y : copy current line.
d : delete (cut) selection. Same usage as y.
dd : delete (cut) current line.
D : delete from here till end of line.
p : paste selection (Pasting is intelligent. If you copy a whole line, it will put
it below the current line.) see 'ddp' below in keyboard combos
Note that the scope of the action of Y is different from that of D; indeed, Y = yy. If you want to set it to what would you have expected normally read the section on mapping below.
"fy : copy selection and paste in register f
"fd : delete selection and paste in register f
(This works with "xyy "xY and all other similar things too.)
"fp : paste what is present in registers f.
You can look at the registers by using the ':reg[isters]' command. In your version of vim, uppercase registers may be restricted by default, so I suggest not using them.
[ Using an uppercase register name appends a 'y'ank or a 'd'elete to the existing register content; the lowercase version replaces it. -- Ben ]
The other registers are special, often storing text, or marks (see below) for other commands. Therefore these should not be touched. An exception is the '+' register.
Vim's clipboard is independent of the external OS clipboard. Vim imports the text in the OS Clipboard into the '+' register. In order to paste something copied into another application use the '+' register. Command : "+p
As expected, copying or cutting into that register '+' will write to the OS clipboard. So if you want to copy something into another program, use "+y
Mnemonics are commands to perform common tasks. What separates them from being normal commands is the underlying ability to remember them from the task they do. To understand and use mnemonics well, one must first understand text objects. See :help text-objects, or read the subsection under "text objects" below. As an example of a mnemonic, take 'ctx':
ctx - change till x (deletes from here until first character 'x', and puts you insert mode) dtx - delete till x
There are several objects in vim that act as text-objects: words, sentences, blocks, etc.. Vim gives you the power to use them in selections and edits.
daw - delete a word
dw - delete from here till end of word
daW - delete a Word(includes special chars, except space)
dW - delete from here till end of Word
das - delete the sentence we are in
daB - delete an inner Block of code {}
Rules like the above can be applied in general to text objects:
s - sentence
w - word
W - WORD
t - tag ( 'dat' removes from <xml-style-tag> till </xml-style-tag>
p - paragraph
B - block of code ( '{' or '}' works only for C-style blocks)
Bracket forms:
( or ) - parenthesis ( ... )
[ or ] - [ .. ]
< or > - refers to <....>
{ or } - a { block also referred to by the above b
Quote forms:
Just like the bracket forms
", ', ` - can be used for referring to text-objects delimited by them.
These things can therefore be used in a manner similar to
da<text-object> : delete a text object
di<text-object> : delete the inner part of the text object.
(This leaves the () or the spaces in words or the {} in blocks)
Their use does not end here; remember, vim is intelligent. They can be used during visual selections as well. In visual mode hit as to select a sentence. Similarly a word can be selected with aw or a block in with a '}'.
Read :help text-objects for more info.
Almost every command can be prefixed with a number to repeat it in a sensible way. E.g.,
# Go down 6 lines 6j # Delete the next 10 lines 10 dd
This is a very underused function that can greatly improve text editing ease.
Vim provides you with several one touch commands to get to a particular character on the line. This coupled with a good use of vim's insertion techniques should put you where you want with almost no effort.
We first learn how to move by words, since moving by characters can often be slow and demanding.
(ptca = puts the cursor at)
w - Takes you a word ahead. ptca the start of the
next word. ('W' does nearly the same thing, but for "words"
that may include special characters (excluding 'space'))
e - ptca the end of this word. If the cursor is already
under the end of this word, takes you to the end of the next word.
b - move back a word; ptca the start of the previous
word
Next, it is important to know how to get to particular positions on a line. Important places are the start of the line, and the end of the line.
0 - ptca the start of line
Remember regular expressions? Vim tries to make the learning curve easier. The following two commands should come naturally if you keep regular expressions in mind.
^ - ptca the first non-blank character of line
$ - ptca the end of the line
The following commands are really useful as well. They let you get to the nearest instance of a character on a particular line.
fx - ptca at the next instance (in the forward direction)
of character 'x' in the same line.
Fx - ptca the previous instance of the character
These also form the building blocks whenever generic movement is required - like in macros.
The 'g' commands, as I call them, refer to a useful set of 'goto' commands that ease moving around. Merely stating them should suffice.
1G - takes you the start of the file
0G - to the end of file
A good way to remember this is that '1' often appears before (to the left) of '0' on the number row (above the qwerty row) on a qwerty keyboard.
gD - takes you to the first (intelligent) instance of the word under
the cursor in the same file. It is intelligent, since in a programming
language, it takes you to the definition or the declaration of the function
or variable.
gj - goto next line. (Huh?). This is the same as j when the lines do not wrap.
When the lines do wrap around the editor, hitting j would take you over to the next
new line. gj will take you the same character in the next row. (Try it).
gk - Similar.
(To avoid wrapping do :set nowrap)
Note indeed that the small 'g' is called the extended operator in vim. It performs a lot more than merely goto. Indeed the user can see :help g for more information. I'll mention a few useful ones:
gf - Open the filename under the cursor ga - Print ascii value of character under the cursor. gs - put vim to sleep for 1 second. Of course, like most vim commands, you can prefix this with a number to get a general sleep command.
Marks are a very useful feature in vim. They enable you to mark your current position, and move away for a while. You can then go back to the old cursor position by hitting a couple of keys.
ma - mark current position with letter 'a'.
`a - go back to mark a
'a - put the cursor at the start of line a
:marks to see a list of marks made.
Marks are intelligent. Even if you make edits to the text before the mark, thereby changing its line number or make edits on the line itself (affecting character number), vim will manage the marks aptly. You will still be able to return to your old mark with the same key combination. Note that mark movements are often called jumps.
There are a few registers that are set by default. I list a few helpful ones below:
`` - go back to the last cursor position before a jump.
`. - go back to where the cursor the last time an edit was made.
This puts your cursor at the start of the edit.
'( - go to the start of the current sentence
') - go to the end of the current sentence
'{ - go to the start of the current paragraph
'} - go to the end of the current paragraph
To navigate to line foobar, simply type :foobar or foobarG . E.g., to navigate line 234:
:234 234G
I strongly recommend using the :number, because you will be able to see the line number you are typing.
As always, remember in vim, if you make a mistake in the middle of a command hit <Esc>
Of course, if you have been there before, and go there frequently enough, I would suggest marking it. Even though it does not seem that great a feature, it comes in handy when you have to debug programs.
As mentioned earlier, a design aspect in vim was to allow your hands to stay on the home row. So how do you do it without moving your hands to PageUp and PageDown?
Control+(f/F) move forward a screen (PageDown) Control+(b/B) move backward a screen (PageUp) Control+u moving up half a screen Control+d moving down half a screen
There is one last thing you should know about navigation. In case the line number does not show to the bottom left (ruler is set to off), just hit Control+G. This should show you the line number and some other statistics in the bottom status bar.
Think of Power Keystrokes as combos in an arcade-style fighter game. It helps you do several mundane oft-repeated tasks with a couple of key strokes. The meaning of each of the key strokes is already known, just like light punches and hard kicks. Putting them together in specific ways produces several desirable results. We illustrate a few of them to follow.
xp - switch the current char and the next
ddp - switch the current line and the next
A; - append a semicolon to the end of the line.
>> - increase indent of current line.
<< - decrease indent of current line.
Finding is a relatively simple job in vim. Just hit '/' in normal mode, and start typing. Hit Enter to search. The key n will take you to the next search, and Shift+n or N to the previous.
A very useful tip when it comes to searching is the '#' key and the '*' key. These search for the word under the cursor, backwards and forwards respectively. To sum it up,
/foobar<Enter> search for foobar
n go to the next result
N go to the prev result
# search for the word under the cursor (back)
* search for the word under the cursor (fwd)
The substitute command is slightly more complicated. However, when in the right hands it can prove to be wizardly. The syntax of the substitute command is as follows:
:[range]s[ubstitute]/pattern/string/[options]
The range is a very interesting argument to play around with. Here we take a look at vim's :help range to see what we can do.
Range What it means
------ --------------
{number} an absolute line number
. the current line
$ the last line in the file
% equal to 1,$ (the entire file)
* equal to '<,'> (the Visual area)
't position of mark t (lower case)
/{pattern}[/] the next line where {pattern} matches
?{pattern}[?] the previous line where {pattern} matches
\/ the next line where the previously used search
pattern matches
\? the previous line where the previously used search
pattern matches
\& the next line where the previously used substitute
pattern matches
Most substitution commands in vim are often written as :%s/old_string/new_string, for obvious reasons.
Again looking into vim's help for the options we get (in brief):
Option What it means
------ --------------
c Ask before substitution. (Check)
e Don't cough Error messages if no such pattern is not found.
g Global (replace all occurrences in the line).
i Ignore case.
I Do not ignore case.
n Do not substitute. Only return the number of successful matches.
For, e.g., a substitution of the form
:1,'bs/dog/cat/ceg
would replace dog with cat after checking with you, for all instances in that line, from line 1 to the line where mark was set as b. It will not throw any errors if 'dog' was not found.
See the section on "Dealing with Multiple files" for substituting and searching across multiple files.
Even though this could have been fit into the section on navigation above, I decided to make it another section to emphasise it further.
Vim provides various techniques to the programmer. The most useful one is the jump parenthesis shortcut.
% jumps between matching pairs of parenthesis () {} [] <>. With the match-it addon,
it will jump between matching tags in html files - between the <div ... > and the
corresponding </div>
One might also find the 'goto' command very useful.
gD takes you to the global declaration of the variable or function under the cursor. However, this will only do so in the same file. gF takes you to the filename under the cursor. Very useful for jumping to header files.
Vim also integrates with ctags, in a nice and natural way. However, I suggest that you read the help manual for this.
Folds are a wonderful way to organise and group code. Of course, it can be used for editing text, LaTeX documents, and several other things, but the clarity it gives to code is fascinating.
There are several folding methods available in vim. I shall describe only the manual ones, and briefly mention the rest. More information can be gotten from :help fold .
As with a few other things of this kind, I feel that folds are best illustrated by an example. Pick a text file, preferably a large one, that does not fit on one screen. Open it in vim, and place your cursor anywhere you like. In normal mode, type
zf3j
After you press j, vim will create a fold covering the next 3 lines. How did it happen? Well, zf means to close a fold, and knowing vim's movements 3j is to come down 3 lines. So from the current position to 3 lines down, vim folds.
Vim also supports folding using visual mode. Simply select a piece of text, and type zf. It should fold as well. Another option is to specify a range in command mode. For instance, if you wanted to create a fold from 3 lines above to 101th line, you would do
:-3, 101 fold
and hit enter. From 3 lines above to line 101, vim should have folded. Vim will suitably reverse the range for you if 3 lines above was greater than 101 after prompting. You could have also used markers if necessary.
Vim can also make some smart text selections. Suppose you are writing C code. You can position your cursor on a '{' and hit
zfa}
This will fold till the matching '}'. Of course, as we learnt above you could also use the more natural
zf%
to perform the same operation. Finally, you can also use a search-fold technique. You can hit z/ and start typing for the string required. It will fold from the current line to the first instance it finds the search string. Therefore, typing in
z/SearchString
would fold appropriately.
Like someone once said, folding is only half the fun. At some point, you'll no doubt want to unfold the text. To do this, simply place your cursor on the same line as the fold and type
zo
This will reopen the fold. This will not delete the fold. Type
zc
to close it back up when you are finished. To move between various folds quickly, use
zj for next fold
zk for previous fold
As said before, vim allows nested folds. If you use zo, it will open only the first fold; the other folds will stay closed. The following commands will prove helpful in dealing with nested folds
zO (shift+o) open all nested folds on that line (zc will close them too)
zr open the highest level of folds in the file. For eg, all the first
level folds.
zR open all folds of all levels in the file
zm close all highest level of open folds in the file.
zM close all folds of all levels in the file.
zE delete a fold
Delete a fold with caution. vim's undo and redo features don't apply to folds; if you delete a fold, you can't press u and bring it back, and the . command won't run the last fold command.
How does vim deal with folds when searching for text? It acts as if the fold is not present. If the word is found while searching within a fold, it will open the fold. Vim is untidy with this. It does not close the fold when you move your cursor out. However a quick zm will restore the folds.
Once you close the document you created all the folds in, all the folds will be lost. Therefore, you must ensure to save your folds before you exit. You must also load the saved folds after you open it again. This can be done with the following commands.
:mkview make a foldview
:loadview
You can of course automate this by adding the following to your .vimrc:
au BufWinLeave * mkview
au BufWinEnter * silent loadview
There exist other folding methods like those mentioned before. Notable ones are diff (via 'vim -d file1 file2'), which set only the edited lines unfolded, and indent which folds depending on indent.
Visual mode provides what can be called 3 minor modes.
v - enters visual mode.
Shift+v - enters visual mode, where only lines (in full or none) can be selected.
Ctrl+v - enters rectangular visual (block mode).
Play around with these for a while. This should let you become more adept at using Visual. The rectangular visual mode is very useful in temporarily commenting code, or in removing comments.
Suppose we had a code block like
int main()
{
register int k;
...
...
}
Put your cursor at the start of the main declaration. Hit Ctrl+v followed by 6j. Then hit Shift+i and type //. Finally hit Esc to come out of the visual mode.
This should comment the entire block with C++ style comments.
Vim lets you run shell commands from itself by typing
:! shell-command
With the concept of a GNU-like "one utility per action" system, the concept of filters is inevitable. By using a filter, we can send text in our buffer (screen) to an external command - say 'indent' or 'sort' - whose output is then sent back into vim.
Using the range concept given above, one could write things like
:%!gpg
to encrypt one's message with their personal key.
Here are a couple of other examples
:%!tr a-z n-za-m (This will ROT13 our data :))
:.,+5!sort
As mentioned above in the range section, . represents the current line. A positive number means below, and a negative number means above.
With tools like filters learnt above, we could 'make' our projects with commands like
:!gcc -Wall -g foo.c -o bar
or syntax check them with
:!gcc -fsyntax-only %
Vim however provides its user with a make command. You can set a make program with the command
:set makeprg=gcc\ -g\ %
and subsequently make by doing
:make
It accepts command line arguments, enabling you to do things like
:make all
:make install
The default makeprg is set to 'make' in the directory vim currently is in. This by default was the directory our terminal was in, when vim or gvim was called. See the section on "Browsing files with Vim" below to find out the current directory and to change it.
If there were any errors, vim will display them to you. If you are using a fairly common language, vim can even parse the error file and tell you a whole lot more. Pressing 'Enter' in the error window should by default take you to the first error.
In the case the errors can be parsed, the following should be the holy-grail combinations:
:cc - will show you the current error
:cn - will take you to the next error
:cN - will take you to the prev error
:copen - opens the error window in a small buffer
where you can browse errors. Hit <Enter> to be
taken to that error.
This should make your compile -> edit -> compile cycle a lot easier on you.
Often, programmers or developers have multiple files in their buffers. I assume you know how to split windows, and all that jazzy stuff. If not, you could read the Vim tutorial :help vsplit
From vim7.0 onwards, tabs are supported. Tabs can be opened by
:tabnew file.txt
To cycle through tabs one would use :tabnext (:tabn) and :tabprevious (:tabp). One can by default, also go to the previous/next tab by using Control+PgUp and Control+PgDwn provided of course there are no other open programs mapped to that application. (A common program is gnome-terminal with multiple tabs.)
Another way to open and edit multiple files is the buffer. Any file you open is in your buffer till you close it. To open a file in a buffer simply use the normal edit command
:e foo.txt
For dealing with buffers, one should find the following commands useful:
:bfirst switch to the first buffer
:bn switch to next buffer
:bp switch to prev buffer
:blast switch to the last buffer
:ls list all currently open buffers
:buf foo.txt switch to foo.txt in the buffer
The main power of buffers comes in dealing with them in a batch. Vim has the command bufdo, which allows you to run a command over all the files in your buffer.
:bufdo {cmd}
Quoting the vim Manual,
What this basically does is
:bfirst
:{cmd}
:bnext
:{cmd}
etc ...
When the current file can't be abandoned and the [!] is not present, the command fails. When an error is detected on one buffer, further buffers will not be visited. Unlisted buffers are skipped. The last buffer (or where an error occurred) becomes the current buffer. {cmd} can contain '|' to concatenate several commands. {cmd} must not delete buffers or add buffers to the buffer list.
To search in multiple files one would simply do
:bufdo /searchstring/
To search and replace for example, one might do
:bufdo %s/oldtext/newtext/ge
There are other cool things you could do with buffers. You could backup your entire project into a tarball by doing something like
:silent bufdo !tar -rvf backup.tar %
Of course, the files do not have to be open in vim, you could set the args variable in vim, and use a similar argdo.
For eg. to indent all files in foobar/ one would do
:args foobar/*
:argdo !indent % | update
update writes the file only if changes were made.
Open a directory with 'vim path/to/dir' or from within vim, :e path/to/dir. A file browser opens up that one can use to browse, and make modifications. Use <Enter> to enter a directory, and j, k to move up and down.
The following should be helpful:
d - to make a directory
D - to delete one
R - to rename
You can set the directory vim is in by using the cd command as
:cd path/to/dir
As expected you can use :pwd to find out the present directory vim is in.
Having the netrw plugin installed, allows one to access and edit files on a remote machine as well, through protocols like ssh and ftp.
Mapping commands and abbreviations are an essential part of the programmer's lifeline in vim.
Commands can be mapped as follows:
:map <keystrokes> command-to-be-executed
This will map it in both modes. Use nmap if you want to map it only in the normal mode and imap for the insert mode.
As an example, one might consider
:nmap \cc !gcc\ -g\ %
This would mean typing \cc (quickly) in the normal mode would execute the gcc compilation on the current program with debugging enabled.
Abbreviations are really useful things to have in one's armory. They let you substitute a larger word for a smaller one, or fix your common mistypes. An example should state this clearly enough:
:iab cs Computer Science. :iab mroe more
This would replace 'cs ' (followed by the space) with Computer Science every time I type it, and replace 'mroe' with 'more'. The i stands for insert mode, and the ab for abbreviate. One could do :ab as well, though it is not recommended. (It might substitute one of your \cs commands with '\Computer Science'.)
To unset the above mapping or abbreviation simply type
:unmap \cc or
:unab cs
respectively.
If you want these abbreviations or mappings to remain over various uses of vim, simply put them in your '~/.vimrc'.
As a final example, let us take the remapping of Y to the more intuitive way of using it. You would do
:map Y y$
for this session, and to store it permanently, append
map Y y$
to your '~/.vimrc'.
These are amazingly powerful tools to help you automate your work. It is like a writing a program to help you do some word processing, without having to learn another programming language.
Imagine the power you'd have if you could write programs with vim keystrokes to process text. This is precisely what Macros allow you to do. Macros take a set of keys as input from you and store them in a register of your choice. (Yes, this is the same set of registers you copy into and paste from, so don't accidentally overwrite them). You can then run the command specified by the keys in that register.
The syntax for declaring macros is:
qx<set of commands>q
(The second q has to be hit in the normal mode only.)
This stores the set of commands in register x. To run it simply type @x. @@ runs the last run macro.
Macros are best illustrated with an example. Suppose you have a table, the field delimiter being ':'. An example is shown below:
Name Age Fav. Animal
Bob : 24 : Duck
Harry : 18 : Tiger
John : 36 : Dog
... : .. : ....
Suppose the list is very long consisting of 50 or so names. Your job is to extract everybody's favourite animal and put them in a list.
Of course you could use sed, but you could do it using macros with ease as well. To do so you would do the following:
If you now type :regs you will see the following in register a:
2f:wyawmf0G0^[`fj0
(<Esc> has been replaced by ^[.)
Now to run this macro simply put your cursor on Bob, and do @a. It should perform the macro and leave you at the beginning of Harry. You can repeat it once again with @@ or simply with a full stop, . (repeat last command). To repeat it several times you could say 50@@, which would repeat it 50 times.
If you found this macro very useful, you could copy it into your .vimrc, replace ^[ with <Esc> and map it to a keystroke. As an example, the above macro would transform to
" Collect all the animals at the end of the file nmap \fa 2f:wyawmf0G0<Esc>`fj0
Macros are terribly underused. Learn to use them effectively.
Vim now supports omni-completion as well as intelligent buffer completion. The following commands should sum this up:
Ctrl-n - complete (a small popup should appear. You can browse this with
Ctrl-n and Ctrl-p. Simply continue typing when done.
Ctrl-x f - complete this filename.
Ctrl-x i - complete from included files.
With Vim 7.0, Vim now supports built-in spellchecking. To enable it simply type
:set spell
and to disable
:set nospell
You can navigate spelling errors by using ]s and [s . You can correct them by hitting z= . This will pop up a list of possibilities that you can choose from.
This section simply describes a list of common settings that people might find useful. You can see my .vimrc to look at what I use.
Options are set to true using :set option , unset (set option to false) using :set nooption and set to other values using :set option=value. You can invert an true/false option by using :set invoption.
Options often have shorter names that enable you to type them faster. An example would be 'ft' for filetype, enabling you to do :set ft=value instead of the longer :set filteype=value
autoindent - automatically indents your cursor on the new line, depending on where
this line started.
smartindent - is smarter than autoindent. Knows to go back a tab, if you have closed
a block using '{' or goes front a tab if you have opened one with '{'.
This is also language specific, and knows the block delimiters for several
languages.
hlsearch - sets highlight of search on or off.
incsearch - sets incremental search on or off. Incremental search is the name
programmers give to "find as you type" search. This is VERY useful.
expandtab - fill tabs with spaces when a tab is hit. The number of spaces depends on
the tabstop option.
showmatch - show matching (), {}, [] when typing. Very useful for programmers.
ft=VALUE - set filetype = VALUE
As an example you could do
:set hlsearch switches hlsearch on
:set nohlsearch switches hlsearch to off
:set invhlsearch inverts hlsearch (which was previously off due to the last
command) to on.
To change file types from 'txt' to 'html' you would do
:set ft=html
and if you still find no syntax highlighting,
:enable syntax
# or
:syntax on
For help on an option, do :help option
There is a very useful option that I often use. I am one of those compulsive <Esc> hitters. If I am decide to change my command, or abort my command, or simply feel itchy I hit the <Esc> button (often more than once). Vim deals with it graciously, and simply beeps, which does not bother me at all. However, in a work situation like the office or the lab, people sitting near you may get irritated with the beep(s). You can tell vim to switch off the sound alert, and switch on a visual one with
:set visualbell
Try hitting two <Esc>'s in a row now. The screen should just flash.
This section lists a few miscellaneous commands that would not fit anywhere else in this document.
Shift+j (or J) - This will bring up the next line and join it to the end of the current one.
Learn to use this well. It is what people in other editors would perform as
<End><Del> . A mnemonic for Join the previous line with current line.
Shift+k (or K) - Displays the man page for word under cursor
~ - Swap Case of character under cursor, and move to the next character.
. - repeat the last command, whatever it is. (The command could be the insertion of a
sentence or even a macro). What most editors would call 'repeat'.
Vim can also increment and decrement numbers for you. This is extremely useful in writing larger more generic macros. As usual, numbers prefixed with a '0' are considered octal; numbers prefixed with a '0x' are considered hexadecimal. Numbers not beginning with a zero, are decimal.
Control+A - Increments the number under the cursor
Control+X - Decrements the number under the cursor
Vim, much like Emacs is an extensible editor. There are thousands of plugins for vim, that make one's life a lot easier. Purely for completeness, I list some of the more popular plugins here
taglist explorer opens a wonderful little function list by your side,
just like an IDE
matchit enables matching of regular expressions using %
gpg encrypts your data with with your private key. Performs
decryption as well.
calendar displays a calendar in your vim window, to which you can
add notes, et al, ala org-mode
minibufexplorer displays all open buffers and tabs on a horizontal list at
the top/bottom of your screen.
tetris yes, with rotating game play and high scores!
Besides all this, there are a lot of programming suites available for the more popular languages like C/C++, LaTeX, Java, Python, Ruby, etc...
There are currently more than 2200 plugins available at http://vim.org, some of which are bound to make your life easier or a little more fun. Taking advantage of such a wealth of hard work and talent is more than just good fun; it makes a lot of sense.
When all said and done, it is up to you to become proficient in using vim. There is no harm in thinking out what is the best way to do something when you do it for the first time. It will save a lot of time in the future. At one point of time, all efficient vim users thought about the commands they were typing. Reflect on it, before it becomes a habit. It might be slow initially, but the effects you reap later on will be very high.
If you are the kind who keeps forgetting which mode insert/normal/visual mode you are in, remember, as mentioned before that vim is meant to be kept in the normal mode. Words are to be inserted in short bursts. As soon as you finish typing/selecting, come back to normal mode, by hitting <Esc>.
Also, remember that vim commands can be repeated by prefixing numbers to the commands. Like 7j or 3w, etc.. This is probably the most underused vim powertool. Write macros that can be repeated too.
Finally, remember to customise your .vimrc with useful functions, macros, abbreviations, and settings. Before hurriedly writing your own plugin, search vim.org. There are lots of plugins that can help improve daily productivity. And yes, do remember that vim's :help is a wonderful piece of documentation.
Good Luck Vimming!
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/srinivasan.jpg)
Pranesh Srinivasan is currently pursuing a B. Tech (and subsequently, an M. Tech) in Computer Science and Engineering at the Indian Institute of Technology Madras. He has been using GNU/Linux for the last two years.
Initiated into Linux by laboratories in his department, he switched voluntarily to GNU/Linux soon after, realising the potential power and control it could give him. Apart from loving to script in python, he loves using vim, LaTeX, perl, git, and Gnome. He dual boots his personal machine with Debian GNU/Linux and Ubuntu GNU/Linux.
His other interests include writing, reading, swimming, playing football, and general mathematics.
These images are scaled down to minimize horizontal scrolling.
Flash problems?All HelpDex cartoons are at Shane's web site, www.shanecollinge.com.
Talkback: Discuss this article with The Answer Gang
 Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
The Ecol comic strip is written for escomposlinux.org (ECOL), the web site that supports es.comp.os.linux, the Spanish USENET newsgroup for Linux. The strips are drawn in Spanish and then translated to English by the author.
These images are scaled down to minimize horizontal scrolling.
All Ecol cartoons are at tira.escomposlinux.org (Spanish), comic.escomposlinux.org (English) and http://tira.puntbarra.com/ (Catalan). The Catalan version is translated by the people who run the site; only a few episodes are currently available.These cartoons are copyright Javier Malonda. They may be copied, linked or distributed by any means. However, you may not distribute modifications. If you link to a cartoon, please notify Javier, who would appreciate hearing from you.
Talkback: Discuss this article with The Answer Gang
More XKCD cartoons can be found here.
Talkback: Discuss this article with The Answer Gang
I'm just this guy, you know? I'm a CNU graduate with a degree in physics. Before starting xkcd, I worked on robots at NASA's Langley Research Center in Virginia. As of June 2007 I live in Massachusetts. In my spare time I climb things, open strange doors, and go to goth clubs dressed as a frat guy so I can stand around and look terribly uncomfortable. At frat parties I do the same thing, but the other way around.

![[cartoon]](misc/ecol/tiraecol_en-274.png)
![[cartoon]](misc/xkcd/exploits_of_a_mom.png "Her daughter is named Help I'm trapped in a driver's license factory.")