
...making Linux just a little more fun!
Jimmy O'Regan [joregan at gmail.com]
(Sorry the subject wasn't more descriptive, but Rick's setup objected to the subject 'Interview with an adware author': 550-Rejected subject: Monitoring/spyware software or removal tools spam.)
http://philosecurity.org/2009/01/12/interview-with-an-adware-author
"It was funny. It really showed me the power of gradualism. It's hard to get people to do something bad all in one big jump, but if you can cut it up into small enough pieces, you can get people to do almost anything."
[ Thread continues here (5 messages/7.75kB) ]
Ben Okopnik [ben at linuxgazette.net]
Interesting interview with a former adware blackhat.
http://philosecurity.org/2009/01/12/interview-with-an-adware-author
Quote describing adware wars between competitors:
M: [...] I used tinyScheme, which is a BSD licensed, very small, very fast implementation of Scheme that can be compiled down into about a 20K executable if you know what you're doing. Eventually, instead of writing individual executables every time a worm came out, I would just write some Scheme code, put that up on the server, and then immediately all sorts of things would go dark. It amounted to a distributed code war on a 4-10 million-node network. S: In your professional opinion, how can people avoid adware? M: Um, run UNIX.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (3 messages/2.45kB) ]
Rick Moen [rick at linuxmafia.com]
By the way, I've just now reminded Bruce Perens of his kind offer, last February, to let Prof. Moglen know about the latest SugarCRM ploy. I've stressed that we'd be glad to hear any feedback, if Prof. Moglen has time. I'll let LG know if/when I hear back.
To correct my below-quoted wording, strictly speaking, SugarCRM's latest licensing doesn't literally replicate the "_exact same_ badgeware clause" as in the prior proprietary licence, but it's really close: As written, the licensing ends up requiring derivative works to display the firm's trademarked logo or equivalent text (if technology used doesn't support displaying logos) on _each and every user interface page_ of SugarCRM's codebase that the derivative uses.
----- Forwarded message from Rick Moen <[email protected]> -----
Date: Mon, 12 Jan 2009 07:52:26 -0800 From: Rick Moen <[email protected]> To: [email protected] Subject: Re: Courier vs Dovecot for IMAPQuoting Daniel Pittman ([email protected]):
> Jason White <[email protected]> writes:
> > Zimbra is distributed under the Yahoo Public Licence, which isn't > > listed on the OSI Web site.
That's because it's proprietary -- and because Zimbra (now Yahoo) deliberately avoided submitting it for OSI certification, knowing it would be denied.
> It is basically the MPL, and reasonably free, from my research.
It's a "badgeware" proprietary licence that deliberately impairs third-party commercial usage through mandatory advertising notices forced on third parties at runtime for all derivative works, one of a series of such licences produced by Web 2.0 / ASP / Software as a Service companies that carefully avoid seeking OSI licence certification, because they know they can't get it. Non-free.
In YPL's case, the clause that makes it non-free is 3.2:
3.2 - In any copy of the Software or in any Modification you create,
You must retain and reproduce, any and all copyright, patent, trademark,
and attribution notices that are included in the Software in the same
form as they appear in the Software. This includes the preservation of
attribution notices in the form of trademarks or logos that exist within
a user interface of the Software.
> OTOH, not all components of Zimbra are covered under it, so the whole > thing is kind of non-free, depending on your tastes. > > I believe the entire OS edition is freely available, though.
This is a very typical marketing tactic for badgeware: There is a "public licence" (badgeware) version to entice new users, that's left buggy, feature-shy, and poorly documented. If those users then try to submit bugs, or request fixes, or inquire about customisations, the sales staff then launches an all-out effort to upsell them to the "commercial version". (***COUGH*** SugarCRM ***COUGH***).
----- End forwarded message ----- ----- Forwarded message from Rick Moen <[email protected]> -----
[ ... ]
[ Thread continues here (1 message/16.42kB) ]
J.Bakshi [j.bakshi at icmail.net]
Hello list,
Has one any faced the problem with latest rootkit hunter ( 1.3.4 ) ? I have upgraded the rootkit hunter to 1.3.4 and after that it reports a huge warning. I don't know if the Warnings really indicate any hole in my system or it is just the rootkit hunter it self which creates false alarm. Below is the scan report. Any idea ?
[ ... ]
[ Thread continues here (2 messages/6.33kB) ]
Ben Okopnik [ben at linuxgazette.net]
I'm trying to do something rather abstruse and complex with a weird mix of software, hardware, and crazy hackery (too long to explain and it would be boring to most people if I did), but - I need a "magic bullet" and I'm hoping that somebody here can point me in the right direction, or maybe toss a bit of code at me. Here it goes: I need a module that would create a serial-USB device (/dev/ttyUSB9 by preference) and let me pipe data into it without actually plugging in any hardware.
Is this even possible? Pretty much all of my programming experience is in the userspace stuff, and beating on bare metal like that is something I've always considered black magic, so I have absolutely no idea.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (10 messages/16.38kB) ]
Jacob Neal [submacrolize at gmail.com]
Hey...I want to access restricted sites from behind my schools firewall. Both the computers there and my home computer use linux. I might not be able to install software on the school computer. What can I do?
[ Thread continues here (7 messages/5.61kB) ]
[owner-secretary at dcs.kcl.ac.uk]
This address [email protected] is not in use. Please see the website http://www.dcs.kcl.ac.uk/ for contact details of the Department.
[ Thread continues here (2 messages/1.79kB) ]
J.Bakshi [j.bakshi at icmail.net]
Dear all,
Is not vlc has divx support ?
I am runnig debian lenny. The installed vlc is 0.8.6.h-4+lenny2
But when I open an .avi file having divx format the progress bar of vlc only proceds with out any sound or video. Has any one faced the same problem ? Is there any fix for this problem ?
One more thing. The sound output for mp3 files are very very low in vlc.
Thanks
[ Thread continues here (3 messages/2.19kB) ]
Michael SanAngelo [msanangelo at gmail.com]
Hi, I was wondering what are the possibilities of creating and using virtual disks for. I understand I can use dd to create it then mkfs.ext3 or something like it to format the disk. What purpose could they be used for besides serving as a foundation for creating a live cd?
I want to do this from the cli so no gui.
Thanks,
Michael S.
[ Thread continues here (5 messages/7.98kB) ]
Deividson Okopnik [deivid.okop at gmail.com]
Heya
Anyone knows of a good command-line util i can use to rip a dvd to divx?
[ Thread continues here (3 messages/1.19kB) ]
[ In reference to "2-Cent Tips" in LG#158 ]
shirish [shirishag75 at gmail.com]
Hi all, I read the whole thread at http://linuxgazette.net/158/misc/lg/2_cent_tip__audio_ping.html but would like to know how to do two things.
a. How to turn on/make audio beeps louder
b. How do you associate the .wav files so that instead of the audio beeps I get the .wav file.
Thanx in advance.
--
Regards,
Shirish Agarwal
This email is licensed under http://creativecommons.org/licenses/by-nc/3.0/
http://flossexperiences.wordpress.com
065C 6D79 A68C E7EA 52B3 8D70 950D 53FB 729A 8B17
[ Thread continues here (2 messages/2.77kB) ]
[ In reference to "Gnuplot in Action" in LG#158 ]
Ville Herva [v at iki.fi]
Jesus, that must have been an Ethiopian marathon race - alsmost nobody finishing after 3:15. 3:15 is not easy - try it if you like. I could understand the big bunch of people arriving around 2:30 if this was a big country championship, but if there are amateurs present the big bunch would definetely arrive between 3:15 and 4 - even after that.
-- v --
[ Thread continues here (3 messages/2.93kB) ]
Jimmy O'Regan [joregan at gmail.com]
In my article about Apertium, I promised to follow it up with another article of a more 'HOWTO' nature. And I've been writing it. And constantly rewriting it, every time somebody asks how to do something that I think is moronic, to explain why they shouldn't do that... and I need to accept that people will always want to do stupid things, and I should just write a HOWTO.
Anyway... recently, someone asked how to implement generation of unknown words. There are only two reasons I can think of, why someone would want this: either they have words in the bilingual dictionary that they don't have in the monolingual dictionary, or they want to use it in conjunction with morphological guessing.
In general, the usual method used in Apertium's translators is, if we don't know the word, we don't try to translate it -- we're honest about it, essentially. Apertium has an option to mark unknown words, which we generally recommend that people use. It doesn't cover 'hidden' unknown words, where the same word an be two different parts of speech--we're looking into how to attempt that. One result of this, is that before a release, we specifically remove some words from the monolingual dictionary, if we can't add a translation.
Anyway, in the first case, we generally write scripts to automate adding those words to the bidix. One plus of this is that it can be manually checked afterwards, and fixed. Another is that, by adding the word to the monolingual dictionary, we can also analyse it: we generally try to make bilingual translators, but sometimes we can only make a single direction translator--but we still have the option of adding the other direction later. And, as our translators are open source, it increases the amount of freely available linguistic data to do so, so it's a win all round.
The latter case, of also using a mophological guesser, is one source of some of the worst translations out there. For example, at the moment, I'm translating a short story by Adam Mickiewicz, which contains the phrase 'tu i owdzie', which is either a misspelling of 'tu i ówdzie' ('here and there') or an old form, or typesetting error[1], but in any case, the word 'owdzie' does not exist in the modern Polish language.
Translatica, the leading Polish-English translator, gave: "here and he is owdzying"
Now, if I knew nothing of Polish, that would send me scrambling to the English dictionary, to search for the non-existant verb 'to owdzy'.
(Google gave: "here said". SMT is a great idea, in theory, but in practice[2] has the potential to give translations that bear no resemblance to the original meaning of the source text. Google's own method of 'augmenting' SMT by extracting correlating phrase pairs based on a pivot language also leads to extra ambiguities[3])
Anyway. The tip, for anyone who still wants to try it
Apetium's dictionaries can have a limited subset of regular expressions; these can be used by someone who wishes to have both analysis and generation of unknown words. The <re> tag can be placed before the <par> tag, so the entry:
[ ... ]
[ Thread continues here (4 messages/13.08kB) ]
Oscar Laycock [oscar_laycock at yahoo.co.uk]
I recently discovered you could "stringize" a whole C++ or C statement with the pre-processor. For example:
#define TRACE(s) cerr << #s << endl; s
or:
#define TRACE(s) printf("%s\n", #s); s
....
TRACE(*p = '\0');
p--;
(I found this in "Thinking in C++, 2nd ed. Volume 1" by Bruce Eckel, available for free at http://www.mindview.net. By the way, it seems a good introduction to C++ for C programmers with lots of useful exercises. There is also a free, but slightly old, version of the official Qt book (the C++ framework used in KDE), at http://www.qtrac.eu/C++-GUI-Programming-with-Qt-4-1st-ed.zip. It is a bit difficult for a C++ beginner, and somewhat incomplete without the accompanying CD, but rewarding none the less.)
Bruce Eckel adds: "of course this kind of thing can cause problems, especially in one-line for loops:
for(int i = 0; i < 100; i++) TRACE(f(i));
Because there are actually two statements in the TRACE( ) macro, the one-line for loop executes only the first one. The solution is to replace the semicolon with a comma in the macro."
However, when I try this with a declaration. I get a compiler error:
TRACE(char c = *p); s.cpp:17: error: expected primary-expression before 'char' s.cpp:17: error: expected `;' before 'char'
I'm not sure exactly why!?
[ Thread continues here (3 messages/4.81kB) ]
By Deividson Luiz Okopnik and Howard Dyckoff

|
Contents: |
Please submit your News Bytes items in plain text; other formats may be rejected without reading. [You have been warned!] A one- or two-paragraph summary plus a URL has a much higher chance of being published than an entire press release. Submit items to [email protected].
 Linux Foundation makes Kernel Developer Ted Ts'o new CTO
Linux Foundation makes Kernel Developer Ted Ts'o new CTOThe Linux Foundation (LF) named Linux kernel developer Theodore Ts'o to the position of Chief Technology Officer at the Foundation. Ts'o is currently a Linux Foundation fellow, a position he has been in since December 2007. He is a highly regarded member of the Linux and open source community and is known as the first North American kernel developer. Other current and past LF fellows include Steve Hemminger, Andrew Morton, Linus Torvalds and Andrew Tridgell.
Ts'o will be replacing Markus Rex, who was on loan to the Foundation from Novell. Rex will return to Novell as the acting general manager and senior vice president of Novell's OPS business unit.
As CTO, Ts'o will lead all technical initiatives for the Linux Foundation, including oversight of the Linux Standard Base (LSB) and other workgroups such as Open Printing. He will also be the primary technical interface to LF members and the LF's Technical Advisory Board, which represents the kernel community.
"I continue to believe in power of mass collaboration and the work that can be done by a community of developers, users and industry members, I'm looking forward to translating that power into concrete milestones for the LSB specifically, and for Linux overall, in the year ahead," says Ts'o.
Since 2001, Ts'o has worked as a senior technical staff member at IBM where he most recently led a worldwide team to create an enterprise-level real-time Linux solution. Ts'o was awarded the 2006 Award for the Advancement of Free Software by the Free Software Foundation (FSF).
Ts'o is also a Linux kernel developer, a role in which he serves as ext4 file system maintainer, as well as the primary author and maintainer of e2fsprogs, the userspace utilities for the ext2, ext3, and ext4 file systems. He is the founder and chair of the annual Linux Kernel Developers' Summit and regularly presents tutorials on Linux and other open source software. Ts'o was project leader for Kerberos, a network authentication system. He was also a member of the Security Area Directorate for the Internet Engineering Task Force where he chaired the IP Security (IPSEC) Working Group and was a founding board member of the Free Standards Group (FSG).
2009 Linux Collaboration Summit Call for ParticipationThe Linux Foundation has opened registration and announced a call for participation for the 3rd Annual Collaboration Summit which will take place April 8-10, 2009 in San Francisco.
Sponsored by Intel in 2009, the Collaboration Summit is an exclusive, invitation-only gathering of the brightest minds in Linux, including core kernel developers, distribution maintainers, ISVs, end users, system vendors, and other community organizations. It is the only conference designed to accelerate collaboration and encourage solutions by bringing together a true cross-section of leaders to meet face-to-face to tackle and solve the most pressing issues facing Linux today.
The 2009 Collaboration Summit will include:
LF workgroups such as Open Printing and the LSB will also hold meetings.
The Collaboration Summit will be co-located with the CELF Embedded Linux Conference and the Linux Storage and Filesystem Workshop. The winner of the "We're Linux" video contest (see next item) will also be revealed at the Summit, where the winning video and honorable mentions will be screened for the event's attendees.
For more information on the Linux Foundation Collaboration Summit,
please visit:
http://events.linuxfoundation.org/events/collaboration-summit.
To request an invitation, visit:
http://events.linuxfoundation.org/component/registrationpro/?func=details&did=2.
For the first time, the Linux Foundation is inviting all members of the Linux and open source software communities to submit a proposal for its Annual Collaboration Summit, its cornerstone event. CFP submissions are due February 15, 2009. To submit a proposal, visit: http://events.linuxfoundation.org/events/collaboration-summit.
Linux Foundation hosting "We're Linux" Video ContestIn January, the Linux Foundation (LF) launched of its grassroots "We're Linux" video contest. The campaign seeks to find the best user-generated videos that demonstrate what Linux means to those who use it and inspire others to try it. The contest is open to everyone and runs through midnight on March 15, 2009. The winner will be revealed at the Linux Foundation's Collaboration Summit on April 8, 2009, in San Francisco. The winner will be awarded a trip to Tokyo, Japan to participate in the Linux Foundation's Japanese Linux Symposium.
In response to early and resounding community input, the campaign has been renamed from the original "I'm Linux" to the "We're Linux" video contest. This name better expresses how Linux is represented by more than any one person or company.
To become a member of the Linux Foundation's Video forum, view early submissions, or submit your own video for the "We're Linux" contest, visit http://video.linuxfoundation.org.
AMD plans dual-core Neo laptop chipAt CES, AMD announced its platform for ultra-thin notebooks at an affordable price. Previously codenamed "Yukon," the platform is based on the new AMD Athlon Neo processor, ATI Radeon integrated graphics or Radeon HD 3410 discrete graphics. The Neo platform debuts within the HP Pavilion dv2 Entertainment Notebook PC ultra-thin notebook, which is less than one inch thick and weighs in under four pounds. The HP Pavilion dv2 has a 12.1-inch diagonal LED display, near-full-size keyboard, and an optional external optical disc drive with Blu-ray capability.
In mid-January AMD also announced a dual-core Athlon Neo processor, code-named Conesus, which is planned by for mid-2009. The dual-core Neo and supporting chips provide for more operational capability than the current crop of netbooks powered by Intel Atom processors.
Grid.org Open Source HPC Community Hits Visitor MilestoneGrid.org, the on-line community for open source cluster and grid software, announced in January that the site garnered over 100,000 unique visitors in 2008, with the highest traffic generating from the UniCluster, Amazon EC2 and HPC discussion groups.
Launched in November 2007, Grid.org is an open source community for cluster and grid users, developers, and administrators. It is home to the UniCluster open source project as well as other open source projects. For more information, go to http://www.grid.org.
Recent focus on cloud computing and the announcement of UniCloud, UniCluster's extension into the Amazon EC2 cloud, have been popular topics resulting in an increase in traffic to the site.
"Having a vibrant community of users and thought leaders is the cornerstone of any successful open source software project," notes Gary Tyreman, vice president and general manager of HPC for Univa UD. "From our groundbreaking work in Amazon EC2 to the UniCloud offering for Virtual HPC management, Univa UD is committed to initiating and supporting the future of HPC technology, community and open source."
Learn from Leaders in the Storage Industry at the 7th USENIX Conference on File and Storage Technologies (FAST '09)
Join us in San Francisco, CA, February 24-27, 2009, for the 7th USENIX Conference on File and Storage Technologies. On Tuesday, February 24, FAST '09 offers ground-breaking file and storage tutorials by industry leaders such as Brent Welch, Marc Unangst, Simson Garfinkel, and more. This year's innovative 3-day technical program includes 23 technical papers, as well as a Keynote Address, Work-in-Progress Reports (WiPs), and a Poster Session. Don't miss out on opportunities for peer interaction on the topics that mean the most to you.
Register by February 9 and save up to $200!

The 6th USENIX Symposium on Networked Systems Design & Implementation (USENIX NSDI '09) will take place April 22–24, 2009, in Boston, MA.
Please join us at The Boston Park Plaza Hotel & Towers for this symposium covering the most innovative networked systems research, including 32 high-quality papers in areas including trust and privacy, storage, and content distribution; and a poster session. Don't miss the opportunity to gather with researchers from across the networking and systems community to foster cross-disciplinary approaches and address shared research challenges.
Register by March 30, 2009 to save!
 FreeBSD 7.1 Released
FreeBSD 7.1 ReleasedFreeBSD Release Engineering Team has announced FreeBSD 7.1-RELEASE as the second release from the 7-STABLE branch. It improves on the functionality of FreeBSD 7.0 and introduces several new features.
Some of the highlights in 7.1:
FreeBSD 7.1 is available here: http://www.freebsd.org/where.html.
Ubuntu 8.04.02 Maintenance, 9.04 Alpha 3 releases outUbuntu 8.04.2 LTS, the second maintenance update to Ubuntu's 8.04 LTS release, is now available. This release includes updated server, desktop, and alternate installation CDs for the i386 and amd64 architectures.
In all, over 200 updates have been integrated, and updated installation media has been provided so that fewer updates will need to be downloaded after installation. These include security updates and corrections for other high-impact bugs, with a focus on maintaining compatibility with Ubuntu 8.04 LTS.
This is the second maintenance release of Ubuntu 8.04 LTS, which will be supported with maintenance updates and security fixes until April 2011 on desktops and April 2013 on servers.
To get Ubuntu 8.04.2 LTS, visit: http://www.ubuntu.com/getubuntu/download
The release notes, which document caveats and workarounds for known issues, are available at: http://www.ubuntu.com/getubuntu/releasenotes/804
Also, a complete list of post-release updates can also be found at: https://wiki.ubuntu.com/HardyReleaseNotes/ChangeSummary/8.04.2
In January, the Ubuntu community announced the availability of the third alpha release of Ubuntu 9.04 - "Jaunty Jackalope". Read the release announcement and release notes at: https://lists.ubuntu.com/archives/ubuntu-devel-announce/2009-January/0 00524.html.
Red Hat Enterprise Linux 5.3 Now AvailableRed Hat Enterprise Linux 5.3 was released in January. In this third update to Red Hat Enterprise Linux 5, customers receive a wide range of enhancements, including increased virtualization scalability, expanded hardware platform support and incorporation of OpenJDK Java technologies. Customers with a Red Hat Enterprise Linux subscription will receive the Red Hat Enterprise Linux 5.3 update from Red Hat Network.
The primary new features of Red Hat Enterprise Linux 5.3 include:
Red Hat Enterprise Linux 5.3 also includes enhancements spanning many other components; Release Notes document over 150 additions and updates.
Solaris Release adds performance and custom storage appsOpenSolaris release 2008-11 went GA (General Availability release) in early December and also ended the previous support limitation of 18 months. This latest version has improved performance and new tools for building custom storage applications. Sun also released Java 6.update10 with JavaFX extensions for building interactive applications.
For the desktop, OpenSolaris now includes includes Time Slider, an easy to use graphical interface that brings ZFS functionality such as instant snapshots and improved wireless configuration support to all users. To encourage developers to work on Solaris as a development platform, it now comes with D-trace probes that run in Firefox.
For developers seeking a pre-installed OpenSolaris notebook, Sun and Toshiba announced a strategic relationship to deliver OpenSolaris on Toshiba laptops in 2009. Expect additional announcements in early 2009 about model specifics, pricing, and availability.
Charlie Boyle, Director of OpenSolaris Marketing, spoke with LG just after the announcement and explained that ZFS and tools like D-Light (based on D-Trace feature in Solaris) allow seeing what applications are doing in real time and allow developers to rapidly debug and optimize their applications. "OpenSolaris is optimized for performance on the latest systems. Users deploying OpenSolaris will get the most out of their systems with advances in scalability, power management, and virtualization."
Regarding the extension of Solaris support beyond 18 months, Boyle explained, "Customers can get support for as long as they have a contract on their system. We have removed the artificial 18 month window... we will take calls on whatever version a customer is running and get them the best fix for their situation."
In addition to performance gains, other enhancements include:
Bridge Education now offering Ubuntu Authorized coursesBridge Education (BE) has been selected as the first Ubuntu Authorized Training Partner in the US. Beginning in February 2009, BE will begin delivering Ubuntu Authorized courses in select cities nationwide. To find a class nearest you, please contact BE at 866.322.3262 or visit BE on the web at http://bridgeme.com.
Eclipse PHP Dev Tools (PDT) 2.0 ReleasedFully compliant with Eclipse standards, the new 2.0 release of the PHP Development Tools (PDT) enables developers to leverage a wide variety of Eclipse projects, such as Web Tools Project (WTP) and Dynamic Language Toolkit (DLTK), for faster and easier PHP development. PDT is an open source development tool that provides the code editing capabilities needed to get started developing PHP applications. Version 2.0 was available in January.
To support the object-oriented features of PHP, PDT 2.0 now includes:
More info is available here: http://www.eclipse.org/projects/project_summary.php?projectid=tools.pdt
The Java Source Helper plugin was also released in January. Java Source Helper shows a block of code related to a closing brace/bracket if it is currently out of visible range in the editor. The Eclipse Java editor will check to see if the related starting code bracket is out of visible range and, if it is, it will float a window that shows the code related to that starting block. This is useful in deeply nested code. The feature is similar to one in the IntelliJ IDEA IDE.
Cisco's Aironet 1140 Innovates 80.11n Access PointsCisco is now offering an enterprise-class next-generation wireless access point that combines full 802.11n performance with cost-effectiveness. The new Cisco Aironet 1140 Series Access Point supports the Wi-Fi Certified 802.11n Draft 2.0 access point standard and is designed for high-quality voice, video, and rich media across wireless networks.
Cisco delivered the first enterprise-class Wi-Fi Certified 802.11n Draft 2.0 platform in 2007. The Aironet 1140 offers full 802.11n performance and security while using standard Power over Ethernet (PoE). The new access point introduces Cisco M-Drive Technology that enhances 802.11n performance. The Aironet 1140 is the only dual-radio platform that combines full 802.11n Draft 2.0 performance (up to nine times the throughput of existing 802.11a/g wireless networks) and built-in security features using standard 802.3af Power over Ethernet.
ClientLink, a feature of Cisco M-Drive Technology, helps extend the useful life of existing 802.11a/g devices with the use of beam forming to improve the throughput for existing 802.11a/g devices and reduce wireless coverage holes for legacy devices.
Miercom, an independent testing and analysis lab, tested ClientLink and showed an increase of up to 65 percent in throughput for existing 802.11a/g devices connecting to a Cisco 802.11n network. Unlike other solutions that do not offer performance improvements for legacy devices, ClientLink delivers airtime connectivity fairness for both 802.11n and 802.11a/g devices. For the complete Miercom testing methodology and results, download the ClientLink report at: http://www.cisco.com/go/802.11n/
Learn more about the Cisco Aironet 1140 Series Access Point and Cisco
M-Drive Technology in a video with Chris Kozup, Cisco's senior manager
of mobility solutions.
More information at http://blogs.cisco.com/wireless/comments/cisco_taking_80211n_mainstream_with_aironet_1140.
XAware Releases XAware 5.2XAware has released XAware 5.2, an open source data integration solution for creating and managing composite data services. Working with its user community, XAware has included upgrades that make it easier to design and deliver data services for Service-Oriented Architecture (SOA), Rich Internet Applications (RIA), and Software as a Service (SaaS) applications.
The most notable addition to XAware 5.2 is the data-first design feature. Leveraging two important aspects of the Eclipse Data Tools Project, Connection Profiles and Data Source Explorer, XAware users can now create data services by starting with data sources. This option, often known as bottom-up design, is an ideal fit for data-oriented developers and architects, especially those who need to combine data from multiple sources. XAware also gives developers the option of starting the design process with XML Schemas, an approach known as top-down design.
XAware has also introduced a new service design wizard that enables new users to quickly build and test services with relational data sources. Additional enhancements include a new outline view, improved search functionality, greater run-time query control and updated support.
XAware 5.2 is available for free use under the GPLv2 license and via a commercial license. Services and support subscriptions are also available for purchase from XAware, Inc.
Organizations are encouraged to take advantage of XAware's QuickStart program, which includes training, consulting services, and an initial period of active support from the XAware team. Starting at just $750, QuickStart helps companies quickly start building composite data services for SOA, RIA and SaaS projects.
For more information and to download XAware 5.2, please visit: www.xaware.com.
Jaspersoft updates its BI Suite Community EditionIn December, Jaspersoft upgraded its Business Intelligence Suite v3 in both the Community and Professional Editions. The new release includes advanced charting and visualization capabilities that supplement the dynamic dashboards and interactive Web 2.0 interfaces introduced earlier.
Specific features include new built-in chart types, the ability to create and apply chart themes to customize the detailed appearance of charts, and easy integration with third-party visualization engines.
Developers can use the new chart theme capability available in Jaspersoft v3.1 to change the overall appearance of built-in charts without having to write chart customizers or use an extensive set of chart properties. Other features available in Jaspersoft v3.1 include the recently announced certification for Sun's GlassFish application server, and Section 508 compliance for U.S. government agencies.
Additional enhancements now available in Jaspersoft v3.1 include:
Jaspersoft's BI Suite delivers on the promise of "Business Intelligence for Everyone" by using Web 2.0 technologies coupled with advanced metadata functionality. It includes an interactive Web 2.0 interface based on an AJAX framework, dynamic HTML, and other technologies that deliver the ability to mash-up business intelligence features to provide a seamless, cross-application, browser-based experience. Jaspersoft makes it easy for anyone to build and update dashboards in real-time, drag and drop information from multiple sources, and build queries and reports with the click of a mouse.
Netbook Features Bootable OS on USBEMTEC has announced its Gdium netbook computer which boasts a compact size and light weight with 512 MB of RAM, a 10-inch screen size and a full keyboard.
Among the open source applications included with Gdium are: FireFox browser, Thunderbird e-mail client, Instant Messaging, VoIP, Blog editor, audio/video players, security utilities, as well as the Open Office suite of word processing, spreadsheets, and presentations.
What makes Gdium unique is the G-Key, an 8 or 16 GB bootable USB key on which the Mandriva Linux operating system, applications, and personal data are stored. The G-Key allows each user to store their personal info and preference securely, without leaving a trace on the computer.
The Gdium will retail for under $400 and comes in 3 colors - White, Black, and Pink. For more info, go to: http://www.gdium.com
Gdium.Com is also hosting the One Laptop Per Hacker (OLPH) program.
The OLPH Project provides a free infrastructure to individuals who want to develop software for the Gdium platform. Gdium software can be freely modified, adapted, optimized, or replaced; the user can download and install new solution packs and freely modify most of it.
All interested developers can purchase an early release Gdium but must take into account that these may have some some bugs and known issues. OLPH Project members get one extra Gkey.
Openmoko Demos Distros on Open Mobile PhoneAt the CES show in early January, Openmoko Inc, maker of fully open mobile phone products, demonstrated several Linux distributions running on the FreeRunner mobile hardware platform. These included the Debian distro, community-driven FDOM, QT by Trolltech (recently acquired by Nokia), and Google's Android.
In a video shot at CES 2009, William Lai of Openmoko discusses the power of Open Source community-driven development for new mobile applications and devices. Click here to watch: http://www.youtube.com/watch?v=8R4KvJv6xSE
In addition to its role as a mobile phone, developers are embracing the open hardware, open software, and open CAD of the Openmoko platform to create new embedded consumer products.
Openmoko is both a commercial and community driven effort to create open mobile products that consumers can personalize, much like a computer. Openmoko is dedicated to bringing freedom and flexibility to consumer electronics and vertical market devices.
Next Gen Cfengine 3 releasedCfengine is an automated suite of programs for configuring and maintaining Unix and Linux computers. It has been used on computing arrays of up to 20,000 computers since 1993 by a wide range of organizations. Cfengine is supported by active research and was the first autonomic, hands-free management system for Unix-like operating systems.
Cfengine 3.0.0 is a new and substantial rewrite of cfengine's technology, building on core principles used over the past 15 years, and extending them with technology inspired by Promise Theory. (Promise theory describes policy-governed services in a framework of autonomous agents. It is a framework for analyzing models of modern networking and was developed at the University of Oslo.)
The new cfengine enhances its support of configuration management with:
Cfengine 3 also offers full integration with existing cfengine 2 systems and auto-encapsulation of cfengine 2 for incremental upgrades.
Mark Burgess, author of Cfengine, recently gave a presentation on Promise Theory and Cfengine 3 at Google on his way to LISA 08. It is now available at YouTube: http://www.youtube.com/watch?v=4CCXs4Om5pY
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/dokopnik.jpg)
Deividson was born in União da Vitória, PR, Brazil, on 14/04/1984. He became interested in computing when he was still a kid, and started to code when he was 12 years old. He is a graduate in Information Systems and is finishing his specialization in Networks and Web Development. He codes in several languages, including C/C++/C#, PHP, Visual Basic, Object Pascal and others.
Deividson works in Porto União's Town Hall as a Computer Technician, and specializes in Web and Desktop system development, and Database/Network Maintenance.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.

By Anonymous
My article "Keymap Blues in Ubuntu's Text Console" in LG#157 left a poster in LG#158 a bit annoyed.
He is saying that I didn't do this or didn't do that. And he is right, I did not.
Specifically, I don't feel capable of proposing "[...] a good consistent solution to all the woes of the Linux console." Please address that challenge to Linus Torvalds.
I am, however, willing to take up a smaller challenge posited by that poster: namely "[...] a sample keymap which is 'sized down' and [fits] the author's needs".
Fine - let's go for it. As noted before, we are discussing the text console, no X involved.
The text console keymap covers, inter alia, the self-insertion keys that we need to enter text. These keys vary a lot from country to country, so I'm going to leave them out. I'm not even going to try defining them for the US default keymap. The real concern, when considering text mode applications, are the 'functional keys'.
This is a term I'm using for lack of anything better. Alternative suggestions are welcome.
Functional keys are defined here by enumeration. The names for the keys come from the physical keyboard I'm typing this article on. They are quite common, actually:
F1 F2 F3 F4 F5 F6 F7 F8 F9 F10 F11 F12
Tab Backspace PrintScreen/Sys Rq Pause/Break
Insert Home PageUp Delete End PageDown
Up
Left Right
Down
You could argue that other keys should also be in the set 'functional keys'. For instance, Escape or Enter, or the modifier keys Shift, Ctrl, Alt. The reason they are not in the set is that they are not troublesome. I have checked the default keymaps offered by the kbd project for US, Germany, France, Italy, Spain, and Russia, and I would say these extra keys are safe. They are already consistent, and the differences are practically irrelevant.
Again, a note on terminology: keymap normally refers to a file where the key assignments are defined. The assignments can refer to plain keys, but they can also refer to modified keys, e.g. <ctrl><left>. In the keymap (the file!), a table of assignments for given modifiers is also called a keymap, so we get a keymap for <ctrl>, a keymap for <alt> and so on.
Additionally, you'll need to keep in mind the difference between key names and assigned keymap variables. Examples:
| variable 'Delete' | is distinct from the key Delete |
| variable 'BackSpace' | is distinct from the key Backspace |
| variable 'F14' | does not need a physical key F14 |
What you see, especially in Ubuntu (implying Debian, although I have not checked), is that the modifier keymaps rely on multiple strings. Examples:
| Keys | Assignments |
| <f4> | F4 |
| <shift><f4> | F14 |
| <ctrl><f4> | F24 |
| <shift><ctrl><f4> | F34 |
| <altgr><f4> | F44 |
| <shift><altgr><f4> | F54 |
| <altgr><ctrl><f4> | F64 |
| <shift><altgr<ctrl><f4> | F74 |
Variables F4 to F74 would deliver strings to the application expecting keyboard input and the application could then take action. The funny thing is that Ubuntu only has strings for F4 and F14, while F24 to F74 are empty, and no action can be taken on receiving the empty string.
This is, however, not the point here. The point is: is it a good idea to define all those keys via strings?
All those variables up to F256 are inherited from Unix. They were meant to make the keyboard flexible - i.e. customizable - on a case-by-case basis without assuming consensus. Unix and consensus don't mix. Everybody was welcome to do with those variables whatever they wanted, and there is old software that relies on such flexibility: define F74 in the keymap, and you are going to touch somebody.
There is a way to recognize, for example, <ctrl><f4> even if it has no unique string attached to it. It must have a string, of course - otherwise it would be ignored when the keyboard is in translation mode (either ASCII or UTF-8), which is the normal case. The approach relies on just reading the status of the modifiers - pressed down or not. All the modified keys get the same string as the plain key and then you find out about the modifier status. Example:
| Keys | Assignments |
| <f4> | F4 |
| <shift><f4> | F4 |
| <ctrl><f4> | F4 |
| <shift><ctrl><f4> | F4 |
| <altgr><f4> | F4 |
| <shift><altgr><f4> | F4 |
| <altgr><ctrl><f4> | F4 |
| <shift><altgr><ctrl><f4> | F4 |
You want to know if <ctrl><f4> was received? Check the input for the F4 string, then read the status of <ctrl>. If <ctrl> is pressed you got <ctrl><f4>; if not, you got <f4>.
Nice, isn't it? Not among the Unixsaurs. You see, reading the modifier status is a Linux specialty. Even the Linux manpage for ioctl_codes, where the trick is explained, gives a strong warning against their use and recommends POSIX functions. The catch is there are no such POSIX functions - so you either use the Linux IOCTLs or you're out of luck.
Ah, I hear, but that's not platform neutral. So what? Go through the source code of any text console editor and count the pre-processor directives that are there to accommodate peculiarities of Unix variants 1-999. There are also pre-processor directives to accommodate Linux, modifier status and all. If Midnight Commander can do it, why not others?
There are text console editors that use the modifiers for their Windows version but not for their Linux version. Why not? Because Windows delivers the key and the modifier at once, while Linux needs distinct commands, one to read the key, one to read the modifier. Therefore there is a slight time difference between the results - and theoretically, a risk of incurring an error. A lame excuse: when the two commands are next to each other in the source code, that error will never materialize. We are talking about micro-seconds.
My choice is to use plain keys everywhere in the set of functional keys whatever the modifiers may be, except the <ctrl><alt> combo which will be reserved for system operations like switching consoles.
How many keymaps do you need in the keymap? (If you're confused, please review the terminology warning above.) Ubuntu has 64 keymaps in the keymap, a mighty overkill. Fedora and OpenSUSE are a lot more reasonable. I'll stick close to their version:
| plain | 0 |
| <shift> | 1 |
| <altgr> | 2 |
| <ctrl> | 4 |
| <shift><ctrl> | 5 |
| <altgr><ctrl> | 6 |
| <alt> | 8 |
| <ctrl><alt> | 12 |
This choice gives the entry keymaps 0-2,4-6,8,12 in the keymap (the file) with a total of 8 keymaps (the assignment tables). As already mentioned, Ubuntu has keymaps 0-63.
Note that defining 8 keymaps does not preclude defining more. But those 8 keymaps should be defined as we dare to propose here.
Note also to the users of the US keyboard: <altgr> is nothing more than the Alt key on the right side, which must be kept distinct since it plays a role on non-US keyboards.
The characters 28-31, which are control codes, are desperately difficult to find on non-US keyboards. All the mnemonics implied by their name get lost. Besides, they also get shifted and are awkward to generate.
These are Control_backslash, Control_bracketright, Control_underscore, Control_asciicircum. A language and keyboard neutral solution could be as follows:
| Name | Code | Assignment |
| Control_backslash | char. 28 | <ctrl><8> on numeric keypad |
| Control_bracketright | char. 29 | <ctrl><9> on numeric keypad |
| Control_underscore | char. 30 | <ctrl><0> on numeric keypad |
| Control_asciicircum | char. 31 | <ctrl><1> on numeric keypad |
The immediate effects of the proposed partial keymap for functional keys concern system operations:
This would seem to conflict with DOSEMU - but it doesn't, because DOSEMU uses raw keyboard mode.
The non-immediate effects depend on text mode applications following Midnight Commander's example and using the Linux ioctls to read the modifiers status.
If it spreads then it would be normal to move to the start of a buffer with <ctrl><home> while <home> takes you to the start of the line. To move to the next word <ctrl><right> would be available. And you could highlight a selection pushing <shift> and moving the cursor. Last but not least, a large number of keybindings based on F1-F12 would become available and they would be language and country independent!
To anybody who only has experience with the US keyboard running the US default keymap, please try Nano on a Spanish or French keyboard. When you are done, please come back and agree with me that this little partial keymap should be called rI18N or the Real Internationalization Project.
So, after all those clarifications, here is the partial keymap for the functional keys.
Talkback: Discuss this article with The Answer Gang
 A. N. Onymous has been writing for LG since the early days - generally by
sneaking in at night and leaving a variety of articles on the Editor's
desk. A man (woman?) of mystery, claiming no credit and hiding in
darkness... probably something to do with large amounts of treasure in an
ancient Mayan temple and a beautiful dark-eyed woman with a snake tattoo
winding down from her left hip. Or maybe he just treasures his privacy. In
any case, we're grateful for his contributions.
A. N. Onymous has been writing for LG since the early days - generally by
sneaking in at night and leaving a variety of articles on the Editor's
desk. A man (woman?) of mystery, claiming no credit and hiding in
darkness... probably something to do with large amounts of treasure in an
ancient Mayan temple and a beautiful dark-eyed woman with a snake tattoo
winding down from her left hip. Or maybe he just treasures his privacy. In
any case, we're grateful for his contributions.
-- Editor, Linux Gazette
Finding reliable information about turning an Ubuntu Server installation into a Virtualization Server is not an easy task, and if you - like me - are going for a command-line only server, you will find this guide extremely useful.
VMWare Server 2 is a very good, free alternative to virtualization from VMWare - a company that has always been a leading provider in the virtualization arena. VMWare Server 2 requires a license number for installation, but this license can be freely obtained after registering at the VMWare page.
This product offers a solution that allows, among other things, the creation of headless servers. These are completely administrable via a browser, including creating virtual machines, powering up or down, and even command-line access.
Please note that while this article is aimed at a clean Ubuntu Server installation, most of the information contained within can be used on any modern distribution, whether command-line only or GUI.
To obtain the VMWare Server 2, you need to register at the VMWare Web page, http://www.vmware.com/products/server/, by clicking on the "Download" link.
After you submit your data, you will receive an e-mail with the serial numbers needed to activate your account - both on Windows and on a Linux host - and the download links. In this article, we will install using the VMWare Server 2 tar package, so go ahead and download it - get the one that fits your computer architecture (32 or 64 bit) - and save it on the computer where you want to install it. I will use "/home/deivid/" as the file location in the next few steps - change it to reflect the actual location where you saved the file.
First things first. To install VMWare Server 2, you need to install three packages: build-essential, linux-headers-server, and xinetd. If linux-headers-server does not point to the headers of the kernel you are using, install the correct ones. I had to install "linux-headers-2.6.27-7-server". You can check what kernel version you are currently running with "uname -r".
You can install these packages by using:
sudo apt-get install build-essential xinetd linux-headers-$(uname -r)
After you install the required packages, go to the folder where VMWare Server's tar package was saved, unpack it, and execute the install script as follows:
tar xvzf VMware-server-*.tar.gz cd vmware-server-distrib sudo ./vmware-install.pl
The install script will ask you some questions - where to install the files and docs, the current location of some files on your system, etc. On all of those questions, you can accept the default option by pressing "Enter". On the EULA screen, you can quit reading it by pressing "q", but you'll need to type "yes" then press "Enter" to accept it.
The next questions will be about the location of the current kernel header include files, so the installer can use them to compile some modules for you. The usual location is "/usr/src/linux-headers-<kernel version>/include" - for example, "/usr/src/linux-headers-2.6.27-7-server/include". After that, some files will be compiled, and the installer will ask several more questions - but again, the defaults all work fine.
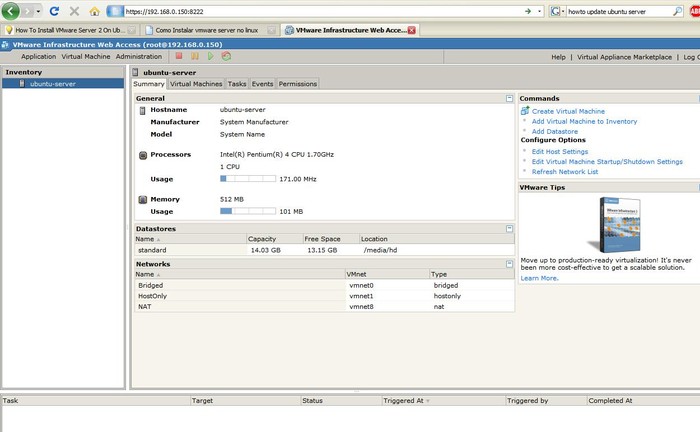
After that, the service will be installed and running and you can access the control interface via any Web browser, accessing <server ip>:8222 - for example, 192.168.0.150:8222. Please note that on Firefox, there will be a warning about this site's certificate, but it's safe to add an exception to it for this particular use.
To log in, by default you use the "root" account and password of the machine it's running on. With Ubuntu, you need to set a root password first - easily be done via the command "sudo passwd root". You can give permissions to other users in the "Permissions" link of the Web interface.
All the virtual machine administration can be done via this Web interface, including virtual machine creation, boot-up, access, and shut-down.
The process to create a virtual machine is pretty simple. Just click the "Create Virtual Machine" link in the web interface, and follow the on-screen instructions.
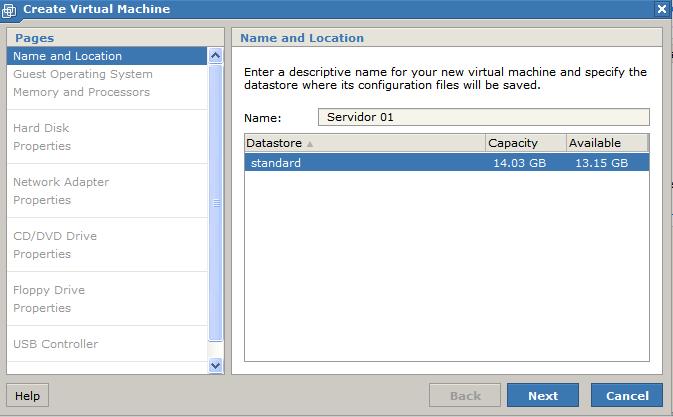
Here's a description of some of the data the system asks for during the installation:
In the next few steps, you configure the specifications of the virtual machine, including the amount of RAM and number of processors, capacity of the HD and the location where the data will be stored, details about the Network adapter, CD-ROM, floppy drives, USB controllers, etc. Configure accordingly with what you will need in the virtual machine.
In the Networking configuration dialog, you have three options for a network connection:
After you've completed all of the above configuration, the Virtual Machine will be created.
All the access to the virtual machine, as previously mentioned, is done via the Web interface. To power up the machine, you select it in the menu and press the "Play" button at the top of the window - other buttons are used to power-down and reboot it.
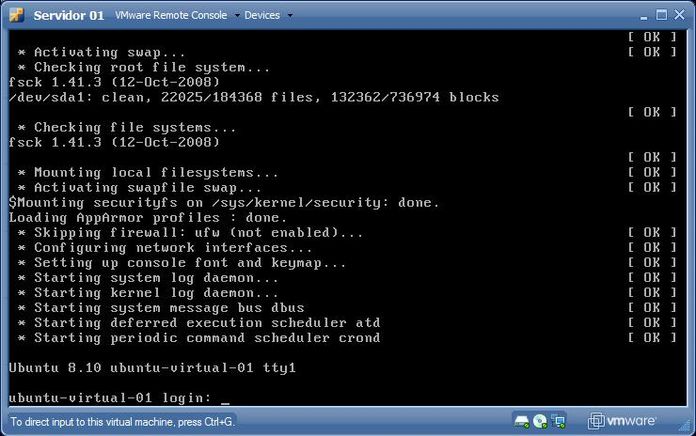
To gain access to the virtual machine console (e.g., to install an Operational System), after the machine is powered on, click on the "Console" link. Note that you will have to install a browser plug-in the first time you do so, but the installation is pretty straight-forward (click "Install Plug-in" and follow your browser's instructions - it's also needed to reboot the browser after the plug-in installation).
After that you can use that "Console" link to have access to the computer. Operating System installation on a virtual machine goes as if you were using a normal computer, so if needed, you can use any article about installing the operating system of your choice.
Virtualization is an important topic in computing, and is getting more and more popular lately. However, finding specific information - like how to make use of virtualization on a command-line only server, is a bit tricky. That is the gap this article has tried to fill - and I hope you (readers) can make a good use of it.
Here are links for some pages that might be useful:
Ubuntu Server Installation Guide: https://help.ubuntu.com/8.10/serverguide/C/installing-from-cd.html
VMWare Server 2: http://www.vmware.com/products/server/
"Any intelligent fool can make things bigger, more complex, and more violent. It takes a touch of genius - and a lot of courage - to move in the opposite direction."
-- Albert Einstein
Talkback: Discuss this article with The Answer Gang
Deividson was born in União da Vitória, PR, Brazil, on 14/04/1984. He became interested in computing when he was still a kid, and started to code when he was 12 years old. He is a graduate in Information Systems and is finishing his specialization in Networks and Web Development. He codes in several languages, including C/C++/C#, PHP, Visual Basic, Object Pascal and others.
Deividson works in Porto União's Town Hall as a Computer Technician, and specializes in Web and Desktop system development, and Database/Network Maintenance.
The past year saw a number of conference trends. Many formerly large conferences have layered related topics and sub-conferences in order to hold on to their audiences. LinuxWorld, for example, added mobility tracks and the "Next Generation Data Center" conference for the last two years and now has changed its name to OpenSource World for 2009. USENIX events also had many overlapping related conferences occurring alongside its major events.
But 2008 generally saw established conferences shrinking due to tighter budgets, increasing travel costs, and the deepening recession. Balancing this trend, there were many more tightly focused events springing out of the myriad of Open Source Communities. There were also many more on-line "virtual" conferences that could satisfy keynote attendees (although, in this reporter's opinion, the limited expo venues associated with these virtual events just can't replace the sights, sounds, and swag of a real expo.)
An example of such a virtual conference was the SOA and Virtualization events by TechTarget, IDG and ZDnet. Here's a recent one: http://datacenterdecisions.techtarget.com/seminars/AEV-virtualseminar.html
Along the same lines, certain conferences added or expanded video coverage, often for a lower fee than full conference attendance, allowing people to attend 'on-line'. Several USENIX events had live video feeds provided by Linux-Magazin.de, and these are available as an archive for review by attendees. This approach means no conference bag or networking opportunities, but definitely is easier on both the budget and the body.
Many newer conferences such as QCon and Best SD Practices for SW developers and project managers saw modest growth.
One of the largest events just keeps getting larger: Oracle OpenWorld (OOW). It had over 42,000 attendees with multliple overlapping sub-conferences such as Oracle Develop and the JDEdwards, Siebel, and BEA conferences. In fact it shifted into the September timeframe that BEA used for its annual user conference, abandoning Oracle's traditional early November timeframe.
New this year was a comprehensive video and session material archive. This was a joint venture between Oracle and Altus Learning Systems, which provides digital media production services to companies for internal and external use.
There were 1900 technical and general sessions and these are all archived. Additionally, all Open Oracle World (OOW) keynotes are fully archived, with searchable text transcripts and all slides timed and reposted. This allows a user to search for a phrase in the transcript, then view the accompanying slide and hear the associated audio. This could be a good way to jog one's memory months after attending the conference, as well as exploring sessions not attended by quickly scanning for desired content. Altus is hoping this makes access and repurposing of content easier for users of their service.
I was given an opportunity to discuss the multimedia archive with some of the principals before Oracle OpenWorld. One of the key points of the discussion was that only a limited sampling of sessions would be available as a teaser to the public; most of these would be the keynote sessions that are usually available on-line after a conference. I had specifically asked about having one or two of these sample sessions being about Linux or Oracle Open Source collaborations and was assured at least one such session would be available for preview. But, as fate is fickle, my contact spoke to me shortly after Oracle OpenWorld (OOW) and said the chosen Linux session would only be available for a short time, not past LG's next publication date in October.
Here is the Aldus OOW preview page, which also hosts most of the OOW keynotes: http://ondemandpreview.vportal.net/
Now the flip side of this: Apparently, if you did not attend the 2008 event, you can get all media at the Oracle OpenWorld OnDemand portal but have to pay US$700. OOW-08 attendees can use the OOW 'course catalog' to get only the slides for most presentations - or pay $400 to access the portal. This is very different from previous years where slides were made available to the public on the Oracle Technical Network (OTN).
However, in a publicly viewable thread, the following information is available:
2008 OpenWorld Presentations: http://www28.cplan.com/cc208/login.jsp
(Login/password: cboracle/oraclec6)
Use this for login and for accessing each presentation.
Using that info, you can download a presentation on the Coherence
Application Server Grid:
http://www28.cplan.com/cbo_export/208/PS_S299531_299531_208-1_v1.pdf
To get a multi-media view of this material, this video covers Oracle
Coherence Data Grid - formerly the Tangorsol product line:
http://www.youtube.com/watch?v=4Sq45B8wAXc&feature=channel_page
To access the Linux-oriented presenatations from the OOW catalog, go to the portal link, login, and then select "Linux and Virtualization" from only the focus area pull-down, set the other pull-downs to "All".
Here is a link to the rather extensive OOW "Unconference" listed on the OOW wiki: http://wiki.oracle.com/page/Oracle+OpenWorld+Unconference?t=anon
The big event at OOW was the announcement of the Oracle-HP eXaData database machine. Jet black in its rack and wearing the new "X" logo, it was pretty and powerful with an impressive set of specs. But it also sported a huge price tag, over a million dollars for starters, which effectively meant it competed with the high end SMP boxes like Convex and Teradata. It is very fast on very, very big databases, just the kind of thing that services like NASDAQ need and can afford.
The magic came from blending disks with Intel Xeon multi-core processors and an Oracle secret sauce that ran a lite version of Oracle to produce parallel query processing. That also meant the new hardware needed to talk to an Oracle-like DB as the controller, and there were a lot of Oracle licenses included for the disk-and-CPU array. I believe some of the newer storage arrays, coupled with FOSS databases, can produce decent performance at similar or lower costs per transaction. (Check out Sun's ZFS-based storage devices, running with Postgres or MySQL.)
Another major announcement was the new Oracle Beehive collaboration suite. The goal is to help organizations secure communications and add collaboration into business processes. Oracle Beehive is an open-standards based enterprise collaboration platform, with integrated workspaces, calendar, instant messaging, and e-mail.
This is a link to the PDF for the session introducing Beehive:
http://gpjco.edgeboss.net/download/gpjco/oracle/course_html/2008_09_22/S298423.pdf
One great change is that the bigger Oracle Develop sub-conference was at the Marriot Hotel, just two blocks from the Moscone Convention Center. That allowed attendees to pick either regular conference sessions or the more technical developer curriculum with only a five minute transit time. In 2007, Oracle Develop was at the Hilton with a fifteen to twenty minute wait and bus ride (and at least a twelve minute walk) away. That had me swearing under my breath.
This year the exec conference and the partner events were at the more distant Hilton. The food may have been a little better at the Hilton, but the session rooms are easier to find at the Marriott, and it's only a one long block from SF mass transit. Congrats to the conference organizers for getting these details right in 2008 and hopefully future OOW conferences as well.
One very small but very focused event is the new eComm (emerging Communications) conference that was first held last year in Silicon Valley, California. eComm actually started as a community effort to replace O'Reilly's ETel Conference when that 2008 event was cancelled.
eComm organizers view the venue as "a forum to understand the radical restructuring in how humanity connects, communicates and collaborates". The first conference, in 2008, broke a lot of new ground and attracted 300 people and 80 speakers from 15 countries. The tagline for the event was "The Trillion Dollar Industry rethink" and it did make significant inroads on that goal. The '09 event in March hopes to build on that and create a forum on a post-telecom era built on open standards and open APIs.
Major topics of eComm '09 include the expected cloud computing and social computing tracks, but will also include tracks on "Open Handsets & the Open Ecosystem", "The Fight for Open Spectrum", "New Forms of Contactability" and more.
Use of the Computer History Museum as a conference venue in 2008 was a good choice, due to its closeness to Highway 101 and its facilities. But it was the wealth of exciting and innovative speakers that made this a great conference with a lot of buzz in the hallways and at the breaks.
Here is the archive of eComm 08 videos:
http://ecomm.blip.tv/posts?view=archive
And here is a link to some 60 slide presentations:
http://www.slideshare.net/eComm2008/slideshows
The eComm 2008 site is here:
http://ecommconf.com/2008/
The eComm 2009 site is here:
http://ecommconf.com/2009/
eComm 2009 is coming up next month, March 3-6, at the San Francisco Airport Marriott.
Founder and main organizer Lee Dryburgh told LG that "the 2008 event was the first conference to cover both iPhone and Android. These signify that the trillion dollar telecommunications industry has already started down the path that homebrew computing took three decades ago. ...eComm tracks, highlights, and promotes both the people and the technologies driving the democratization of communications."
Lee hopes that eComm and other community-driven events will break the telephony model of telecommunications and drive new forms of innovation. "Telecoms [used to be] linked to telephony. But telephony is being displaced by other modes of communication, and what telephony was will be reinvented. You're going to see a lot of companies at eComm 2009 who are building exciting applications with voice. We are just coming out of the "Henry Ford" stage of telephony, where you can have any colour as long as it's black."
I'd like to highlight Brian Capouch's practical presentation on building a
people's wireless and telephony network in rural areas with old Wi-Fi
routers and 12 volt batteries. Unfortunately, a lot of what he said is not
captured in the slides available here:
http://www.slideshare.net/eComm2008/brian-capouchs-presentation-at-ecomm-2008
You also need to see a video of the presentation here:
http://ecomm.blip.tv/file/891466/
Dryburgh has an interesting interview with Sasha Meinrath on Telcom 2.0 posted at http://ecommconf.com/blog/2009/01/spectrum-20-future-telecom-networks.htm
He also talks with Andreas Constantinou on Mobile OS's and NaaS (Network as a Service) here : http://ecommconf.com/blog/2009/01/mobile-operating-systems.html
Talkback: Discuss this article with The Answer Gang
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.
By Ben Okopnik
Thanks to Karl Vogel's recent article about Hyperestraier, I've been playing around with indexing some of my data - and having lots of fun in the process. I discovered that Hyperestraier is exceptionally good at what it does; it's a fantastic app, and I wish I'd known about it years ago. It lets me build fast, searchable databases of almost any textual content, including anything that can be converted to text, and to have a Web interface to those databases. This article documents the results of my experience in exploring Hyperestraier, and presents a few "aids to navigation" to make indexing and searching pleasant and fun - or at least as pain-free as possible.
Please note that throughout this article, I use several assumptions in order to standardize things:
Overall, this scheme suits my preferences very well. It allows me to draw obvious conclusions instead of having to remember how and where I indexed things and what I called the database for a given directory. You don't have to do it that way, but I find it very convenient - since I have better things to store in my memory than arbitrary trivia.
The simplest scenario for using Hyperestraier is one in which you have a number of ".txt", ".htm", or ".html" files (one of Hyperestraier's minor flaws is that it has a Windows-like tendency to assume that files are defined by their extensions; fortunately, as we'll see later on, this is remediable.) These may even be mixed in with a bunch of other content - e.g., images, PDFs, music files, and so on; Hyperestraier will just ignore all of those by default, so indexing the textual content takes nothing more than
cd /home/joe/XYZ estcmd gather -sd searchXYZ .
This will index the content of '/home/joe/XYZ', creating a database (a subdirectory containing the index data) called 'searchXYZ' in the directory where you've issued the command. The "-sd" option is one that I like to use, although it's not required: it records the modification date of each file as part of the searchable data. This provides an additional search option and allows a bit more flexibility and precision in your searches.
So, let's try it out and see how it looks. First, I'm going to fake up a directory with "perfect content":
# Copy all ".txt" and ".html" files from my ~/www directory to /tmp/X
find ~/www -type f -size +0 -iregex '.*\(html\|txt\)' -exec cp {} /tmp/X \;
# How many files was that, anyway?
ls /tmp/X|wc -l
2924
# How big is all that stuff?
du -sh /tmp/X|cut -f1
342M
Next, I'll index it:
cd /tmp/X estcmd gather -sd searchX .
The output looks like this:
estcmd: INFO: reading list from the directory: . estcmd: INFO: status: name=searchX dnum=0 wnum=0 fsiz=6899176 crnum=0 csiz=0 dknum=0 estcmd: INFO: 1 (/tmp/X/00ReadMe.txt): registered estcmd: INFO: 2 (/tmp/X/00_READMEFIRST.txt): registered estcmd: INFO: 3 (/tmp/X/A Time Comes In Your Life.txt): registered [ ...skipping a few thousand lines ] estcmd: INFO: 2922 (/tmp/X/yaw.html): registered estcmd: INFO: 2923 (/tmp/X/youtube.html): registered estcmd: INFO: 2924 (/tmp/X/zQdebit-orderform.html): registered estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=1 fsiz=41568116 crnum=157951 csiz=56815761 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=10001 fsiz=41935584 crnum=147951 csiz=55749775 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=20001 fsiz=45899931 crnum=137951 csiz=50521003 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=30001 fsiz=49897291 crnum=127951 csiz=45494307 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=40001 fsiz=52269735 crnum=117951 csiz=42341097 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=50001 fsiz=54037209 crnum=107951 csiz=39543361 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=60001 fsiz=55833455 crnum=97951 csiz=36869171 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=70001 fsiz=58203816 crnum=87951 csiz=33508862 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=80001 fsiz=61974918 crnum=77951 csiz=28867366 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=90001 fsiz=64163782 crnum=67951 csiz=25698000 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=100001 fsiz=66314530 crnum=57951 csiz=22858433 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=110001 fsiz=69521776 crnum=47951 csiz=18789339 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=120001 fsiz=71238559 crnum=37951 csiz=16151196 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=130001 fsiz=73565534 crnum=27951 csiz=12885585 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=140001 fsiz=75759457 crnum=17951 csiz=9718694 dknum=0 estcmd: INFO: flushing index words: name=searchX dnum=2924 wnum=150001 fsiz=80626768 crnum=7951 csiz=3832485 dknum=0 estcmd: INFO: closing: name=searchX dnum=2924 wnum=157952 fsiz=83841343 crnum=0 csiz=0 dknum=0 estcmd: INFO: finished successfully: elapsed time: 0h 2m 14s
2 minutes and 14 seconds to index some 340MB of data in over 2900 files; that's not too bad! Note that dumping the output into /dev/null would have sped this up significantly; a large percentage of the above time is spent printing the data to the screen. Any errors, however, would still be shown on the console, since "estcmd" very properly directs them to STDERR rather than STDOUT.
Finally, we need to build the keyword database and optimize the index. On subsequent runs (updates), we'll need to purge the indexes of any deleted documents, too - so we might as well get in the habit of doing that now.
estcmd extkeys searchX estcmd optimize searchX estcmd purge -cl searchX
...and a few seconds later, we have a searchable index of the above content. It doesn't get a whole lot more complicated than that, either, unless you want to do something like indexing only a certain subset of the files in a directory, or indexing file types other than the above-mentioned text and HTML. That would require selecting those files ("estcmd gather" would normally ignore them in reading a directory), feeding that list to the indexer, and delegating their processing via the "-fx" option (i.e., using some external program to filter them to text, HTML, or MIME, and notifying the indexer of the output type.) For more info, see "-fx" under the "gather" heading in the "estcmd" man page.
Now that we have it built, you could search this database by using "estcmd search -vh searchX <search_term>" - but this is a bit clumsy and manual, and should really be scripted into something more useful. Toward the end of this article, I'll show you a way to easily search the index and instantly access the data once you've found its location in the index. For now, we'll keep focusing on the "data collection" phase of this process.
Given the dynamics of searching and examining data, the best scenario is one where you have lots of small files rather than a few large, monolithic ones. Hyperestraier can work with either one, but finding the thing you're looking for within a large file (after you've found which file has it with Hyperestraier) becomes a separate task - one that requires its own tools and methods. Besides, large files gobble lots of system resources while they're being indexed.
On my system (Ubuntu 8.04, 384MB RAM/150MB swap), any individual file over 3MB requires a perceptible interval to index, 5MB generates a significant delay, and a 10MB file may take several minutes to process. I've never been patient enough to sit through indexing a 15MB file (although I suspect that letting it run overnight would do the job.) In other words, the delays created by increasing file size go up asymptotically, so it behooves you to carefully consider the maximum file size that you'll try to process - and then to restrict your selection to files below that limit. Fortunately, the '-lf' option of "estcmd gather" makes that easy.
Overall, though, it's really not much of an issue: I've been writing (and saving) email for well over 20 years, and my mail directory contains only 5 files over the 10MB mark, with 3 of them being that large because they consist of almost nothing beyond data or image attachments (i.e., there'd be no point to searching those for text.) For the remaining two, I'm willing to use standard tools like "less"; in fact, I defined a "searchmail" function years ago that uses "less" to open and search my ~/Mail/Sent_mail file. Not quite as fast as Hyperestraier, but it does what it should and does it well.
If you should decide that you absolutely, positively have to have an index for every single bit of mail on your system, then I recommend converting to another religion (Maildir or Mh instead of mbox.) This will break everything up into individual message files, making it into a perfect snack for the ever-hungry Hyperestraier.
Having considered all these angles, I now felt reasonably confident in proceeding with the following strategy for indexing my mail directory:
cd ~/Mail estcmd gather -cm -sd -fm -lf 4 -bc searchMail . estcmd extkeys searchMail estcmd optimize searchMail estcmd purge -cl searchMail
Here's what all of that means:
| -cm | index only the files where the mtime has changed |
| -sd | record the mtime of each file as an "attribute" (searchable data) |
| -fm | treat all files as MIME (note that without this option, most of your email files would be ignored - e.g., files ending in ".com" would be rejected as DOS executables!) |
| -lf 4 | don't index files over 4MB in size |
| -bc | ignore binary files (there shouldn't be any, but might as well check) |
| . | read the files from the current directory |
I ran "estcmd gather" with all of the above, then ran the standard kit of commands to create a keyword database, optimize and clean up the index, and clean out the data for deleted docs, where "-cl" means "clean up regions of deleted documents" (this last is, again, most useful on subsequent runs after the indexed data has changed and needs to be reindexed.)
It's worth noting that "estcmd" appears to take a few moments to "wrap up" what it's doing even though you've been returned to the shell prompt, so running these commands one immediately after the other (i.e., either from a script or by executing them on one command line separated by semicolons) can result in errors. If you're going to do that, I suggest sticking a "sleep 1" command between them - particularly right before "estcmd optimize".
One of the things that needs to be considered is what will happen when you re-run the indexer (presumably, your mail files will change constantly, so you'll need to reindex on a regular basis to stay current.) Because we had to use the "-fm" option, in effect telling "estcmd gather" to treat all files as MIME, every subsequent run will try to index the database files themselves along with the actual content. This would be a large and pointless waste of time and disk space, so we'll need to modify the file list that we feed to the indexer. In fact, we could do this right from the beginning - there would be no harm in it - and this would give us a generalized approach to doing things properly.
The traditional Unix tool for doing this kind of file selection is "find" - and that's exactly what we're going to use here:
# Create a temporary file and save its name in "$tmp"
tmp=$(mktemp "/tmp/searchXXXXXX")
# Construct the index name
index="search${PWD##*/}"
# Find all plain files that are non-empty; ignore the index subdirectory
find . -wholename "./$index" -prune -o -type f -size +0 -fprint "$tmp"
# Build the index using the collected filenames; skip files over 4MB
estcmd gather -sd -fm -lf 4 "$index" "$tmp"
estcmd extkeys "$index"
estcmd optimize "$index"
estcmd purge -cl "$index"
# Remove the temp file
rm "$tmp"
The reward for all of the above is a very fast searchable database. How fast, you ask? Well, according to Hyperestraier, my mail index contains 2563 documents and 2937263 words - that's from about 850MB worth of files. How about 0.001 seconds to search all that text for a word with no matches, 0.074 seconds for a single match, and 0.739 for a very common word ("the")? I don't know about you, but I'd consider that pretty darn fast. Watching it happen in a text-based web browser is enough to give you whiplash - there's no perceptible time between hitting 'Search' and seeing the results. That beats 'grep' and even 'fgrep' all hollow.
If you want to index something other than your mail directory, most of the process remains the same. In fact, the only things that will change are:
For my next indexing project, I still kept it simple but expanded the scope. I have a huge list of recipes that I've built up over the years; I started with a MealMaster database (about 70,000 recipes) and have added to it constantly since then. In the past, I'd tried loading it all into a MySQL database; I'd also tried simply creating a directory structure based on categories and cross-referencing all of them by type using symlinks. Both of these were moderately successful, with speeds of around 10-15 seconds per search. Now, I decided to run it all through Hyperestraier:
cd ~/Docs/MealMaster estcmd gather -cm -sd -ft searchMealMaster . estcmd extkeys searchMealMaster estcmd optimize searchMealMaster estcmd purge -cl searchMealMaster
In this case, I didn't need to do a whole lot with the "gather" command line: since I knew all the files were plain text, I just needed to tell it to treat them that way. Since the recipe files are actually named after the recipe they contain (i.e., their names don't match something.txt), none of them would be indexed without the "-ft" option!
Once I had typed all of the above, the indexing process took less than four and a half minutes for these tens of thousands of files. Clearly, this kind of thing is right in the center of Hyperestraier's area of competence!
Last of all, and just for the fun of it, I decided to index the rest of my
~/Docs directory. This was the biggest challenge of all: this huge directory
contains text, HTML, MIME stuff, binary data, images, music files... in
fact, 113 different types of files as reported by the "file" command! As the
Russian saying about complex and confusing situations goes, "the Devil
himself would break a leg in it". This one would take a bit more
preparation and forethought - especially in the filtering stage, since it
already contained a previously-indexed directory that I wanted to ignore -
so instead of doing it all on the command line, I decided to create a
script. Since I liked several of the ideas in Karl's article, I
stole borrowed and expanded on them. While I was at it, I
decided to generalize the script so it would apply to more than just this
one situation.
#!/bin/bash
# Created by Ben Okopnik on Sat Jan 3 00:50:54 EST 2009
# Some ideas from Karl Vogel's Hyperestraier article
# (http://linuxgazette.net/158/vogel.html)
# Maximum file size in MB; adjust this to your preferences
MAX_FILE_SIZE=3
dir="$(pwd)"
db="$dir/search${dir##*/}"
# Default options for "gather":
# -cl: Regions of overwritten documents will be cleaned up
# -ft: Files will be treated as plain text
# -bc: Binary files will be detected and ignored
# -sd: Modification date of each file will be recorded as an attribute
# -cm: Documents whose modification date has not changed will be ignored
# -lf N: Ignore any documents larger than N megabytes
gather_opts="-cl -ft -bc -sd -cm -lf $MAX_FILE_SIZE"
# Define file extensions to ignore; this saves us time, since we don't need
# to run "file" over them. This list does not include "questionable"
# filetypes (i.e., DOC, PDF, etc.) that you may want to delegate and index later.
ignore="$db|\.(gif|jpg|png|xcf|gz|tgz|tbz|p[pb]m|tiff?|mp[23g]|mpeg|wav|midi?|sid|au|r[am]|[au]law|xbm|pag|dir|swp|idx|psd|xls|sxw|zip|pgm|wm[av]|eps|swf|aux|bbl|idx|tex|raw|od[st])$"
/bin/echo "========= Searching for indexable content ============="
# If there's no EXCLUDE file, create one that just excludes itself
# (needed by the 'egrep -ivf EXCLUDE' filter.)
[ ! -f "$dir/EXCLUDE" ] && echo '/EXCLUDE$' > "$dir/EXCLUDE"
# Ignore the Hyperestraier index and any empty or "non-regular" files
/usr/bin/find . -wholename "$db" -prune -o -type f -size +0|\
# Generate 'file' output for each file, ignoring weirdness in filenames
/usr/bin/xargs -d '\n' -I '{}' -s 1000 file -F '///' '{}'|\
# Ignore these (false positives for "text" filetype)
/bin/egrep -iv '///.*(latex|rich)'|\
# Ignore everything _except_ these filetypes (positive matches); return fileNAMES
/bin/sed -n 's#^\(.*\)///.*\(text\|xml\|pod_doc\).*$#\1#;T;p'|\
# Exclude any filenames that match patterns in the 'EXCLUDE' file
/bin/egrep -ivf './EXCLUDE'|\
# Exclude filenames that match the 'ignore' pattern
/bin/egrep -iv "$ignore"|\
# Index the remaining results
/usr/bin/estcmd gather $gather_opts "$db" -
# Remove the 'spurious' EXCLUDE file
[ "`/bin/cat $dir/EXCLUDE`" = '/EXCLUDE$' ] && rm "$dir/EXCLUDE"
/bin/echo "================== Optimizing... ======================"
/usr/bin/estcmd extkeys "$db"
/bin/sleep 1
/usr/bin/estcmd optimize "$db"
/usr/bin/estcmd purge -cl "$db"
/bin/echo "==================== Finished. ========================"
Some of the features that this script introduces are quite useful: creating a file called 'EXCLUDE' in the target directory and populating it with patterns (one per line) to match any files or directories that you want to exclude will do the obvious and sensible thing. The script will also pre-filter the files to eliminate the obviously non-textual types by extension - not a perfect strategy, but one that would be used by Hyperestraier anyway - and eliminates wasting cycles in checking the filetypes for known non-textual files. Then, it actually does a filetype check on the remainder rather than relying on extensions, and filters out any non-textual types that remain (getting this right took a lot of research - all of which resulted in that long pipeline at the heart of the above script.) The script also determines the target directory name and the database name based on where it's called from - so all you have to do is "cd" into the directory you want and type "build_search".
There's also a speed-versus-completeness tradeoff you might want to think
about: the "MAX_FILE_SIZE" is set to 3 by default, which means that all
files above 3MB in size will be rejected by the indexer. You can set it
higher if you're willing to spend a bit more time: at a setting of 3, my
mail directory took only 8 minutes to index (167MB in 1430 files), while a
setting of 4 (194MB in 1436 files) took just a bit over 20 minutes.
Considering that it's relatively easy to select and index the large files
later, when you're about to walk away from the computer for a while (e.g.,
'find -size +4M -a -size -15M|estcmd gather [options] dbname -'),
there's no real need to waste large amounts of time in the original
indexing. As a result, I tend to leave it set to 3.
In general, you should be able to execute the above script in any directory that you want to index and have it Just Work. Please feel free to send me your comments and updates if anything fails or if you've come up with any improvements; it would be nice to have a general-use indexer, and feeding it lots of variations is a good way to make it bullet-proof.
You can certainly use the "search" option of "estcmd" to find what you're looking for - but it's a bit clunky, since you'd still have to go to each reported file and open it manually. Fortunately, Hyperestraier comes with a very nice CGI interface that can be configured to show the results - and with just a little more organization and scripting, connecting this with any indexes you've created can become a nearly-automatic process resulting in a neat, intuitive method of retrieving your data.
In Ubuntu, at least, the files that we need are in /usr/lib/estraier and /usr/share/hyperestraier; to start the process - assuming that you have a web server running on your system, and that it is configured appropriately - we'll just create a 'search' subdirectory under your Web root (e.g., /var/www/search), set up the appropriate structure for searching your indexes, and modify the config file as needed. Here's the script that I use to do all of the above:
#!/bin/bash
# Created by Ben Okopnik on Thu Jan 15 23:41:56 CST 2009
WEBROOT="/var/www"
dir="$(pwd)"
db="$dir/search${dir##*/}"
# Exit if there's no index database in the current directory
[ -d "$db" ] || { printf "$db not found - exiting...\n"; exit 1; }
sdir="$WEBROOT/search/${dir##*/}"
# Exit if the search directory with the proposed name already exists
[ -d "$sdir" ] && { printf "$sdir already exists - exiting...\n"; exit 1; }
# Create the ".source" dir if it doesn't already exist and copy the key
# files into it
[ -d $WEBROOT/search/.source ] || {
mkdir -p "$WEBROOT/search/.source"
cp /usr/share/hyperestraier/estseek* $WEBROOT/search/.source
cp /usr/lib/estraier/estseek.cgi $WEBROOT/search/.source
}
mkdir -p "$sdir"
cd "$sdir"
DB="$db" /usr/bin/perl -wpe's/^(indexname:).*$/$1 $ENV{DB}/' ../.source/estseek.conf > estseek.conf
ln -s ../.source/estseek.{cgi,help,tmpl,top} .
This script, when run from a directory in which you've built an index, will create a subdirectory under $WEBROOT/search with the same name as the current directory (i.e., if you're in "/home/joe/Mail", and your Web root is "/var/www", it will create "/var/www/search/Mail".) It will also populate it with links to the appropriate files for running a Hyperestraier search, and it will create a configuration file that will point to your searchable index. Since the configuration is just plain text, you should check it out and think about what else you might want to change (i.e., the page name, the default message/logo, etc.) - but from here forward, we're in the final stretch. All the rest, as they say, is just minor details.
The only part that remains is tying all of this together with a little more CGI: we need a self-updating top-level index page that will show us all the available subdirectories under $WEBROOT/search and link to them. Here it is:
#!/usr/bin/perl -wT
# Created by Ben Okopnik on Thu Jan 15 22:11:38 CST 2009
use strict;
use CGI qw/:standard/;
$|++;
my @dirs;
while (<*>){ push @dirs, $_ if -d; }
binmode STDOUT, ':encoding(UTF-8)'; # Set up utf-8 output
print header( -charset => 'utf-8' ),
start_html( -encoding => 'utf-8', -title => 'Available searches' ),
h3('Available search indexes'),
map( { a( { -href=>"$_/estseek.cgi" }, $_ ), br, "\n"} @dirs ),
end_html;
Name this file 'index.cgi', place it in your $WEBROOT/search, and point your browser at 'http://localhost/search'. You should see a list of links, one for each index you've built - assuming that you ran the above "build_www" script for each of them. Click on a link, and you'll see the Hyperestraier search interface:
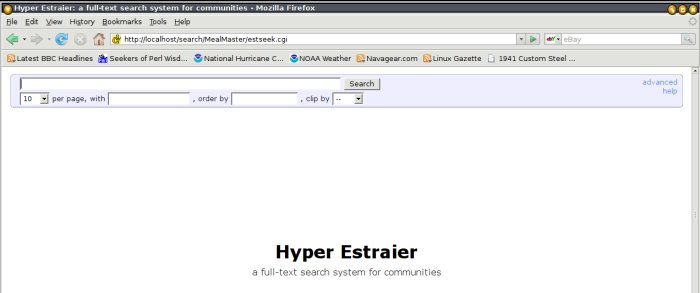
Be sure to read the help page linked from the above page; it has really good tips for making your searching more precise and effective. It also helps to know that the path to each indexed file is that file's URI - and can thus be specified as part of the search. This means that you can search by filename as well as contents.
Hold on to that thought for a moment; I've got a minor disappointment in store for you. Don't worry: it's all fixable... it'll just take a little more juggling of electrons. For now, you can just use your text browser - Lynx, Links, w3m (my favorite), or any non-Mozilla browser (e.g., Dillo) - and they all work fine. Wonderfully fast, too.
Now, as to Mozilla... well, it gets just a bit stupid about working with local files via CGI. If you really, really want to use it for this, here's what I've learned and used in order to make it behave. This, of course, has nothing to do with Hyperestraier - but it does make a useful club for beating that dinosaur-like browsing creature into a pleasant shape.
Problem: Mozilla refuses to open local 'file://' links from CGI output. This sucks, big time.
Solution: According to Mozilla, this is a security
measure. According to me, it's a pointless annoyance. Therefore, close
all your Mozilla windows, open your
~/.mozilla/firefox/<profile_name>/prefs.js in your favorite editor,
and add the following lines:
user_pref("capability.policy.localfilelinks.checkloaduri.enabled", "allAccess");
user_pref("capability.policy.localfilelinks.sites", "http://localhost http://127.0.0.1");
user_pref("capability.policy.policynames", "localfilelinks");
Problem: Indexing your email directory means that you'll
have links to files like '[email protected]' - which Mozilla will try to open as
DOS executable files (i.e., by using Wine.) Other browsers aren't that
smart yet - for which we should all be eternally grateful.
Solution: Relax, relief is close at hand. Instead of
trying to find Mozilla's little brain in order to shred it with a chainsaw
while laughing madly and then torching the remains with a flamethrower,
simply open (or create) a ".mime.types" file in your home directory and
insert the following line:
text/plain com
This will make Mozilla "think of" all files ending in ".com" as plain text files - and thus, actually display them instead of popping up dialogs like this:
| Should I save this or open it with some random application? Maybe I should just execute it and try to infect your machine... oh, darn, this is Linux. Can I just explode your monitor, then? Are you sure? Just a little bit? | ||||
| Destroy | Smash | |||
...but I may have misread that message. Or maybe my coffee contains a strong hallucinogen. You just never know.
As you can probably guess, I'm pretty excited about all the uses to which I can put Hyperestraier - both for my personal use and professionally. Again, it's an excellent application, and I'm very grateful to Karl Vogel for introducing me to it. I hope that you will find it at least as useful as I have, and that the scripts I wrote for this article (available here) make life a little easier for you. Enjoy!
Talkback: Discuss this article with The Answer Gang

Ben is the Editor-in-Chief for Linux Gazette and a member of The Answer Gang.
Ben was born in Moscow, Russia in 1962. He became interested in electricity at the tender age of six, promptly demonstrated it by sticking a fork into a socket and starting a fire, and has been falling down technological mineshafts ever since. He has been working with computers since the Elder Days, when they had to be built by soldering parts onto printed circuit boards and programs had to fit into 4k of memory (the recurring nightmares have almost faded, actually.)
His subsequent experiences include creating software in more than two dozen languages, network and database maintenance during the approach of a hurricane, writing articles for publications ranging from sailing magazines to technological journals, and teaching on a variety of topics ranging from Soviet weaponry and IBM hardware repair to Solaris and Linux administration, engineering, and programming. He also has the distinction of setting up the first Linux-based public access network in St. Georges, Bermuda as well as one of the first large-scale Linux-based mail servers in St. Thomas, USVI.
After a seven-year Atlantic/Caribbean cruise under sail and passages up and down the East coast of the US, he is currently anchored in northern Florida. His consulting business presents him with a variety of challenges such as teaching professional advancement courses for Sun Microsystems and providing Open Source solutions for local companies.
His current set of hobbies includes flying, yoga, martial arts,
motorcycles, writing, Roman history, and mangling playing
with his Ubuntu-based home network, in which he is ably assisted by his wife and son;
his Palm Pilot is crammed full of alarms, many of which contain exclamation
points.
He has been working with Linux since 1997, and credits it with his complete loss of interest in waging nuclear warfare on parts of the Pacific Northwest.
By Joey Prestia

There are several different rescue CDs out there, and they all provide slightly different rescue environments. The requirement here at Red Hat Academy is, perhaps unsurprisingly, an intimate knowledge of how to use the Red Hat Enterprise Linux (RHEL) 5 boot CD.
All these procedures should work exactly the same way with Fedora and CentOS. As with any rescue environment, it provides a set of useful tools; it also allows you to configure your network interfaces. This can be helpful if you have an NFS install tree to mount, or if you have an RPM that was corrupted and needs to be replaced. There are LVM tools for manipulating Logical Volumes, "fdisk" for partitioning devices, and a number of other tools making up a small but capable toolkit.
The Red Hat rescue environment provided by the first CD or DVD can really come in handy in many situations. With it you can solve boot problems, bypass forgotten GRUB bootloader passwords, replace corrupted RPMs, and more. I will go over some of the most important and common issues. I also suggest reviewing a password recovery article written by Suramya Tomar (http://linuxgazette.net/107/tomar.html) that deals with recovering lost root passwords in a variety of ways for different distributions. I will not be covering that here since his article is a very good resource for those problems.
Start by getting familiar with using GRUB and booting into single user mode. After you learn to overcome and repair a variety of boot problems, what initially appears to be a non-bootable system may be fully recoverable. The best way to get practice recovering non-bootable systems is by using a non-production machine or a virtual machine and trying out various scenarios. I used Michael Jang's book, "Red Hat Certified Engineer Linux Study Guide", to review non-booting scenarios and rehearse how to recover from various situations. I would highly recommend getting comfortable with recovering non-booting systems because dealing with them in real life without any practice beforehand can be very stressful. Many of these problems are really easy to fix but only if you have had previous experience and know the steps to take.
When you are troubleshooting a non-booting system, there are certain things
that you should be on the alert for. For example, an error in
/boot/grub/grub.conf, /etc/fstab, or
/etc/inittab can cause the system to not boot properly; so can
an overwritten boot sector. In going through the process of troubleshooting
with the RHEL rescue environment, I'll point out some things that may be of
help in these situations.
First, if you can't get the system booted by normal means, check things like the order of boot devices in the BIOS just to make sure you're reading the right drive. You should also ensure that the drive is being recognized. Try to pinpoint where in the boot sequence the process is failing; take note of any unusual activity or messages. Remember that the boot process runs in this order:
/etc/grub/grub.conf/etc/inittab/etc/rc.d/rc.sysinit/etc/fstabPay close attention to any configuration files, as they are likely places for errors.
OK - it's time for the boot CD. The Linux rescue environment will load a minimal system with only a small subset of commands, but it should be enough for our purposes.
After restarting the machine with the CD or DVD in the drive, you will need
to type linux rescue at the boot prompt instead of hitting
'Enter' for a normal install.

The next screen will ask us to choose a language.
The screen after that will ask for our keyboard layout.
At this point, we are asked if we would like to configure our network interfaces. If you need access to an NFS install tree or some other external resource, you should select this option. It will allow you to configure your network interfaces with IPv4 and/or IPv6; you can also choose manual or dynamic configuration of your IP address and subnet mask. If you think that you might need to reinstall a corrupt package and have no network install tree, you will still be able to access the RPMs on the CD or DVD. You will need to mount the CD or DVD on the rescue filesystem to do this.
The next stage of the rescue environment will scan your disks and attempt
to mount your partitions under /mnt/sysimage. Note that you have the option
to mount read/write, read-only, or to skip and not mount or attempt to
mount any partition. Here is where you ask yourself "what do I need to
do?" Only you know if you've experienced a drive crash and possible
data loss. Do you need to check or repair your partitions? If so, you'll
need to skip mounting - running fsck on mounted partitions is a
bad idea.
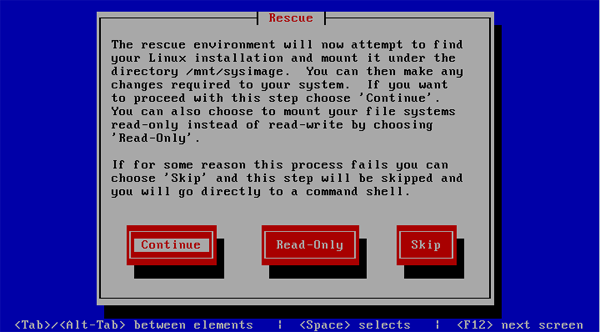
If you choose to mount your partitions, you'll see the following screen.
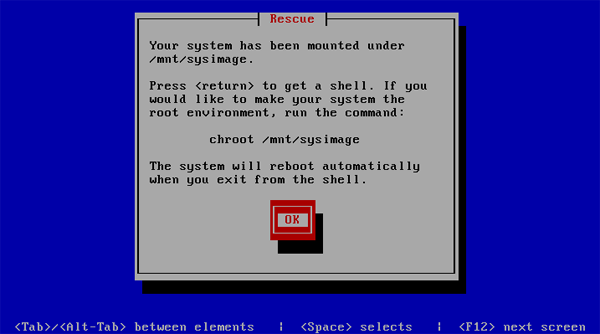
At this point, you can get started with troubleshooting and checking for
errors. Good places to start looking for problems depend on your particular
situation. System logs are always an excellent place if you are unsure of
the exact nature of your problem. Again, /boot/grub/grub.conf,
/etc/fstab, and /etc/inittab are the most common places
for errors that will prevent normal system startup.
If you get this next screen as a result of trying to mount your system
partitions, it is likely that you have an error in the
/etc/fstab file and a partition is being incorrectly specified
as your root device. You can check that your partitions are correctly
labeled and listed in /etc/fstab by writing down your
/etc/fstab file and running e2label
/dev/partition over your partitions. If you're not sure
what they are, you can get a listing by running fdisk -l
<your_device>.
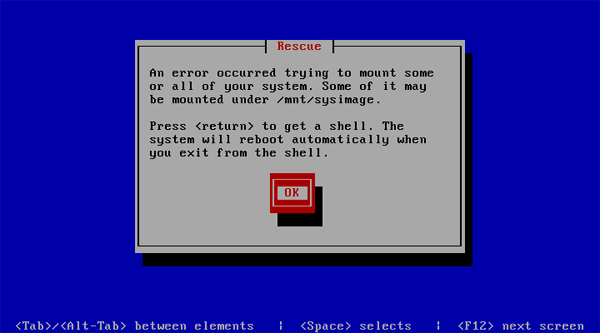
This often comes up when you need to append an option to the GRUB boot stanza - at which point you find out that the last sysadmin neglected to leave us that information. Or we need to be able to boot into a different runlevel or emergency mode for troubleshooting - and a GRUB password is preventing us from doing this. Some system administrators think that a GRUB password is going to save them from unauthorized access; unfortunately, this is not true. If some one can touch your console, they can acquire complete access to your system and data.
linux
rescue.vi /mnt/sysimage/boot/grub/grub.confAs they say, "physical access equals root access."
When you are troubleshooting, and you suspect that some critical files were
altered or a package became corrupted, the following command can be used to
verify that the file is still the same as it was in the RPM: rpm -Vf
/path/file. To verify if a specific RPM that was downloaded or is
on removable media is intact, use rpm -Vp
packagename.rpm. Recall that you can access the RPMs on the
install CD or DVD for reinstallation, although you'll need to mount that CD
or DVD manually.
linux
rescue.mount /dev/cdrom /mnt/source.rpm --replacepkgs -ivh
/mnt/source/Server/rpmfile.rpm --root /mnt/sysimageThis will restore only the master boot record; note that the partition table will not be recovered by this sequence if it is damaged.
linux
rescue.chroot /mnt/sysimage to enter your Linux environment.grub-install /dev/sda or grub-install
/dev/hda (whatever is appropriate for your hardware.)It's a good idea to save a known-good copy of your MBR and partition table before problems arise; the former may be easy to recreate with GRUB, but the latter can be quite a challenge. To save a copy of both, run the following command:
dd if=/dev/sda of=mbr-parttable bs=512 count=1
This will create a file called "mbr-parttable" which should be saved off-system.
To restore the MBR and the partition table which had been saved with the previous command, run the following (assuming that the file you created is in the current directory):
dd if=mbr-parttable of=/dev/sda bs=512 count=1
When in rescue mode, it's vital to stay focused on what you are doing. Think critically and don't do things haphazardly; pay attention to any errors you see. I personally keep paper notes of any problems that I notice, and document everything I do in detail. Proceeding from there depends on my best estimate of the problem: I may list my partitions and write them down if I believe that's where the problem is. I list the files that are involved with the process or problem that occurred and mark them off one by one in a organized manner as I go down the list. If you're testing out possible solutions, try only one thing at a time and if it is not the correct solution, revert to the previous state before going on to try the next fix. Make copies of files before you edit them. Ask yourself questions about why you would see the problem produce the error that it did. Read logs and see if you can deduce why the error occurred in the first place. A temporary patch may cost you more downtime at an even more inconvenient time later.
Standard Troubleshooting ModelTalkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/prestia.jpg)
Joey was born in Phoenix and started programming at the age fourteen on a Timex Sinclair 1000. He was driven by hopes he might be able to do something with this early model computer. He soon became proficient in the BASIC and Assembly programming languages. Joey became a programmer in 1990 and added COBOL, Fortran, and Pascal to his repertoire of programming languages. Since then has become obsessed with just about every aspect of computer science. He became enlightened and discovered RedHat Linux in 2002 when someone gave him RedHat version six. This started off a new passion centered around Linux. Currently Joey is completing his degree in Linux Networking and working on campus for the college's RedHat Academy in Arizona. He is also on the staff of the Linux Gazette as the Mirror Coordinator.
More XKCD cartoons can be found here.
Talkback: Discuss this article with The Answer Gang
I'm just this guy, you know? I'm a CNU graduate with a degree in physics. Before starting xkcd, I worked on robots at NASA's Langley Research Center in Virginia. As of June 2007 I live in Massachusetts. In my spare time I climb things, open strange doors, and go to goth clubs dressed as a frat guy so I can stand around and look terribly uncomfortable. At frat parties I do the same thing, but the other way around.
Mint Card [review at mint.co.uk]
[[[ html-laden "content" elided - all the good stuff is in the followup response, anyway. -- Kat ]]]
[ Thread continues here (2 messages/4.15kB) ]
Thomas Adam [thomas.adam22 at gmail.com]
2009/1/26 Rick Moen <[email protected]>:
> Quoting Thomas Adam ([email protected]): > >> 2009/1/26 Rick Moen <[email protected]>: >> > 1. Volunteer to administer the school's network. >> > >> > 2. Look up the phrase "Quis custodiet ipsos custodes?" >> >> Surely 2., is only applicable if 1. becomes true for him?> > The #2 item was in part incentive for item #1. > > ("Who is Number One?" "That would be telling.")
Ah. A fan of McGoohan, are you?
-- Thomas Adam
[ Thread continues here (8 messages/14.65kB) ]

![[cartoon]](misc/xkcd/im_an_idiot.png "Sadly, this is a true story. At least I learned about the OS X 'say' command.")