
...making Linux just a little more fun!
Jimmy O'Regan [joregan at gmail.com]
This is a pre-release of apertium-en-ca (because there are some bugs you can't find until after you've released...)
New things:
Vocabulary sync with apertium-en-es 0.7.0 English dialect support (British and American) Initial support for Valentian forms Start of Termcat import - Thanks to Termcat for allowing this, and to Prompsit Language Engineering for facilitating it. At the moment, only a few items have been important. They have mostly been limited to terms which include ambiguous nouns (temps, estació, etc.)Caveats:
The vocabulary sync is not complete: specifically, I skipped some proverbs, and had to omit the verb 'blog'. The Valentian support is not as complete as apertium-es-ca (on the other hand, the English dialect support is better than en-es)
This release also includes several multiwords harvested from Francis Tyers' initial investigations into lexical selection (and others suggested by it).
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
Jimmy O'Regan [joregan at gmail.com]
Announcing apertium-ht-en 0.1.0
In response to a request from volunteers at Crisis Commons (http://crisiscommons.org), we have put some effort into creating a Haitian Creole to English module for Apertium. We do not usually make releases at such an early stage of development, but because of the circumstances, we think it's better to make available something that at least partly works, despite its numerous flaws, than to hold off until we can meet our usual standards.
The present release is for Haitian Creole to English only; much of the vocabulary was derived from a spell checking dictionary using cognate induction methods, and is most likely incorrect -- CMU have graciously provided Open Source bilingual data, but have deliberately used a GPL-incompatible licence, which we cannot use. We hope that they will see fit to change this.
Many thanks to Kevin Scannell for providing us with spell checking data; to Francis Tyers and Kevin Unhammer for their contributions; and to the Apertium community for their support and indirect help.
I would like to dedicate this releas to the memory of my grandmother, Anne O'Regan, who passed away on Monday the 18th, just after I began working on this.
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
[ Thread continues here (3 messages/4.68kB) ]
Peter Hűwe [PeterHuewe at gmx.de]
Dear TAG,
unfortunately I have to create a whole bunch of schematas, charts, diagrams, flow charts, state machines (fsm) and so on for my diploma thesis - and I was wondering if you happen to know some good tools to create such graphics.
Of course I know about dia, xfig, (open office draw), gimp, inkscape - but either the diagrams look really really old-fashioned (dia, xfig) or are rather cumbersome to create (gimp, inkscape, draw) - especially if you have to modify them afterwards.
So I'm looking for a handful of neat tools to create some appealing schematas.
Unfortunately I can't provide a good example - but thinks, like colors,
borders,round edges are definitely a good start 
I have to admit that it is arguable whether some eye-candy is really necessary in a scientific paper - however adding a bit of it, really helps the reader to get the gist of the topic faster.
Thanks, Peter
[ Thread continues here (5 messages/6.36kB) ]
Suramya Tomar [security at suramya.com]
Hey,
I know it sounds kind of weird but I want to know if it is possible to identify what process/program is creating this particular directory on my system.
Basically, in my home folder a directory called "Downloads" keeps getting created at random times. The directory doesn't have any content inside it and is just an empty folder.
I thought that it was probably being created by one of the applications I run at the time but when I tried to narrow down the application by using each one separately and waiting for the directory to be created I wasn't able to replicate the issue.
I also tried searching on Google for this but seems like no one else is having this issue or maybe my searches are too generic.
I am running Debian Testing (Squeeze) and the applications I normally have running are:
* Firefox (3.6) * Thunderbird (3.0.1) * Dolphin (Default KDE 4.3.4 version) * Konsole (3-4 instances) * EditPlus using wine * Amarok (1.4.10) * ksensors * Tomboy Notes * xchat * gnome-system-monitor
BTW, I noticed the same behavior when I was using Ubuntu last year (9.10).
Any idea's on how to figure this out? Have any of you noticed something similar on your system?
- Suramya
-- ------------------------------------------------- Name : Suramya Tomar Homepage URL: http://www.suramya.com -------------------------------------------------************************************************************
[ Thread continues here (7 messages/8.29kB) ]
[ In reference to "/launderette.html" in LG#170 ]
Jimmy O'Regan [joregan at gmail.com]
2009/12/26 Ben Okopnik <[email protected]>:
> On Sat, Dec 26, 2009 at 12:08:04PM +0000, Jimmy O'Regan wrote: >> http://www.bobhobbs.com/files/kr_lovecraft.html >> >> "Recursion may provide no salvation of storage, nor of human souls; >> somewhere, a stack of the values being processed must be maintained. >> But recursive code is more compact, perhaps more easily understood– >> and more evil and hideous than the darkest nightmares the human brain >> can endure. " > > [blink] Are you saying there's anything something wrong with ':(){ :|:&};:'? > Or, for that matter, with 'a=a;while :;do a=$a$a;done'? Why, I use them all > the time! > > ...Then, after rebooting the poor hosed machine, I talk about > implementing user quotas and so on. Good illustrative tools for my > security class, those.
Just started reading the new pTerry, and this mail and the following quote somehow resonated for me...
'I thought I wasn't paid to think, master.' 'Don't you try to be smart.' 'Can I try to be smart enough to get you down safely, master?'
But then, every Discworld book is full of such nuggets ...
More important right now was what kind of truth he was going to have to impart to his colleagues, and he decided not on the whole truth, but instead on nothing but the truth, which dispensed with the need for honesty.
''ow do I know I can trust you?' said the urchin. 'I don't know,' said Ridcully. 'The subtle workings of the brain are a mystery to me, too. But I'm glad that is your belief.'
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
[ In reference to "The Village of Lan: A Networking Fairy Tale" in LG#170 ]
Rick Moen [rick at linuxmafia.com]
Forwarding with Peter's permission.
----- Forwarded message from Peter Hüwe <[email protected]> -----
From: Peter Hüwe <[email protected]> To: [email protected] Date: Tue, 5 Jan 2010 02:09:58 +0100 Subject: Thanks for your DNS articles in LGHi Rick,
I just stumbled upon your DNS articles in Linux Gazette and although I first though this topic is not that interesting for me it turned out to be really really interesting!
I found out that the dns I used to use (dns from my university) was horribly slow and seemed not to use any caching mechanism - first request 200-300ms, second request 200-300ms :/
Then I checked out other dns servers like googles and opendns which were quite fast (1st ->130 2nd ->30ms).
But as I don't like using google for everything (no googlemail account here
and I really dislike the "wrong" answer of opendns for nonexistent domains
(as it breaks google search by typing into firefox url bar)
-> I eventually installed Unbound and I'm really really happy with it.
Installation was really easy and the results are tremendous (especially given
the fact that I surf most of the time on only a handful pages) - so speedup
from 300ms to 0(for the second hit) - that's really nice.
The only minor drawback I see is that (as I have to run it locally on my box -
yes I'm one of your oddballs it looses its cache after reboot. - do you
happen to know if there is something I could do against that?
Anyways - thank you for your great articles and improving my internet experience even further.
Kind regards, Peter
----- End forwarded message -----
[ Thread continues here (3 messages/7.07kB) ]
Mulyadi Santosa [mulyadi.santosa at gmail.com]
Most CLI aficionados use this kind of construct when executing a command over "find" results:
$ find ~ -type f -exec du -k {} \;
Nothing is wrong with that, except that "du" is repeatedly called with single argument (that is the absolute path and the file name itself). Fortunately, there is a way to cut down the number of execution:
$ find ~ -type f -exec du -k {} +
Replacing ";" with "+" would make "find" to work like xargs does. Thus du -k will be examining the size of several files at once per iteration.
PS: Thanks to tuxradar.com for the knowledge!
-- regards, Mulyadi Santosa Freelance Linux trainer and consultant blog: the-hydra.blogspot.com training: mulyaditraining.blogspot.com
[ Thread continues here (2 messages/1.80kB) ]
Mulyadi Santosa [mulyadi.santosa at gmail.com]
Wants a quick way to scale up/down your image file? Suppose you want to create proportionally scaled down version of abc.png with width 50 pixel. Execute:
$ convert -resize 50x abc.png abc-scaled.png
-- regards, Mulyadi Santosa Freelance Linux trainer and consultant blog: the-hydra.blogspot.com training: mulyaditraining.blogspot.com
By Deividson Luiz Okopnik and Howard Dyckoff

|
Contents: |
Please submit your News Bytes items in plain text; other formats may be rejected without reading. [You have been warned!] A one- or two-paragraph summary plus a URL has a much higher chance of being published than an entire press release. Submit items to [email protected]. Deividson can also be reached via twitter.
 Linux.com Launches New Jobs Board
Linux.com Launches New Jobs BoardThe Linux Foundation has created a new Linux Jobs Board at Linux.com: http://jobs.linux.com/. The new Linux.com Jobs Board can provide employers and job seekers with an online forum to find the best and brightest Linux talent or the ideal job opportunity.
The JobThread Network, an online recruitment platform, reports that the demand for Linux-related jobs has grown 80 percent since 2005, showing that Linux represents the fastest growing job category in the IT industry.
"Linux's increasing use across industries is building high demand for Linux jobs despite national unemployment stats," said Jim Zemlin, executive director at the Linux Foundation. "Linux.com reaches millions of Linux professionals from all over the world. By providing a Jobs Board feature on the popular community site, we can bring together employers, recruiters, and job seekers to lay the intellectual foundation for tomorrow's IT industry."
Employers interested in posting a job opening have two options; they can post their openings on Linux.com and reach millions of Linux-focused professionals, or they can use the JobThread Network on Linux.com to reach an extended audience that includes 50 niche publishing sites with a combined 9.8 million visitors every month. For more information and to submit a job posting, please visit: http://jobs.linux.com/post/.
Job seekers can include their LinkedIn details on their Linux.com profiles, including their resumes. They can also subscribe to the Linux.com Jobs Board RSS feed, receive alerts by e-mail, and follow opportunities about Linux-related jobs on Twitter at www.twitter.com/linuxdotcom.
Linux.com hosts a collaboration forum for Linux users and developers to connect with each other. Information on how Linux is being used, such as in embedded systems, can also be found on the site. To join the Linux.com community, which currently has more than 11,000 registered members, go to: http://www.linux.com/community/register/.
Google moves to ext4Search and software giant Google is now in the process of upgrading its storage infrastructure from the ext2 filesystem to ext4.
In a recent e-mail post, Google engineer Michael Rubin explained that "...the metadata arrangement on a stale file system was leading to what we call 'read inflation'. This is where we end up doing many seeks to read one block of data."
Rubin also noted that "...For our workloads, we saw ext4 and xfs as 'close enough' in performance in the areas we cared about. The fact that we had a much smoother upgrade path with ext4 clinched the deal. The only upgrade option we have is online. ext4 is already moving the bottleneck away from the storage stack...."
In a related move, Ted Ts'o has joined Google, after concluding his term as CTO of the Linux Foundation. Ts'o participated in creating the ext4 filesystem.
Firefox Grows 40% in 2009, 3.5 now most PopularUsage data gathered by Statcounter.com at the end of December showed Mozilla's Firefox 3.5 finally surpassed both IE 7 and IE 8 to become the world's most popular Web-browsing software. Holiday sales brought IE 8 within a hair of overtaking Firefox, but the latter still was ahead in mid-January. See the graph for all browsers, here: http://gs.statcounter.com/#browser_version-ww-weekly-200827-201002/.
However, combined usage of both IE 7 and IE 8 was almost 42% vs. 30.5% for both the 3.0 and 3.5 versions of Firefox.
According to the Metrics group at Mozilla, the worldwide growth rate for Firefox adoption was 40% for 2009. The number of active daily users was up an additional 22.8 million for 2009, higher than the 16.4 million users added in 2008.
This increase occurred despite delaying the release of Firefox 3.6 until late January. This next version of the open source browser from the Mozilla Foundation will feature improvements in stability, security, and customization, and will also offer features for location-aware browsing.
A release candidate for 3.6 was available in mid-January. The next milestone release, version 4.0, has been pushed back until the end of 2010. It will feature separate processes for each tab, like Google Chrome, and a major UI update.
According to StatCounter, this was Firefox's market share as of Dec '09:
29% Africa
26% Asia
41% Europe
31% North America
32% South America
http://blog.mozilla.com/metrics/2010/01/08/40-firefox-growth-in-2009/.
European Commission Approves Oracle's Acquisition of SunOn January 21, Oracle Corporation received regulatory approval from the European Commission for its acquisition of Sun Microsystems. Oracle expects approval from China and Russia to follow, and expects its Sun transaction to close quickly.
The European Commission had been under pressure from some of the founders of MySQL to separate it from the Sun acquisition on competitive grounds. However, Marten Mickos, the former CEO of MySQL, and others had argued that the famed open source database was already on a dual commercial and open source development model, and that the large community around it could resist any efforts by Oracle to stunt its development.
The Commission found that concerns about MySQL were not as serious as was first voiced. "The investigation showed that although MySQL and Oracle compete in certain parts of the database market, they are not close competitors in others, such as the high-end segment", the Commission said in its announcement. It also concluded that PostgreSQL could become an open-source alternative to MySQL, if that should prove necessary, and was already competing with Oracle's database. The Commission also said that it was now "...satisfied that competition and innovation will be preserved on all the markets concerned."
Oracle hosted a live event for customers, partners, press, and analysts on January 27, 2010, at its headquarters in Redwood Shores, California.
Oracle CEO Larry Ellison, along with executives from Oracle and Sun, outlined the strategy for the combined companies, product roadmaps, and the benefits from having all components - hardware, operating system, database, middleware, and applications - engineered to work together. The event was broadcast globally, and an archive should be available at http://www.oracle.com/sun/.
The Southern California Linux Expo (SCALE) returns for its third year to the Westin LAX Hotel. Celebrating its eighth year, SCALE's success owes, in part, to its unique format of a main weekend conference with Friday specialty tracks.
This year's main weekend conference consists of five tracks: beginner, developer, and three general interest tracks. Topics span all interest levels, with topics such as a review of desktop operating systems, in-depth programming and scripting with open source languages, and a discussion of the current state of open source. In addition, there will be over 80 booths hosted by commercial and non-commercial open source enthusiasts.
The Friday specialty tracks consist of Women In Open Source ("WIOS"), and Open Source Software In Education ("OSSIE").
http://socallinuxexpo.org/.Join us in San Jose, CA, February 23-26, 2010, for USENIX FAST '10.
At FAST '10, explore new directions in the design, implementation, evaluation, and deployment of storage systems. Learn from leaders in the storage industry, beginning Tuesday, February 23, with ground- breaking file and storage tutorials by industry leaders such as Brent Welch, Marc Unangst, Michael Condict, and more. This year's innovative 3-day technical program includes 21 technical papers, as well as two keynote addresses, Work-in-Progress Reports (WiPs), and a Poster Session. Don't miss this unique opportunity to meet with premier storage system researchers and industry practitioners from around the globe.
Register by February 8 and save! Additional discounts are available!
http://www.usenix.org/fast10/lg

Are you sold on using Open Source but find management holds you back because they don’t understand it? We come up against this all the time so we’ve organized a conference for senior execs to help explain the benefits of Open Source, to be held in the 1st week of March.
We have speakers from vendors and SIs as well as the community to help get the message across. If nothing else it could be a welcome escape from the cold, we’re hosting it in sunny Malta :)
Go to http://www.ricston.com/bizcon-europe-2010-harnessing-open-source/ for more info and help us show management how Open Source can be a great asset to them as well as us. And thanks for helping us out!
http://www.ricston.com/bizcon-europe-2010-harnessing-open-source/Join us in San Jose, CA, April 28-30, 2010, for USENIX NSDI '10.
At NSDI '10, meet with leading researchers to explore the design principles of large-scale networked and distributed systems. This year's 3-day technical program includes 29 technical papers with topics including cloud services, Web browsers and servers, datacenter and wireless networks, malware, and more. NSDI '10 will also feature a poster session showcasing early research in progress. Don't miss this unique opportunity to meet with premier researchers in the computer networking, distributed systems, and operating systems communities.
Register by April 5 and save! Additional discounts are available!
http://www.usenix.org/nsdi10/lg
 SimplyMEPIS 8.0.15 Update and 8.5 beta4 Released
SimplyMEPIS 8.0.15 Update and 8.5 beta4 ReleasedMEPIS LLC has released SimplyMEPIS 8.0.15, an update to the community edition of MEPIS 8.0. The ISO files for 32- and 64-bit processors are SimplyMEPIS-CD_8.0.15-rel_32.iso and SimplyMEPIS-CD_8.0.15-rel_64.iso.
SimplyMEPIS 8.0 uses a Debian Lenny Stable foundation, enhanced with a long-term support kernel, key package updates, and the MEPIS Assistant applications to create an up-to-date, ready to use system providing a KDE 3.5 desktop.
This release includes recent Debian Lenny security updates as well as MEPIS updates that are compatible between MEPIS versions 8.0 and 8.5. The MEPIS updates include kernel 2.6.27.43, openoffice.org 3.1.1-12, firefox 3.5.6-1, flashplugin-nonfree 2.8, and bind9 9.6.1P2-1.
Warren Woodford announced that SimplyMEPIS 8.4.96, the beta4 of MEPIS 8.5, is available from MEPIS and public mirrors. The Mepis 8.5 beta includes a Debian 2.6.32 kernel.
Warren said, "Even though the past two weeks were a holiday time, we have been busy. In this beta, I did a lot work on the look and feel of the KDE4 desktop."
The ISO files for 32- and 64-bit processors are SimplyMEPIS-CD_8.4.96-b4_32.iso and SimplyMEPIS-CD_8.4.96-b4_64.iso respectively. Deltas, requested by the community, are also available.
ISO images of MEPIS community releases are published to the 'released' sub-directory at the MEPIS Subscriber's Site, and at MEPIS public mirrors. Find downloads at http://www.mepis.org/.
Sun Microsystems Unveils Open Source Cloud Security ToolsAs part of its strategy to help customers build public and private clouds that are open and interoperable, Sun Microsystems, Inc. is offering open source cloud security capabilities and support for the latest Security Guidance from the Cloud Security Alliance. For more information on Sun's Cloud Security initiatives, visit http://www.sun.com/cloud/security/.
Leveraging the security capabilities of Sun's Solaris Operating Systems, including Solaris ZFS and Solaris Containers, the security tools help to secure data in transit, at rest, in use in the cloud, and work with cloud offerings from leading vendors including Amazon and Eucalyptus.
Along with introducing new security tools in December, Sun also announced support for the Cloud Security Alliance's "Guidance for Critical Areas of Focus in Cloud Computing - Version 2.1." Sun privacy and security experts have been instrumental in the industry-wide effort to develop the security guidance, and have been active participants in the Cloud Security Alliance since its inception. The new framework provides more concise and actionable guidance for secure adoption of cloud computing, and encompasses knowledge gained from real world deployments. For more information, visit http://www.cloudsecurityalliance.org/guidance/.
Sun also published a new white paper, "Building Customer Trust in Cloud Computing with Transparent Security," that provides an overview of the ways in which intelligent disclosure of security design, practices, and procedures can help improve customer confidence while protecting critical security features and data, improving overall governance. To download the paper, visit http://www.sun.com/offers/details/sun_transparency.xml.
Sun announced availability for several open source Cloud Security tools including:
To download the Cloud Safety Box, visit http://kenai.com/projects/s3-crypto/pages/Home/.
For more information on Sun's cloud technologies and Sun Open Cloud APIs, visit http://www.sun.com/cloud/.
Canonical Announces Bazaar Commercial ServicesCompanies and open source projects interested in using Canonical's popular version control system now have access to a suite of commercial services - Consultancy & Conversion, Training, and Support - allowing them to migrate, deploy, and manage Bazaar.
Used by Ubuntu and other open source and commercial projects, Bazaar (bzr) is a version control system (VCS) that supports distributed development environments. Many existing version control systems use a centralised model, a particular challenge to globally distributed 'chase the sun' development teams. Although bzr itself is open source, there is no requirement for commercial projects to make their code publicly available.
Sun Microsystems migrated the code for its MySQL database software a year ago, using bzr conversion and support services. "We wanted to use a tool which suited our distributed contributor model for MySQL, but we needed the reassurance of access to the Bazaar development team through our transition and use of the VCS," said Jeffrey Pugh, vice president of MySQL Engineering, Sun Microsystems. "We have found bzr works really well for our model, and that the bzr support team and developers have been responsive to our requirements."
"The increasingly distributed nature of software development has allowed Bazaar to grow in popularity," said Martin Pool, project manager at Canonical. "Our Consultancy & Conversion, Training, and Support services give new and existing customers piece of mind when setting up such a vital piece of infrastructure."
Canonical is now offering comprehensive training in Bazaar to get staff up-to-speed quickly and transfer best practice knowledge. Both the content and delivery are tailored to meet the needs of individual teams and development environments, so developers can get the most out of the training sessions.
Visit the project site here: http://bazaar.canonical.com/en/, or Canonical's Bazaar page here: http://www.canonical.com/projects/bazaar/.
Canonical offers support program for Lotus SymphonyAt IBM Lotusphere in January, Canonical announced a dedicated support program for Lotus Symphony, the no-charge office productivity component of the IBM Client for Smart Work (ICSW) on Ubuntu. This support is made available to customers by Canonical through the IBM and Canonical partner network.
The IBM Client for Smart Work helps organisations save up to 50 percent per seat on software costs versus a Microsoft-based desktop, in addition to avoiding requisite hardware upgrades. The package allows companies to use their existing PCs, lower-cost netbooks, and thin clients.
The open standards-based core solution comprises of Ubuntu 8.04 LTS Desktop Edition and Lotus Symphony, which includes word processing, spreadsheets, and presentations, fully supported by Canonical at US $5.50 per user, per month based on 1000 seat deployment. Optional solution components include desktop virtualisation and recovery options using VERDE from Virtual Bridges, and a variety of Lotus collaboration capabilities with choice of delivery model: on site, on the cloud, or using an appliance.
"The economic case for Ubuntu and the IBM Client for Smart Work is unarguable," says Shiv Kumar, EVP of Sales at ZSL, one of the first IBM and Canonical partners to make this solution available. "The addition of support from Canonical at super-competitive pricing means companies have the reassurance of world class support through the entire stack."
IBM Client for Smart Work for Ubuntu core solution is available (unsupported) at no charge from http://www.ubuntu.com/partners/icsw.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/dokopnik.jpg)
Deividson was born in União da Vitória, PR, Brazil, on 14/04/1984. He became interested in computing when he was still a kid, and started to code when he was 12 years old. He is a graduate in Information Systems and is finishing his specialization in Networks and Web Development. He codes in several languages, including C/C++/C#, PHP, Visual Basic, Object Pascal and others.
Deividson works in Porto União's Town Hall as a Computer Technician, and specializes in Web and Desktop system development, and Database/Network Maintenance.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.


I am trying to compile a body of work on an overall theme that I call Taming Technology. (I have wrestled with several different names, but that is my title du jour.) The theme deals with troubleshooting, problem solving, problem avoidance, and analysis of technology failures.
Case studies are an important part of this ambitious project. "Installing Fedora Core 10" is an example. It deals with my attempts to perform a network kickstart install of Fedora Core 10.
Part 1, Lessons from Mistakes, outlines my plans, briefly compares CD installation with network installation, and proceeds to early success and unexpected debacle.
In Part 2, Bootable Linux, I discuss some of the uses of the Knoppix Live Linux CD, before explaining how I used Knoppix to gather information needed for a network installation. I also use Knoppix to diagnose the problems encountered in Part 1. This leads to the discovery that I have created even more problems. Finally, I present an excellent solution to the major problem of Part 1.
In Part 3 and 4, I finally get back on-track, and present detailed instructions for installing Fedora Core 10 over a network, using PXE boot, kickstart, and NFS. Part 3 details PXE boot including troubleshooting; Part 4 takes us the rest of the way.
I think it's important for people to realise that they are not alone when they make mistakes, that even so-called experts are fallible.
Isaac Asimov wrote a series of robot stories. (I don't imagine for one moment that I'm Isaac Asimov.) To me, the most captivating facet of these stories was the unanticipated consequences of interactions between the Three Laws of Robotics. I like to think that I write about the unanticipated consequences of our fallible minds: we want X, we think we ask for X, but find we've got Y. Why?
[ Highly amusing coincidence: a possible answer to Henry's question is contained in the "XY Problem" - except for the terms X and Y being reversed. -- Ben ]
In my real life, I embark on a project, something goes wrong, there is
often the discovery that the problems multiply. After several detours,
I finally get a happy ending.
-- Henry Grebler
The Cowboy materialised at the side of my desk. I wondered uneasily how long he had been standing there.
"When you've got some time," he began, "can I get you to look at a problem?"
"Tell me about it," I replied.
He looked around, and pulled up a chair. This was going to be interesting. His opening gambit is usually, "Quick question," almost invariably followed by a very long and complicated discussion that gives the lie both to the idea that the question will be short and the implication that it won't take long to answer.
To me, a quick question is something like, "Is today Monday?" The Cowboy's "quick" questions are about the equivalent of, "What's the meaning of life?" or "Explain the causes of terrorism."
If he had decided to sit down, how momentous was this problem?
By way of preamble, he conceded that The Russian had been trying to install Oracle on the machine in question. He wasn't sure if there was a connection, but now The Russian couldn't run VNC. It turned out that, when he tried to run a vncserver, he got a message like:
no free display number on suseq
Sure enough, when I tried to run a vncserver on suseq I got the same message. I used ps to tell me how many vnc sessions were actually running on this machine (ps auxw | grep vnc); a small number (3 or 4).
When I tried picking a relatively high display number, I was told it was in use:
vncserver :13 A VNC server is already running as :13
Similarly for a really really high number:
vncserver :90013 A VNC server is already running as :90013
This perhaps was enough information to diagnose the problem (it is, in hindsight), but seemed too startling to be believable.
To get a better understanding of why vncserver was behaving so strangely, I decided to trace it[1]. I used a bash function called 'truss'[2], so the session looked a bit like this:
truss vncserver New 'X' desktop is suseq:6 Starting applications specified in /home/henryg/.vnc/xstartup Log file is /home/henryg/.vnc/suseq:6.log
This was even more unbelievable - if I traced vncserver, it seemed to work! (It doesn't really matter whether it actually worked, or just seemed to work; tracing the application changed its behaviour.) This may be a workaround, but it explained nothing and raised even more question than were on the table going in.
At this point, I suggested to The Cowboy that it did not look like the problem would be solved any time soon, and he might as well leave it with me. I also thought a few minutes away from my desk wouldn't hurt.
After making myself a coffee, I went over to Jeremy and told him about the strange behaviour with trace. I wasn't really looking for help; just wanting to share what a weird day I was having.
I went back to my desk to do something that would succeed. There are times during the task of problem-solving when you find yourself picking losers. Whatever you try backfires. Several losses in a row tend to send your radar out of kilter. At such times, it's a good idea to get back onto solid ground, to do anything that is guaranteed to succeed. Then, with batteries recharged after a couple of wins, your frame of mind for tackling the problem is immensely improved.
A few minutes later, Jeremy came to see me. He had an idea. At first, I could not make any sense of it. When I understood, I thought it was brilliant - and certainly worth a try.
He suggested that I trace the bash command-line process from which I was invoking vncserver.
So, in the xterm window where I had tried to run vncserver, I did
echo $$ 5629
The number is the process id (pid) of the bash process.
In another xterm window, I started a trace:
truss -p 5629
Now, back in the first window, I invoked vncserver again:
vncserver no free display number on suseq
So, Jeremy's idea had worked! (Trussing bash rather than vncserver had allowed me to capture a trace of vncserver failing.)
I killed the truss and examined the output. What it showed was that the vncserver process had tried many sockets and failed with "Address already in use", e.g.:
bind(3, {sa_family=AF_INET, sin_port=htons(6099),
sin_addr=inet_addr("0.0.0.0")}, 16) = -1 EADDRINUSE (Address
already in use)
The example shows an attempt to bind to port 6099. This was near the bottom of the truss output. Looking backwards, I saw that it had tried ports 6098, 6097, ... prior to port 6099. Clearly vncserver had cycled through a fairly large number of ports, and had failed on all of them.
Why were all these ports busy? I tried to see which ports were in use:
netstat -na
Big mistake! (I should have known.) I was flooded with output. How much output? Good question:
netstat -na | wc
After a very long time (10 or 15 seconds - enough time to issue the same command on another machine), it came back with not much less than 50000! That's astronomical! On the other machine with the problem, there were more than 40000 responses - still huge. A typical machine runs about 500 sockets.
After that, the rest was easy. The suspicion was that Oracle was hogging all the ports. That's probably not how it's meant to behave, but I don't have a lot of experience with Oracle.
I suggested to The Russian that he try to shut down Oracle and see if that brought the number of sockets in use down to a reasonable number; If not, he should reboot.
In either case, he should then start a trivial monitor in an xterm:
while true do netstat -na | wc sleep 1 done
and then do whatever he was doing to get Oracle going. As soon as the answer from the monitor rose sharply, he would know that whatever he had been doing at that time was probably responsible. If he was doing something wrong, he might then have an indication where to look. If not, he had something to report to the Oracle people.
1. Not all exercises in problem-solving result in a solution with all the loose ends tidied up. In this case, all that had been achieved is that a path forward had been found. It might lead to a solution, it might not. If not, they'll be back.
2. Never underestimate the power of involving someone else. In this case, the someone else came back and provided me with a path forward.
Often, in other cases (and I've seen this dozens of times, both as the presenter and as the listener), the person presenting the problem discovers the solution during the process of explaining the problem to the listener. I have been thanked profusely for helping to solve a problem I did not understand. It is, however, crucial that the listener give the impression of understanding the presenter. For some reason, explaining the problem to the cat is just not as effective.
[1] "Tracing" is an activity for investigating what a process (program) is doing. Think of it as a stethoscope for computer doctors. The Linux command is strace(1) - "trace system calls and signals."
[2] After years of working in mixed environments, I now tend to operate in my own environment. In a classic metaphor for "ontogeny mimics phylogeny", my abbreviations and functions contain markers for the various operating systems I've worked with: "treecopy" from my Prime days in the early '80s, "dsd" from VMS back in the mid '80s, "truss" from Solaris in 1998, etc.
In this case, I used my bash function, "truss", which has all the options I usually want adjusted depending on the platform on which the command is running. Under Solaris, my function "truss" will invoke the Sun command "truss". Since this is a SUSE Linux machine, it will invoke the Linux command "strace" (with different options). It's about concentrating on what I want do rather than how to do it.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/grebler.jpg)
Henry was born in Germany in 1946, migrating to Australia in 1950. In his childhood, he taught himself to take apart the family radio and put it back together again - with very few parts left over.
After ignominiously flunking out of Medicine (best result: a sup in Biochemistry - which he flunked), he switched to Computation, the name given to the nascent field which would become Computer Science. His early computer experience includes relics such as punch cards, paper tape and mag tape.
He has spent his days working with computers, mostly for computer manufacturers or software developers. It is his darkest secret that he has been paid to do the sorts of things he would have paid money to be allowed to do. Just don't tell any of his employers.
He has used Linux as his personal home desktop since the family got its first PC in 1996. Back then, when the family shared the one PC, it was a dual-boot Windows/Slackware setup. Now that each member has his/her own computer, Henry somehow survives in a purely Linux world.
He lives in a suburb of Melbourne, Australia.
Ever since the start of the Internet, electronic mail has been a mainstay for communication. Even as new social networking phenomena such as online-friend connection databases and microblogging are taking communication on the Web by storm, e-mail still remains a preferred means of communication for both personal and official purposes, and is unlikely to fade away soon.
One aspect of e-mail that we often observe is the sender's signature - the tiny blurb that appears on the bottom. If it's an official e-mail, then you're most likely constrained to keep it something sober that talks about your position at work, or similar details. However, if you are mailing friends, or a mailing list, then wouldn't it be nice to have a signature that is customized and/or chosen from a random set of signatures? Several Web-based e-mail services offer this already; a cursory Web search reveals that services such as GMail offer this feature. However, the customizability is limited, and you are restricted in several ways. However, if you use a customizable mail client like Mutt, several fun things can be done with e-mail signatures, using more specific details that are within your control.
In this article, I describe one of the possible ways of having random signatures in your e-mail in the Mutt mail client, and switching signature themes and styles based on certain characteristics, such your inbox or recipient. I will, therefore, assume that you have a working configuration for Mutt ready, though the concept I describe applies equally well to other mail clients which support this, such as Pine. I'll make use of the BSD/Unix fortune program (available in almost all GNU/Linux and *BSD distributions) in this article, though any solution that chooses random quotes would do.
The Unix fortune program is a simple program that uses a database of strings (called "fortunes") to randomly choose a string and display it onto the screen. The program is named appropriately, since it uses a collection of files on various subjects to display messages, much like those on fortune cookies.
It is usually easy to install the program on most GNU/Linux distributions. For example, on Debian/Ubuntu-like systems, the following command will fetch the fortune program and several databases of strings:
apt-get install fortune-mod fortunes
Similarly, yum install fortune-mod should help on Red Hat/Fedora-like systems. It shouldn't be too hard to figure out how to install it on your GNU/Linux or BSD distribution.
Once installed, you can test out the existing files. For example, on my Debian machine, the following command lists a random signature from one of the /usr/share/games/fortunes/linux or /usr/share/games/fortunes/linuxcookie files:
fortune linux linuxcookie
If you now open one of the files in /usr/share/games/fortunes/, such as linux, you'll observe that they consist of strings which are separated by the "%" sign, resembling the format of this file:
An apple a day keeps the doctor away. % A stitch in time saves nine. % Haste makes waste
Also, associated with each file, such as linux, is a .dat file, e.g. linux.dat. The way fortune works is that it looks for the file specified at the command line, (absent such a command line option, choosing a random file among those in the path searched by default), and looks for a corresponding .dat file, which has a table of file offsets for locating strings in that file. If it doesn't find the dat file corresponding to a text file with signatures, it ignores that file.
While you can use the signatures present already, if you want to create and use your own signatures, get them from wherever you want, and place them in a file, separated by % signs as discussed above. For example, I'll put the above file in a location called $HOME/Signatures. Let me call my file $HOME/Signatures/adages. To use it with fortune, I use the strfile program to generate the table of offsets:
[~/Signatures] strfile adages "adages.dat" created There were 3 strings Longest string: 38 bytes Shortest string: 18 bytes
Now, running fortune with the full path of the file causes a random string to be displayed from the above file. (Note that the full path must be provided, if the file is outside the default fortunes directory.)
$ fortune $HOME/Signatures/adages Haste makes waste
The fortune program is versatile, and has several options. Be sure to read its manual page for more details.
The fortune output is a random string, and often, these strings are too long for use as good signatures in your e-mail. To avoid such situations, we make use of the -s option so fortune will display only short strings. The default definition of a short string is up to 160 characters, but you can override it with the -n option. For example:
fortune -n 200 -s <files>could be a suitable candidate as a signature file.
Now, you're ready to use your neat fortunes in Mutt. If you have no custom signature, and want to uniformly use a random signature from your newly created signature file, as well as the default linuxcookie file, then add the following to your .muttrc:
set signature="fortune -n 200 -s linux $HOME/Signatures/adages|"
If this is what you wanted, you're done. However, if you want to customize the signatures based on other parameters such as recipient, or current folder, read on.
Let me describe my setup here. I use the procmail program to filter my mail, and let's say that I've got the following folders of interest:
Now, I want to have the following configuration:
There are simple steps to achieve this using the hooks in Mutt. Note that I have interspersed it with some other configurations for demonstration.
# Set the default options folder-hook . 'set record=+sent; set from=me@my-personal-email; set signature="fortune $HOME/Signatures/adages|"' # Set the custom hooks send-hook [email protected] 'set signature="fortune -n 200 -s linux|"' folder-hook work-mail 'set record=+sent-work; set from=me@my-work-email; set signature="$HOME/.signature-work"'
What the above snippet does is to set, amongst other things, the default signature to be my adages set, and automatically switch the signature to a fixed file, $HOME/.signature-work, when I move to the work-mail folder. Finally, if I send mail to the [email protected] mailing address, the signature is altered to display a fortune from the linux fortunes file. Simple enough, and the possibilities are infinite!
You can scout the Internet to get nice quotations and interesting messages to add to your signatures collection; all you need to do is to put each in the right format, use strfile to enable fortune to use it, and plug it into your Mutt configuration. I often like to hunt for quotations on Wikiquote, amongst other Web sites. While I am sure most of us don't mean any harm while using other people's sentences in our signatures, ensure that you stay on the right side of the law while doing so.
I wish to make a mention of the Linux One Stanza Tip project, which provides a very nice set of signatures with GNU/Linux tips, and more, in their distribution. They also provide templates for you to generate your own signatures with designs and customizations. Sadly, the project doesn't seem to be that active now, but the tips and software provided are very apt and usable even today.
In conclusion, I hope I've managed to show you that with Mutt, you can customize the way you handle signatures in a neat manner. Should you have comments or suggestions to suggestions to enhance or improve this workflow, or just want to say that you liked this article, I'd love to hear from you!
Talkback: Discuss this article with The Answer Gang

Kumar Appaiah is a graduate student of Electrical and Computer Engineering at the University of Texas at Austin, USA. Having used GNU/Linux since 2003, he has settled with Debian GNU/Linux, and strongly believes that Free Software has helped him get work done quickly, neatly and efficiently.
Among the other things he loves are good food, classical music (Indian and Western), bicycling and his home town, Chennai, India.
Many people have made the switch to Linux, and the question that has continued since the kernel hit 0.01 is "where are the games?"
While the WINE project has done a great job at getting quite a few mainstream games working, there are also many Linux-native gems that are fantastic at whittling away the time. No longer content with Solitaire clones, the community is responding with a wide array of fun games.
In this month's review, we are looking at Word War VI. With graphics that initially look straight out of the Atari days, one might be tempted to overlook the game for something a little showier. However, within minutes I was hooked with the Defender-like gameplay, and the fireworks and explosions rippling across the screen had satisfied my eye-candy requirements.
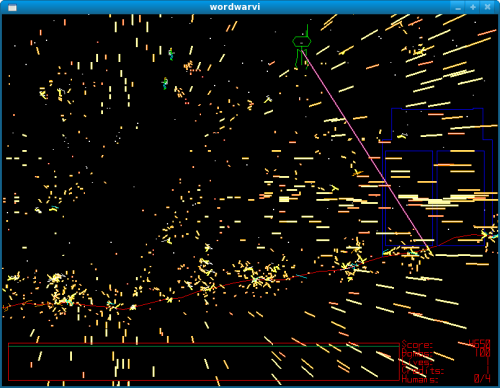
The graphics look like the old 80's arcade shooters, but the polish and smoothness of the visuals make it quite clear that this is an intentional part of the game's aesthetic. Also, a quick look at the game's man page reveal that there is a wealth of options: adjusting how the game looks, the difficulty settings, the choice of bigger explosions (which look awesome), and even a mode where you play as Santa Claus (wordwarvi --xmas).
The controls are simple, mostly relying on the spacebar and arrow keys. The goal is to grab as many humans while avoiding various missiles, alien ships, and other enemies. The real beauty is the 'easy to learn, hard to master' approach, which suits the space-shooter genre just fine.
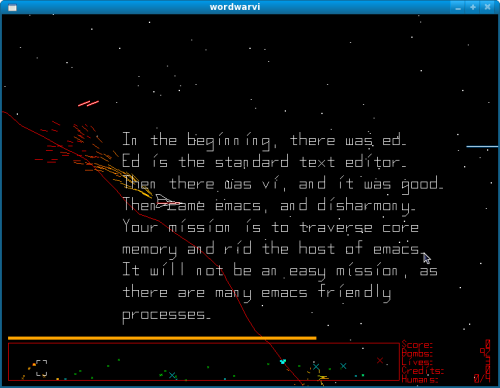
Stephen Cameron's little side-project about "The Battle of the Text Editors" has blossomed into a respectable game. He has done a great job documenting on how to hack the game and extend it even further, leaving endless possibilities of more fun and crazy modes. The source is located at the Word War VI website, though the game is likely already packaged by your distribution.
If there's a game you would like to see reviewed, or have an update on one already covered, just drop me a line.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/crosby.jpg)
Dafydd Crosby has been hooked on computers since the first moment his dad let him touch the TI-99/4A. He's contributed to various different open-source projects, and is currently working out of Canada.
By Rick Moen
Linux users tend, I've noticed, to complain about suckiness on the Web itself, and in their own Web browsers — browser bloat, sites going all-Flash, brain damage inherent in AJAX-oriented "Web 2.0" sites[1], and death-by-JavaScript nightmares. However, the fact is: We've come a long way.
In the bad old days, the best we had was the crufty and proprietary Netscape Communicator 4.x kitchen sink^W^W"communications suite" into which Netscape Navigator 3.x, a decent browser for its day, had somehow vanished. That was dispiriting, because an increasing number of complex Web pages (many of them Front Page-generated) segfaulted the browser immediately, and Netscape Communications, Inc. wasn't fixing it.
Following that was a chaotic period: Mozilla emerged in 1998, with Galeon as a popular variant, and Konqueror as an independent alternative from the KDE/Qt camp. Mozilla developers made two key decisions, the first being the move in October 1998 to write an entirely new rendering engine, which turned out to be a huge success. The rendering engine is now named Gecko (formerly Raptor, then NGLayout), and produced the first stunningly good, modern, world-class browsers, the Mozilla 0.9.x series, starting May 7, 2001. I personally found this to be the first time it was truly feasible to run 100% open source software without feeling like a bit of a hermit. So, I consider May 7, 2001 to be open source's Independence Day.
The second turning point was in 2003, with the equally difficult decision that Mozilla's feature creep needed fixing by ditching the "Mozilla Application Suite" kitchen-sink approach and making the browser separate again: The Mozilla Project thus produced Firefox (initially called "Phoenix") as a standalone browser based on a new cross-platform front-end / runtime engine called XULRunner (replacing the short-lived Gecko Runtime Environment). At the same time, Galeon faltered and underwent a further schism that produced the GNOME-centric, sparsely featured Epiphany browser, and the XULRunner runtime's abilities inspired Conkeror (a light browser written mostly in JavaScript), SeaMonkey (a revival of the Communicator kitchen-sink suite), and Mobile Firefox (formerly Fennec, formerly Minimo).
Anyway, defying naysayers' expectations, Firefox's winning feature has turned out to be its extensions interface, usable by add-on code written in XULRunner's XUL scripting language. At some cost in browser code bloat[2] when you use it extensively, that interface has permitted development of some essential add-ons, with resulting functionality unmatched by any other Web browser on any OS. In this article, I detail several extensions to tighten up Firefox's somewhat leaky protection of your personal privacy, and protect you from Web annoyances. (For reasons I've detailed elsewhere, you should if possible get software from distro packages rather than "upstream" non-distro software authors, except in very exceptional circumstances. So, even though I give direct download links for three Firefox extensions, below, please don't use those unless you first strike out with your Linux distribution's own packages.[1]) I also outline a number of modifications every Firefox user should consider making to the default configuration, again with similar advantages in user privacy and tightening of security defaults. For each such change, I will cite the rationale, so you can adjust your paranoia to suit.
Here begins the (arguable) mild-paranoia portion of our proceedings: Have you ever noticed how eager Web-oriented companies are to help you? You suddenly discover that your software goes out and talks across the Internet to support some "service" you weren't aware you wanted, involving some commercial enterprise with whom you have no business relations. There's hazy information about this-or-that information being piped out to that firm; you're a bit unclear on the extent of it — but you're told it's all perfectly fine, because there's a privacy policy.
There's a saying in the Cluetrain Manifesto, written in part by longtime Linux pundit Doc Searls, that "Markets are conversations." That is, it's a negotiated exchange: You give something; you get something. Sometimes you give information, and, oddly enough, Linux people seem to often miss the key point: information has value, even yours. In a market conversation, you're supposed to be able to judge for yourself whether you want what's being offered, and if you want to donate the cost thereof (such as some of your data). If you have no use for what's being offered, you can and should turn off the "service" -- and that's what this article will cover (or at least let you decide what "services" to participate in, instead of letting others decide for you).
NoScript: The name is slightly misleading: This marvelous extension makes JavaScript, Java, Flash, and a variety of other possibly noxious and security-risking "rich content" be selectively disabled (and initially disabled 100% by default), with you being able to enable on a site-by-site basis, via context menu, which types of scripting you really want to execute. More and more, those scripts are some variety of what are euphemistically called "Web metrics", i.e., data mining attempts to spy on you and track your actions and movements as you navigate the Web. NoScript makes all of that just not work, letting you run only the JavaScript, Flash, etc. that you really want. As a side-benefit, this extension (like many of the others cited) in effect makes the Web significantly faster by reducing the amount of junk code your browser is obliged to process. Available from: http://noscript.net/
Adblock Plus ("ABP"): This extension does further filtering, making a variety of noxious banner ads and other advertising elements just not be fetched at all. Highly recommended, though some people prefer the preceding "Adblock" extension, instead. Privacy implication? Naturally, additional data mining gets disposed of, into the bargain. Available from: http://adblockplus.org/en/
ABP's effectiveness can be substantially enhanced through adding subscriptions to maintained ABP blocklists. I've found that a combination of EasyList and EasyPrivacy is effective and reliable, and recommend them. (EasyList is currently an ABP default.) Since these are just URL-pattern-matching blocklists, subscriptions are not as security-sensitive as are Firefox extensions themselves, but you should still be selective about which ones to adopt.
CustomizeGoogle: This extension largely defangs Google search engine lookup of its major advertising and data-mining features, makes your Google preferences persistent for a change, adds links to optionally check alternative search engines' results on the same queries, anonymises the Google userid string sent when you perform a Google Web search (greatly reducing the ability of Google's data mining to link up what subjects you search for with who you are), etc. Be aware that you'll want to go through CustomizeGoogle's preferences carefully, as most of its improvements are disabled by default. Available from: http://www.customizegoogle.com/
For the record, I like the Google, Inc. company very much, even after its 2007 purchase of notorious spying-on-customers firm DoubleClick, Inc., which served as a gentle reminder that the parent firm's core business, really, intrinsically revolves around data mining/collection and targeted advertising. What I (like, I assume, LG readers) really want is to use its services only at my option, not anyone else's, and to negotiate what I'm giving them, the Mozilla Corporation, and other business partners, rather than having it taken behind my back. For example, Ubuntu's first alpha release of 10.04 "Karmic Koala" included what Jon Corbet at LWN.net called "Ubuntu's multisearch surprise": a custom Firefox search bar that gratuitously sent users to a Google "search partner" page to better (and silently, without disclosure) collect money-making data about what you and I are up to. (This feature was removed following complaints, but the point is that we the users were neither informed nor asked about whether we wanted to be monitored a bit more closely to make this "service" possible.)
User Agent Switcher: This extension doesn't technically concern security and privacy, exactly, but is both useful in itself and as a way to make a statement to Web-publishing companies about standards. It turns out that many sites query your browser about its "User Agent" string, and then decide on the basis of the browser's answer whether to send it a Web page or not — and what Web page to send. User Agent Switcher lets you pick dynamically which of several popular Web browsers you want Firefox to claim to be, or you can write your own. I usually have mine send "W3C standards are important. Stop f---ing obsessing over user-agent already", for reasons my friend Karsten M. Self has cited:
In the finest Alice's Restaurant tradition, if one person does this, they may think he's sick, and they'll deny him the Web page. If two people do it, in harmony, well, they're free speech fairies, and they won't serve them either. If three people do it, three, can you imagine, three people setting their user-agent strings to "Stop f---ing obsessing over user-agent...". They may think it's an organization. And can you imagine fifty people a day? Friends, they may think it's a movement. And that's what it is... If this string shows up in enough Web server logs, the message will be felt.
Available from: http://chrispederick.com/work/user-agent-switcher/
I list a number of other extensions that might be worth considering on my personal pages.
[ I can also recommend the Web Developer toolbar extension. Even if you're not a Web developer, the tool can help you to deactivate obnoxious style sheets and layouts. In addition, you can instantly clear all cookies and HTTP authentications for the site you are viewing (by using the menu item Miscellaneous/Clear Private Data/...). -- René ]
Edit: Preferences: Content: Select Advanced for "Enable JavaScript" and deselect all. Reason: There's no legitimate need for JavaScript to fool with those aspects of your browser. Then uncheck Java, unless you actually ever use Java applets in your Web browser. (You can always re-enable if you ever need it.)
Edit: Preferences: Privacy: Uncheck "Accept third-party cookies." Reason: I've only seen one site where such were essential to the site's functionality, and even then it was clearly also being used for data mining. Enable "Always clear my private data when I close Firefox". Click "Settings" and check all items. Reason: When you ask to delete private data, it should actually happen. Disable "Remember what I enter in forms and the search bar". Reason: Your prior forms data is often security-sensitive. Consider disabling "Keep my history for n days" and "Remember what I've downloaded". Reason: You don't get much benefit from keeping this private data around persistently, so why log it?
Edit: Preferences: Security: Visit "Exceptions" to "Warn me when sites try to install add-ons" and remove all. Reason: You should know. Disable "Tell me if the site I'm visiting is a suspected attack site" and "Tell me if the site I'm visiting is a suspected forgery". Reason: Eliminate periodic visits to an anti-phishing, anti-malware nanny site. Really, can't you tell EBay and your bank from fakes, and can't you deal with malware by just not running it? "Remember passwords for sites": If you leave this enabled, remember that Firefox will leave them in a central data store that is only moderately obscured, and then only if you set a "master password". Don't forget, too, that even the list of sites to "Never Save" passwords for, which isn't obscured at all, can be very revealing. The cautious will disable this feature entirely — or, at minimum, avoid saving passwords for any site that is security-sensitive.
Edit: Preferences: Advanced On General tab, enable "Warn me when Web sites try to redirect or reload the page". Reason: You'll want to know about skulduggery. On Update tab, disable "Automatically check for updates to: Installed Add-ons" and "Automatically check for updates to: Search Engines", and select "When updates to Firefox are found: Ask me what I want to do". Reason: You really want those to happen when and if you choose.
Now we head over to URL "about:config". You'll see the condescending "This might void your warranty!" warning. Select the cutesy "I'll be careful, I promise!" button and uncheck "Show this warning next time". Reason: It's your darned browser config. Hypothetically if you totally screw up, at worst you can close Firefox, delete ~/.mozilla/firefox/ (after saving your bookmarks.html), and try again.
Set "browser.urlbar.matchOnlyTyped = true": This disables the
Firefox 3.x "Awesome Bar" that suggests searches in the Search box based
on what it learns from watching your bookmarks and history, which is
not (in my opinion) all that useful, and leaves information on your
browsing habits lying around.
Set "browser.tabs.tabMinWidth = 60" and "browser.tabs.tabMaxWidth = 60": Reduce tab width by about 40%. Reason: They're too wide.
Set "bidi.support = 0": Reason: Unless you're going to do data input in Arabic, Hebrew, Urdu, or Farsi, you won't need bidirectional support for text areas. Why risk triggering bugs?
Set "browser.ssl_override_behavior = 2" and "browser.xul.error_pages.expert_bad_cert = true": This reverts Firefox's handling of untrusted SSL certificates to the 2.x behaviour. Reason: The untrusted-SSL dialogues in Firefox 3.x are supremely annoying, "Do you want to add an exception?" prompt and all.
Set "network.prefetch-next = false": Disables link prefetching of pages Firefox thinks you might want next. Reason: Saves needless waste of bandwidth and avoids sending out yet more information about your browsing.
Set "xpinstall.enabled = false": Globally prevents Firefox from checking for updates to Firefox and installed extensions. Reason: This really should happen on your schedule, not Firefox's.
Set "permissions.default.image = 3": This control specifies which images (picture elements) to get, where 1 = all regardless of origin (default), 2 = block all, 3 = fetch only from the site you're browsing. Reason: Images from third-party sites are banner ads or Web bugs, 99% of the time. Note that the ability to block third-party images used to be part of regular Mozilla/Firefox preferences, but was banished to "about:config" as part of a general dummying down.
Set "network.dns.disableIPv6 = true": Prevents Firefox from attempting IPv6 lookups. Reason: At the moment, for most people, there's no point to this function, and it wastes network traffic trying IPv6 before falling back to regular IPv4. If the world changes, you can toggle this setting back.
Set "extensions.blocklist.enabled" to disabled: Stops Firefox from repeatedly polling a remote site for a malware blacklist. Reason: Wasted traffic, and usual logic about malware applies.
Set the three "browser.contentHandlers.types.[012].uri" items to blank: Stops Firefox from repeatedly polling Bloglines, My Yahoo, and Google for RSS feeds that you don't necessarily care about at all. Reason: Wasted network traffic.
Set "plugin.default_plugin_disabled = false": This prevents Firefox's libnullplugin.so from popping up annoying dialogues suggesting you go hunting for plugins/extensions every time you encounter a file on the Web with an unfamiliar MIME type. Reason: Stops Firefox's repetitive suggestions (in a yellow bar at the top of the page) that you install yet more plugins/extensions.
Set "geo.enabled" to disabled: This is yet another Google service that they swear up and down is absolutely not a privacy violation, and they have a privacy policy, etc. In this case, it's "location-aware browsing", where, on "location-aware Web sites", Google will estimate your latitude/longitude and provide enhanced services such as lo! there's a pizza restaurant on the next block. Reason: Obvious, I imagine. Disabling that key makes the feature go away entirely.
We've already lightly touched on a favourite tinfoil-hat obsession: browser cookies. Like many other browser features, cookies have a fine legitimate purpose, that of offering a persistent-data store for what's normally a stateless protocol (HTTP), e.g., for session data. Of course, the feature was abused about a millisecond after its invention, but the aforementioned unchecking of "Accept third-party cookies" in my view controls such abuse well enough.
What's often neither understood nor controlled are Flash cookies, which Adobe calls "Local Shared Objects", a hidden datastore, holding up to 100kB per domain, maintained by the local Adobe (ex-Macromedia) Flash interpreter under your ~/.macromedia tree, in files with .sol filename extensions. What data? Anything and everything, but mostly the usual obnoxious per-user tracking, except with 25 times the storage and effectively no scrutiny. Bad? You bet. Researchers have found that companies have taken to using Flash cookies not only to track users but also to re-create, behind the user's back, regular browser cookies he or she has deliberately deleted -- invisibly to browser privacy controls and outside their reach. It should also be noticed that data in Flash cookies are also queryable by any other Flash-enabled application.
The standard recommendation to control Flash cookies (which, of course, are far less of an issue with NoScript and Adblock Plus than without them) is another Firefox extension, BetterPrivacy — but I would like to specifically disrecommend that solution, because BetterPrivacy is proprietary software for which source code is never even available for inspection. Can you imagine going to all the trouble of running an open-source browser on an open-source OS, and then throwing in a "hey, trust me" proprietary binary-only module from someone you don't even know?
A new, genuinely open source alternative is Greg Yardley's Objection, which seems worth looking into. Alternatively, it seems almost as easy to write a dirt-simple weekly cronjob to delete unwanted Flash cookies by filename. (E.g., you might want to keep certain domains' cookies, that seem to hold only innocuous Flash-related settings such as Flash games' settings and some sites' login data, and lop off the rest.)
Adobe Systems, Inc., themselves, offer a third alternative: Visiting a set of Adobe Web pages called Flash Settings Manager lets you view and control Flash Cookies via — guess what — a Flash-based control panel the company provides for that purpose. Use it if you like. Personally, I find the notion of using Adobe's help to control a privacy risk they created to be... unwise, on balance — although viewing its settings was enlightening and worthwhile.
There are plenty of aesthetic improvements one might also make to clean up Firefox's appearance, but those are obviously highly individual, so I'll omit my prejudices in that department. Suffice it to say that delving through all of the Edit: Preferences and the View menu will be well worth your time.
Acknowledgements: All of the above text is original, but many ideas about Firefox configuration were taken from bloggers Uwe Hermann and Wouter Verhelst and several anonymous commentators, to all of whom I'm grateful.
[1] IT columnist David Berlind defined "Web 2.0" as "When the Back button doesn't work".
[2]: Firefox bloat generally is a real concern. Starting around 2006, Jason Halme has shown starkly just how severe the bloat is, by releasing an optimally configured and compiled (but proprietary-licensed) variant called Swiftfox, which is markedly faster in launching and rendering, and also includes protection against buffer overflow attacks.
Probably inspired by Halme's work, developer "SticKK" has released a very similar variant under Firefox's original MPL 1.1 open-source licensing, called Swiftweasel, which is well worth considering instead of vanilla Firefox, and is packaged by common Linux distributions. It's fully compatible with Firefox extensions. (If you're a Mozilla Thunderbird user, "SticKK's" Swiftdove lends the same advantages to that program, too.)
[3]: For example, Debian and Ubuntu both offer maintained packages for Adblock, Adblock Plus, NoScript, and the Web Developer extension mentioned by René Pfeiffer. A package of User Agent Switcher is currently proposed. And even Fedora, not the most lavish of desktop distributions, at least packages NoScript. So, check your distribution-of-choice's package listings.
Linux and BSD users' ability to rely on their distribution package maintainers as gatekeepers against security problems, quality problems, and even against misbehaviour "upstream" (a term used to refer to original authors' source code that is selectively picked up and packaged, often with some tweaks, by Linux distributions) gives them a huge advantage that MS-Windows and MacOS users can only dream of. A decade-plus of experience suggests you're greatly safer when you rely on that gatekeeping function, and go outside that regime to "upstream" sources only with great caution if ever.
"Upstream sources" of what, you might ask? Firefox extensions would be one excellent example. Make no mistake: These are programs, and you need to be on-guard. Browse the listings at Mozilla Organization's https://addons.mozilla.org/ "portal" site skeptically, and you soon notice that the site says nothing about each entry's licensing or source code, and instead rushes you towards the big "Download Now!" button. In fact, many extensions listed turn out, upon more-careful scrutiny, to be proprietary, binary-only software that isn't audited by anyone you would have confidence in and never will be. In any situation where you find yourself casually expected to run code from nobody in particular -- a fair description of unauditable proprietary extensions from people you've never heard of -- your first reaction should be "No. Why on earth would I?" All of the extensions René and I have cited are genuine open source, and from people with established (generally good) reputations, notwithstanding which you should look among your distribution's packages for them first, before resorting to fetching "upstream" code from the authors' sites.
The advantage: The distribution package maintainer should be accepting code from upstream only when it's been checked for quality, made to comply with your Linux distribution's policies, not a buggy beta (not all new code from upstream is necessarily an improvement), read to (with luck) catch any unpleasant surprises, and verified to be signed by the real upstream coder to eliminate the possibility of trojaned (booby-trapped) substitute code inserted by malign parties in place of the author's real code. Plus, you will get subsequent updates semi-automatically in a rational fashion, with your regular package updates, as a harmonised part of your Linux distribution.
Other examples of third-party additions include Web apps enticingly offered as directly downloadable .tar.gz (or zip) archives, all manner of third-party .deb / .rpm packages, alleged screensavers, alleged Internet poker games, alleged video codecs, alleged desktop themes, alleged "birthday cards", alleged ancillary software, etc. You need to be on your guard: You might not be worried about the security of screensaver modules because they're just gloried wallpaper, but suppose one is published on a community site in .deb format (and you're on, say, Ubuntu). You need to install that with your software package installer, using sudo or root authority, right? Oops, bad idea, because that means you'll be running any included scripts with root authority, and how much did you trust the unknown person behind this screensaver? This scenario's already happened, and unwary novices shot themselves in the foot by installing trojaned software -- by trusting an alleged screensaver from nobody in particular who'd listed it on gnome-look.org.
It's important to realise that no security protections can protect a user who defeats his/her system's security by running untrustworthy software from nowhere in particular. If you go out of your way to fetch that metaphorical gun and aim it at your feet, the resulting hole in your pedal extremity is your responsibility. The best the Linux community can do is help train you to know when your danger alarms should be ringing loudly -- and going outside your system's packaged software regime to any source of third-party software is one of the chief signs of danger.
[4] My somewhat sarcastic reference to "rich computing experience" harks back to an encounter Microsoft Corporation had with the technical community: Specifically, Microsoft developer Bob Atkinson noticed in 1997 some critical discussion in RISKS Digest of his "Authenticode" algorithm for ensuring that ActiveX controls in Microsoft Internet Explorer are "safe" on account of being cryptographically signed with (what you hope is) an unrevoked, valid sender key. He reassured RISKS regulars that Microsoft wanted merely to ensure a "rich computing experience", that Microsoft had all the problems covered, and that everything would be fine. His logic and methods were then expertly but politely pureed over a ten-day period; the comments are popcorn-worthy, especially one fine summary by Peter Gutmann of New Zealand.
Talkback: Discuss this article with The Answer Gang
His first computer was his dad's slide rule, followed by visitor access
to a card-walloping IBM mainframe at Stanford (1969). A glutton for
punishment, he then moved on (during high school, 1970s) to early HP
timeshared systems, People's Computer Company's PDP8s, and various
of those they'll-never-fly-Orville microcomputers at the storied
Homebrew Computer Club -- then more Big Blue computing horrors at
college alleviated by bits of primeval BSD during UC Berkeley summer
sessions, and so on. He's thus better qualified than most, to know just
how much better off we are now.
When not playing Silicon Valley dot-com roulette, he enjoys
long-distance bicycling, helping run science fiction conventions, and
concentrating on becoming an uncarved block.
 Rick has run freely-redistributable Unixen since 1992, having been roped
in by first 386BSD, then Linux. Having found that either one
sucked less, he blew
away his last non-Unix box (OS/2 Warp) in 1996. He specialises in clue
acquisition and delivery (documentation & training), system
administration, security, WAN/LAN design and administration, and
support. He helped plan the LINC Expo (which evolved into the first
LinuxWorld Conference and Expo, in San Jose), Windows Refund Day, and
several other rabble-rousing Linux community events in the San Francisco
Bay Area. He's written and edited for IDG/LinuxWorld, SSC, and the
USENIX Association; and spoken at LinuxWorld Conference and Expo and
numerous user groups.
Rick has run freely-redistributable Unixen since 1992, having been roped
in by first 386BSD, then Linux. Having found that either one
sucked less, he blew
away his last non-Unix box (OS/2 Warp) in 1996. He specialises in clue
acquisition and delivery (documentation & training), system
administration, security, WAN/LAN design and administration, and
support. He helped plan the LINC Expo (which evolved into the first
LinuxWorld Conference and Expo, in San Jose), Windows Refund Day, and
several other rabble-rousing Linux community events in the San Francisco
Bay Area. He's written and edited for IDG/LinuxWorld, SSC, and the
USENIX Association; and spoken at LinuxWorld Conference and Expo and
numerous user groups.
By Rick Moen
Here's all you probably want to know about Linux Gazette's copyediting staff — short version: there are a few of us, we disagree on many things, there are good and compelling reasons why we'll never agree, our job is to make your articles as good as possible while doing no harm, and we not only don't mind authors who disagree with our policies but think it's healthy and natural.
The rest of this article details tidbits about our editing that yr. humble author, LG's Proofreading Coordinator, thinks he can make interesting. (Contentious points will get stressed, disproportionately: They're more interesting. Also, be warned that you're not guaranteed to hear anyone's opinion but the author's, but, hey, it's my article.) Note: Please don't think this article aims to change how you write. Our mamas having raised no fools, we don't expect that: this piece just describes how we[1] edit.
There are good reasons why Linux Gazette neither follows your favourite house-style writing manual nor has one of its own. Mainly, it's because we're (1) international, and (2) not anyone's employer. Because we accept pieces from, and publish to, the entire planet, good Australian, Indian, Irish, Zambian, Fijian, Canadian, and Kiribatian English need to be respected as much as are, say, UK and US English. Because we don't fund anyone's daily bread, we wouldn't dream of imposing top-down rulesets like the Chicago Manual of Style's absurdities about "open style" reversing everything else in that book. We wouldn't put up with that sort of arbitrary regimentation for zero money; why would you?
We've read your AP Stylebook, New York Times Manual of Style and Usage, Fowler's, Cambridge Guide, Follett's, and Garner's, and think their foibles are pretty funny (but that the Merriam-Webster guide's free of such inadvertent comedy) — but, more important, that they're a poor tool for our mission: that mission is simply to help you express yourself well and clearly, in your own way of speaking, by making minimal tweaks to your articles so that, with luck, you're pleased with how well you wrote but can't even tell we touched anything.
It might be nice if we could say what copyediting will and will not occur, but that's not how the world works. In the real world, policy doesn't get work done; people do. If the final staffer to touch your article prior to publication abhors the word "utilize", he/she will change it to "use" (and who can blame such a staffer, right?).
As it turns out, the staff are in cheerful ongoing disagreement on many key points. E.g., most of the staff think "website" is a perfectly fine English word, but the Proofreading Coordinator doesn't, and cares more, so he corrects it to "Web site", every time. That's just the way it works: Those who put in time and effort get to have their way (but try to use that power, such as it is, wisely, and to improve, never to annoy).
This article, in fact, basically tells you what corrections are likely to be done to correct articles by people, notably the Proofreading Coordinator, in the absence of a house style — but also acknowledging the truth that outcome depends on who does the work, because of the staff's disagreement on significant points.
Feel very welcome to tell us why our editing is horribly evil and a sign of the impending Apocalypse (not to mention that an English teacher once mugged you and stole your lunch): we don't mind, but don't promise to take your objection seriously, especially if it's one of the Obnoxious Three:
We won't be offended if you send in junk arguments — on the contrary, at least it shows you care about writing (and what would the Internet do without opinions?) — but you might want to avoid wasting your time.
There's a good reason we don't aim at perfect, pure English: it doesn't exist and never has, the language having after all resulted from an unfortunate collision between mediaeval Norman French and lowland German (loosely speaking). Many structures in English remain badly broken, and the ability to speak precisely in it is only thanks to tireless efforts by many countries to bridge or rope off its crevasses. Thus the old joke about a rancher trying to deal with his snake problem: "Dear sirs, I'd like to order two mongooses." (He frowns, crosses that out.) "Dear sirs, I'd like to order two mongeese." (Frowns, crosses out, tries again.) "Dear sirs, I'd like to order a mongoose. While you're at it, please send a second one."
One of the numerous eternal and inescapable flamewars about English revolves around its lack of a generally usable, non-peculiar third-person singular pronoun that isn't gendered. Yes, we know this is a big problem (and part of an even bigger one whereby the language encourages sexist bias), can quote Douglas Hofstadter's "Person Paper on Purity in Language" fluently, and (I think I can speak for the staff, here) agree wholeheartedly with him. The fact remains that using "they" (as is often done, these days) to fill the gap tends to destroy that word's ability to clearly distinguish between singular and plural.[2] Most on the staff think this damage is perfectly OK; the Proofreading Coordinator politely and firmly disagrees (and, e.g., doesn't care whether Chaucer used it, nor Jane Austen or any other number of famous authors). So, don't be surprised if your singular "they" becomes "he or she" (one of many imperfect solutions, but one that is at least grammatical).
[ Ah, but Rick, now you're assuming everyone is either male or female! -- Kat ]
Our copyeditors' most important principle, in that and other areas, is rather like that of medical schools' maxim of "Primum non nocere" ("First, do no harm"). I call our version Rule Zero: "Ignore any rule, rather than doing anything peculiar that will tend to call attention to itself."
Another inescapable flamewar is correction (or not) of quoted text. The stilted alleged quotations festooned around many "News Bytes" columns are a case in point:
"Launchpad accelerates collaboration between open source projects," said Canonical founder and CEO Mark Shuttleworth. "Collaboration is the engine of innovation in free software development, and Launchpad supports one of the key strengths of free software compared with the traditional proprietary development process. Projects that are hosted on Launchpad are immediately connected to every other project hosted there in a way that makes it easy to collaborate on code, translations, bug fixes, and feature design across project boundaries. Rather than hosting individual projects, we host a massive and connected community that collaborates together across many projects. Making Launchpad itself open source gives users the ability to improve the service they use every day."
We of the editorial staff would be thunderstruck, and also dismayed, if Mark Shuttleworth had actually uttered that mouthful of stilted marketing bafflegab (quoted in issue 166). He seems like a pleasant and intelligent fellow, so the smart money's on that prose emerging from someone in Canonical, Ltd.'s corporate PR department (or hired PR agency), working from a generic press release template. More to the immediate point, you should have seen how dreadful these press releases were before we fixed them. But, you ask, "How dare you fix a direct quotation? Isn't it presumptuous to change what someone said?"
You have part of the answer already: in corporate PR, what you say is often not what you say. Accordingly, we have few qualms about fixing some marketing ghostwriter's bad grammar, spelling, and punctuation. As to the rest, if a quoted person ever complains "Hey, Linux Gazette presumed to make me sound literate. The bastards!" we will be looking forward to the novelty and to apologising winningly if insincerely.
Square brackets: Not yours. Sorry, but Linux Gazette generally reserves square brackets for visually indicating comments inserted into (or, better yet, at the bottom of) someone else's article by the editors themselves. If we end up speaking rubbish, we don't want you to take the blame. So, you as an author may not use square brackets (with obvious exceptions such as code where syntax requires it); it would be confusing. If you try, we'll change them to parentheses every single time. (I'm talking to you, Howard.)
Legal clutter need not apply. Yes, you want everyone to put an R-in-circle after your company name Yoyodyne, to render obeisance to your trademark. We know. We don't care. "TM", "R", and all of that stuff gets stripped out. We actually have bothered to learn the law, and know that we have no obligation to replicate your marking of your corporate territory, only to avoid infringing your property rights, which is not the same thing.
Weird lettercase will be ironed out. Over the years, corporate branding has asked people to do some extremely peculiar things with lettercasing of company and product names. We tend to politely say "no". You can write "nVIDIA" or "NVIDIA" all you want, but in our magazine it's Nvidia — and "CorelDRAW!" is Right Out.
There are debatable cases; the world isn't perfect. Novell's preferred lettercase is "openSUSE", which is only slightly peculiar: We'd probably change it to "OpenSUSE" because it's a proper noun, but maybe not.
Physical styling HTML tags ("i", "bold", "underscore", "strike") are almost always inappropriate and will be removed. Appropriate logical styling will be used where appropriate ("em", "strong"...).
Strong-text ("strong") HTML tags are viewed skeptically, often being typographical excess, and may in those cases be amputated.
Tuck punctuation inside a quotation only if it's part of the quotation. Generations of editors have imposed the "'Zounds,' Tom expostulated" convention on authors; we do not, because of the risk of ambiguity it creates in technical English. Consider a sentence ending with a reference to "string." The contents of that text string might be "string" or might be "string."; it's impossible to tell.
Consistency, lack of: Spelling from either side of the Atlantic, sneakers vs. trainers, program vs. programme, parka vs. anorak, quarter note vs. crochet is fine by us. All we ask is that you pick one. If you piece wanders between two otherwise acceptable usage, spelling, or punctuation patterns concerning the same thing, one of them is by definition wrong and will be fixed. We get to pick which one.
Here's a grab-bag of the most-encountered blunders (that we imagine might be interesting):
"spell check": Unless you mean something that checks spells (and J.K. Rowling will be jealous, if you do), you should write "spelling check".
"vice president": This term is correct if you're referring to a president in charge of vice (an enviable career option), but not otherwise. More than likely, the intended term is "vice-president".
"web": Wrong. It's a proper noun, "Web" (unless you're talking about spider extrusions or analogous woven structural meshes, or a type of offset printing machine). Note that "webmaster", "weblog", "webcam", etc. are not proper nouns, so they're lowercase.
"website": Wrong. It's two words, "Web site". (But why, we hear people asking, is "website" an impermissible coinage if "webmaster", "weblog", and "webcam" aren't? Because new words were needed for those concepts. We already had "Web site"; it works just fine. Don't tell us it's too exhausting to include the space character and lean on your shift key: We won't buy that.)
(lack of) serial comma: The "a, b, and c" pattern is preferred over "a, b and c" by many of our editors. It improves clarity, and avoids the accidental perception of b and c being a grouped pair or otherwise having more in common with each other than they do with a.
In case you doubt this, consider the classic example of a sentence that really, really needs the serial comma (quoted by Teresa Nielsen Hayden from a probably apocryphal book dedication): "I'd like to thank my parents, Ayn Rand and God."
"Free Software": Sorry, no. It's just not a proper noun (except when used as part of an actual name such as Free Software Foundation or Free Software Definition), so the correct usage is "free software" as a noun, and "free-software" as a (compound) adjective.
Sure, we know some folks try to draw a distinction between "Free software" (meaning free as in freedom) and "free software" (meaning free as in cost). However, that doesn't work, sorry. Your readers still won't get it.
"Open Source": Sorry, no. It's just not a proper noun (except when used as part of an actual name, such as Open Source Initiative or Open Source Definition), so the correct usage is "open source" as a noun and "open-source" as a (compound) adjective.
"email" vs. "e-mail": The Proofreading Coordinator prefers the spelling "e-mail" over "email", even though many others on our staff consistently feel otherwise: The rationale for the hyphen is that "email" is too easy to misparse as a one-syllable word, and also is in fact identical to a somewhat obscure synonym for "enameled" (taken from the French word for that concept). This is probably a lost cause, but don't be surprised if the word does get hyphenated in your article.
Apostrophes on plurals of acronyms (and initialisms): Don't. It should be 1950s rather than 1950's, 100s rather than 100's, and BASICs rather than BASIC's (for the plural forms). Think of it this way: That apostrophe serves no purpose and creates confusion with the possessive case, so Rule Zero dictates leaving it out. (If you don't, we will.)
Speaking of possessives: The possessive of "emacs" (a singular noun) is "emacs's", not "emacs'". Similarly, the possessive of "Xandros" (a singular noun) is "Xandros's", not "Xandros'". Get it?
We could go on. We shouldn't — and we know all of the above will keep on needing correction. That's OK, really.
The English language is a train-wreck. Don't sweat it. We just aim for it to be a well-swept, orderly train-wreck — solely so that your work as authors gets displayed as well as we can manage.
There's an old joke among copy-editors: "Q: Should the phrase 'anal-retentive' be hyphenated? A: Always when it's used as a compound adjective. Never when it's a compound noun." If you found that amusing, you might just be one of us.
[1]: Some uses of "we" in this piece are covered by the middle fork of Mark Twain's dictum that the "editorial we" is permitted only to kings, editors, and people with the tapeworm.
[2]: Erosion of English speakers' ability to distinguish singular from plural has become unmistakable: For example, not long ago, I heard a radio announcer say "Levitz is having a sale at their Oakland warehouse." Such phrasing makes my head spin, but now passes without comment among the general public.
[ I'm sorry it makes your head spin, Rick, but I suspect your problem lies here: http://en.wikipedia.org/wiki/Collective_noun/ rather than in erosion of any mythical ability. Note especially that this is a major difference in usage between British and American English, as with this example: "In AmE, collective nouns are usually singular in construction: the committee was unable to agree... " (from http://en.wikipedia.org/wiki/American_and_British_English_differences#Formal_and_notional_agreement). -- Kat ]
[ "The Devil", as someone once noted, "is in the details." The general thrust of this article is indeed spot-on; there's much disagreement on editing technique, but it's not a problem, since the edits are serially applied. The individual editors' and proofers' styles, though, can vary quite a lot: e.g., while Rick's focus may be on good grammar, mine is more about clarity and readability of the entire piece. He prefers a light touch, while I don't hesitate to hack'n'slash mercilessly in the service of making an article as comprehensible as possible (and, much like him, I've still yet to hear from an outraged author whose work I've "damaged" with this treatment). We do our best to leave the style of the writing alone, though; the author's voice is indeed an important and valuable part of the whole, and deserves to be heard.
The important point here - the really important point - is that this is how true cooperation works. Rick and I are not competing with each other, nor are we competing against the other editors or proofreaders; we are all fellow contributors, with each adding his or her effort into the common pot. The end result, the work that we produce, benefits not only from our combined effort, but from the synergy that results from intentional cooperative efforts of a group. This, folks, is open source in action. -- Ben ]
[ Ben, I can't help mentioning that you almost certainly mean "differ", when you say that "editors' and proofers' styles can very quite a lot." If something varies, that means it, itself, is undergoing change over time. If it differs, that merely means it is unlike something else. Your average jockey and basketball players' heights differ. Each of them has a height that varies only over, say, his or her teenage years.
Did I ever mention that copyeditors are incurable wiseasses? -- Rick ]
[ Rick, I can't help mentioning that you almost certainly mean "vary quite a lot" when you (mis)quote me in your wisecrack. From The Jargon File: "It's an amusing comment on human nature that spelling flames themselves often contain spelling errors."
As for your grammar correction, I can't help mentioning (well, I could, but it wouldn't be any fun) that you've tripped over your own shoelaces. I quote Webster's Dictionary: "2. To differ, or be different; to be unlike or diverse; as, the laws of France vary from those of England." No time component stated or required; in fact, none of the meanings cited by Webster or WordNet require one.
Oh, and - you also messed up the article formatting in your snark - now fixed. You're welcome. :) -- Ben ]
Talkback: Discuss this article with The Answer Gang
His first computer was his dad's slide rule, followed by visitor access
to a card-walloping IBM mainframe at Stanford (1969). A glutton for
punishment, he then moved on (during high school, 1970s) to early HP
timeshared systems, People's Computer Company's PDP8s, and various
of those they'll-never-fly-Orville microcomputers at the storied
Homebrew Computer Club -- then more Big Blue computing horrors at
college alleviated by bits of primeval BSD during UC Berkeley summer
sessions, and so on. He's thus better qualified than most, to know just
how much better off we are now.
When not playing Silicon Valley dot-com roulette, he enjoys
long-distance bicycling, helping run science fiction conventions, and
concentrating on becoming an uncarved block.
Rick has run freely-redistributable Unixen since 1992, having been roped
in by first 386BSD, then Linux. Having found that either one
sucked less, he blew
away his last non-Unix box (OS/2 Warp) in 1996. He specialises in clue
acquisition and delivery (documentation & training), system
administration, security, WAN/LAN design and administration, and
support. He helped plan the LINC Expo (which evolved into the first
LinuxWorld Conference and Expo, in San Jose), Windows Refund Day, and
several other rabble-rousing Linux community events in the San Francisco
Bay Area. He's written and edited for IDG/LinuxWorld, SSC, and the
USENIX Association; and spoken at LinuxWorld Conference and Expo and
numerous user groups.
Beginning in Spring 2009, I started seeing network problems at some customer sites: data transmissions would hang and time out; connections via OpenVPN links would work at first but time out as soon as more data was transmitted; VPN connections using UDP would not work at all (but would work magically when changing OpenVPN's port to 80/TCP). All these symptoms are usually tied to traffic shaping, problems with the maximum packet size (maximum transfer unit, MTU) or other issues usually found between the end-points of the transmission. But how do you test and record the performance of "your" Internet?
First of all, you can use network tools to inspect the path between the two communication partners.
Most tools display error messages, round-trip/response times and other useful information. Although many people rely on the results of tools, always keep in mind that sending test packets is not the same as sending real data over different protocols. There are routers and other network devices out there that do not treat every packet equally.
One site reported very strange effects. Immediately after you used a Bittorrent client or a protocol over "bad ports", the bandwidth for "regular" network traffic dropped notably. After half an hour or more, the performance would return to normal. This behaviour may indicate a violation of net neutrality, the presence of filters, or other defects. The big problem is to find the cause, since it could be the network path, flaky hardware, broken software, prioritisation of network traffic, policy enforcement, or some entirely different reason. If there are intermediate network devices manipulating your packet flow, then there's a chance you will never identify or "see" these devices with the tools available.
Using "real" data and "real" protocols for testing is better, but how do you do that? Clicking on download links in your Web browser and using a stop watch isn't well suited to finding hard facts. What about the other direction? Downloads are treated differently from uploads, if you're on an asymmetric Internet connection. You need to test transfers in both directions, and you need to use different protocols and ports. Why not let a script do all of this, and collect a nice summary?
First, we thought to use a shell script containing a few tools, and send data around. The problem is that you might want to do some statistics. Filtering the output and calculating transmission rates can be quite difficult. That's why a Perl script was created. It uses HTTP, HTTPS, SCP, FTP, SMTP, and IMAP. All protocols except SMTP are automatically used bidirectionally. The script uses a configuration file where login, password, paths, and other parameters can be configured. You can use different servers for every protocol, if you want. The data to be transferred can be given explicitly by file. If no file is given, then the script will create a given amount of random data using OpenSSL's pseudo-random generator code. The full configuration file with all entries looks like this:
# Size of data - you can either provide a file or a number of bytes. # If the file is set to "none", the number of random bytes is used. data_bytes=65536 data_chunk=8192 data_file="none" logfile="result.log" tests=3 # Send report by email email="[email protected]" cc="none" smtp_relay="localhost" # HTTP URLs http_download="http://www.example.net/tmp/crypto_schrift.png" http_upload="http://www.example.net/internettester.php" # HTTPS URLs https_download="https://www.example.net/tmp/crypto_schrift.png" https_upload="https://www.example.net/internettester.php" # FTP ftp_server="ftp.example.net" ftp_username="ftpuser" ftp_password="password" ftp_path="none" # IMAP connection (we use the INBOX) imap_server="mail.example.net" imap_port="143" imap_messages=5 imap_username="mailuser" imap_password="password" imap_ssl="no" # SCP connection scp_server="www.example.net" scp_port=22 scp_path="/tmp" scp_username="user" # SMTP smtp_server="mail.example.net" smtp_port=25 smtp_subject="This is a automatically generated email from internettester.pl (%u)" smtp_from="[email protected]" smtp_to="[email protected]" # SSL parameters ssl_ca="" ssl_cert="" ssl_key="" # Temporary directory tmpdir="/tmp"
It is important that the HTTP and HTTPS upload URLs handle POST requests. One way of doing this is to place the PHP script internettester.php on a Web server. The script receives the POST requests, checks the parameters, and discards the upload data. If you need to use SSL with certificates, then you can add the path to a certificate, key, and certificate authority to the configuration, too. (See the section "SSL parameters".)
The results are printed on standard output. If you want the results by e-mail, then you can set the parameters email, cc, and smtp_relay. The output is then put into an e-mail message and sent via SMTP.
In order to do the actual measurements, you will need at least one endpoint with an Internet connection with known parameters. You can use a place on a co-located server, but bear in mind that the connectivity will most probably be shared. 100 Mbit/s or more sounds a lot - if you have well-behaving neighbours. The bandwidth should at least be higher than the one at the endpoint you are interested in testing.
The script itself needs only Perl and a couple of modules for all the protocols used. You can check if you have all modules by using perl -cw internettester.pl on the command line. On Debian or Ubuntu systems, the packages of the Perl modules start with lib and end with -perl. So the module Crypt::OpenSSL::Random translates to the package libcrypt-openssl-random-perl.
Running the script is fairly straightforward. It takes only two optional parameters. By using --config, you can direct the script to use a configuration file. By default, it uses internettester.cfg. The other parameter sets the debug mode. It lets you see what the script does.
lynx@nightfall:~$ ./internettester.pl --config lg.cfg +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ + Test run - using configuration file lg.cfg - + Sun Dec 13 03:35:01 CET 2009 + + Test file has a size of 3284992 bytes. + +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ --- HTTP download --------------------------------------------------------- Number of tests : 5 Mean : 227.16 KiB/s Minimum : 221.96 KiB/s Maximum : 231.75 KiB/s Standard deviation : 4.66 KiB/s --- HTTP upload ----------------------------------------------------------- Number of tests : 5 Mean : 1195.61 KiB/s Minimum : 1171.40 KiB/s Maximum : 1208.61 KiB/s Standard deviation : 14.47 KiB/s --- HTTPS download -------------------------------------------------------- Number of tests : 5 Mean : 227.64 KiB/s Minimum : 222.47 KiB/s Maximum : 233.43 KiB/s Standard deviation : 4.13 KiB/s --- HTTPS upload ---------------------------------------------------------- Number of tests : 5 Mean : 1054.77 KiB/s Minimum : 978.15 KiB/s Maximum : 1138.29 KiB/s Standard deviation : 64.00 KiB/s [...] lynx@nightfall:~$
I cut the output after the first two protocols. The script measures only bandwidth. Packet loss and round-trip time are not recorded. You can see the mean, maximum, and minimum of the measured rates. They are computed with the help of the Statistics::Descriptive module. The fourth value is the standard deviation. It indicates how far away the measurements are away from the mean. Low values of standard deviation indicate low variations of the individual transfer rate. Make sure the number of tests is not too low for a statistical analysis.
A word of warning: The tests will probably saturate your Internet link. All tests use TCP, which will tend to grab all your bandwidth (on a "standard" link). Measurements during office hours should be coordinated.
The script is no magic bullet, and won't detect all of your network problems, but can perform automated tests and record the bandwidth used. Feel free to adapt the code to your requirements.
Talkback: Discuss this article with The Answer Gang

René was born in the year of Atari's founding and the release of the game Pong. Since his early youth he started taking things apart to see how they work. He couldn't even pass construction sites without looking for electrical wires that might seem interesting. The interest in computing began when his grandfather bought him a 4-bit microcontroller with 256 byte RAM and a 4096 byte operating system, forcing him to learn assembler before any other language.
After finishing school he went to university in order to study physics. He then collected experiences with a C64, a C128, two Amigas, DEC's Ultrix, OpenVMS and finally GNU/Linux on a PC in 1997. He is using Linux since this day and still likes to take things apart und put them together again. Freedom of tinkering brought him close to the Free Software movement, where he puts some effort into the right to understand how things work. He is also involved with civil liberty groups focusing on digital rights.
Since 1999 he is offering his skills as a freelancer. His main activities include system/network administration, scripting and consulting. In 2001 he started to give lectures on computer security at the Technikum Wien. Apart from staring into computer monitors, inspecting hardware and talking to network equipment he is fond of scuba diving, writing, or photographing with his digital camera. He would like to have a go at storytelling and roleplaying again as soon as he finds some more spare time on his backup devices.
By Anderson Silva and Steve 'Ashcrow' Milner
Synergy is an open source project that allows you to share a keyboard and a mouse among several different computers, each connected to some sort of monitor, without any extra hardware (e.g., KVM switches). Synergy runs over the network, and can be used with several different operating systems.
Synergy runs as a client/server application, where the server is the computer that will have the keyboard and mouse attached to it, and all others will connect as clients. Switching from one display to another is only a matter of moving the mouse to the edge of the screen, and Synergy will detect the mouse pointer leaving one screen and entering another.
If you use a Debian-based distribution, you should be able to run:
sudo -c apt-get install synergy
While on an RPM-based distribution, you can install by running:
As root:
yum install synergy
Create a config file called synergy.conf. (You may place it in /etc or in ~/.synergy.conf.) Below is a basic example of the synergy.conf file that configures a client workstation to the right of the server. Notice that, under the options section, we have turned on screensaver synchronization.
section: options screenSaverSync = true end section: screens server.hostname: client.hostname: end section: links server.hostname: right = client.hostname client.hostname: left = server.hostname end
The screens section defines what screens are available. In the links section, the screens are set up relative to each other.
You can find more detailed configuration options at Synergy's configuration file format page.
As your regular (non-root) user, start the server:
synergys --config /etc/synergy.conf
The Synergy web site also has a dedicated session for auto-starting the Synergy server on different platforms.
synergyc -f server.hostname
If the connection is successful, you will see the message below, as part of the output from the connections:
NOTE: synergyc.cpp,247: connected to server
If the connection fails, the client will keep trying to re-connect a few
more times, but we recommend you look at
Synergy's troubleshooting
page. Once you have successfully connected the client and the
server, you can remove the -f option
from the synergyc command, and it will run as a background process on
your computer.
As with any good server-client application, it is important to remember that you may need to configure your firewall to allow the connections between synergys and synergyc to be established. Synergy runs on port 24800 by default, but by using the -a option, you can customize the server to listen on a different socket.
Note that, if you will be using Synergy over a network that is shared with other users, you may want to look into wrapping your usage with stunnel or SSH.
Since 2006, there haven't been any updates to Synergy. Since then, a 'maintenance fork' has been created and called Synergy+ (synergy-plus). The new project has posted a list of fixes its developers have implemented so far, and issues they want to fix or implement in future releases, including the implementation of secure connections between client and server.
To make life even easier, two developers from Brazil, César L. B. Silveira and Otávio C. Cordeiro, have developed a GUI for configuring Synergy. Quicksynergy is available in several Linux distributions, and is also available under Mac OS X (Leopard).
With Synergy set up and installed, you no longer have to envy coworkers with multi-monitor setups, and you will be able to breathe new life into your old computers and displays.
Anderson and Steve would like to thank Brenton Leanhardt for catching a couple of bugs in this article. Thanks, man!
For more information visit http://synergy2.sourceforge.net/.
The original article was published on October 18th, 2007 by Red Hat Magazine, and has been revised for the February 2010 issue of Linux Gazette.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/silva.jpg)
Anderson Silva works as an IT Release Engineer at Red Hat, Inc. He holds a BS in Computer Science from Liberty University, a MS in Information Systems from the University of Maine. He is a Red Hat Certified Engineer working towards becoming a Red Hat Certified Architect and has authored several Linux based articles for publications like: Linux Gazette, Revista do Linux, and Red Hat Magazine. Anderson has been married to his High School sweetheart, Joanna (who helps him edit his articles before submission), for 11 years, and has 3 kids. When he is not working or writing, he enjoys photography, spending time with his family, road cycling, watching Formula 1 and Indycar races, and taking his boys karting,
![[BIO]](../gx/2002/note.png)
Steve 'Ashcrow' Milner works as a Security Analyst at Red Hat, Inc. He is a Red Hat Certified Engineer and is certified on ITIL Foundations. Steve has two dogs, Anubis and Emma-Lee who guard his house. In his spare time Steve enjoys robot watching, writing open code, caffeine, climbing downed trees and reading comic books.
These images are scaled down to minimize horizontal scrolling.
Flash problems?All HelpDex cartoons are at Shane's web site, www.shanecollinge.com.
Talkback: Discuss this article with The Answer Gang
Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
More XKCD cartoons can be found here.
Talkback: Discuss this article with The Answer Gang
I'm just this guy, you know? I'm a CNU graduate with a degree in physics. Before starting xkcd, I worked on robots at NASA's Langley Research Center in Virginia. As of June 2007 I live in Massachusetts. In my spare time I climb things, open strange doors, and go to goth clubs dressed as a frat guy so I can stand around and look terribly uncomfortable. At frat parties I do the same thing, but the other way around.
These images are scaled down to minimize horizontal scrolling.
All "Doomed to Obscurity" cartoons are at Pete Trbovich's site, http://penguinpetes.com/Doomed_to_Obscurity/.
Talkback: Discuss this article with The Answer Gang
Born September 22, 1969, in Gardena, California, "Penguin" Pete Trbovich today resides in Iowa with his wife and children. Having worked various jobs in engineering-related fields, he has since "retired" from corporate life to start his second career. Currently he works as a freelance writer, graphics artist, and coder over the Internet. He describes this work as, "I sit at home and type, and checks mysteriously arrive in the mail."
He discovered Linux in 1998 - his first distro was Red Hat 5.0 - and has had very little time for other operating systems since. Starting out with his freelance business, he toyed with other blogs and websites until finally getting his own domain penguinpetes.com started in March of 2006, with a blog whose first post stated his motto: "If it isn't fun for me to write, it won't be fun to read."
The webcomic Doomed to Obscurity was launched New Year's Day, 2009, as a "New Year's surprise". He has since rigorously stuck to a posting schedule of "every odd-numbered calendar day", which allows him to keep a steady pace without tiring. The tagline for the webcomic states that it "gives the geek culture just what it deserves." But is it skewering everybody but the geek culture, or lampooning geek culture itself, or doing both by turns?
By Kat Tanaka Okopnik and Ben Okopnik
The following is a sampling of the responses we got to our recent Backpage. Thank you all! I've read
every one of these with interest, and am considering how to integrate the
best of your ideas and suggestions in order to make LG better.
-- Ben Okopnik, Editor-in-Chief
I see linuxquestions.org is quite busy and I have found it a good place to look for ideas on related problems to mine. Similarly Google, with the right choice and order of keywords works wonders these days. I still find that I have a big need (when I try to get around to it) for well written howtos on things like setting up a simple home DNS, sendmail, IP traffic accounting per day per machine, mumble, etc. (Read: A five easy step wizard type thing for my distribution is required). Things like IPtables and sendmail configuration files, .m4 are still daunting to me. Real scary stuff. The moment I sit down, starting to read up on it, someone in the house would like to do this or that and would just like to ask...
What I would not mind is a monthly email reminder on the latest linuxgazette issue. (The LQ email is not too much spam for me.) Whenever I have come across your magazine, I never have been disappointed with the read and always tried to make a mental note to come back to it, but just like the commercial magazines sites just lay there as a possible reference for new information. (Yes, I am not a frequent reader.) I would like to know which howtos are newly updated and worth a read and which are too outdated (for the current releases of which distributions) How about more cross links to and from new and updated articles in previous and current issues - like LQ's list at the bottom of the page. I would like to know more about the kernel development (in a nutshell) that I can understand. What info is just as well documented on wikipedia? To what extend would articles already published elsewhere (commercially) be allowed to be published here later (on LG.net)?
Anonymous
[ We send out a monthly reminder e-mail, with the article titles and summaries, via the lg-announce mailing list; we also notify the world via a note on Facebook and Twitter (thanks to Anderson Silva). Meanwhile, funny you should mention - Rick Moen just wrote a series on DNS in issue 170. As far as links to and from old issues, our Knowledge Base has lots of links to our previous articles. Do be aware, however, that many articles drift out of scope after a while; Linux tends to grow by leaps and bounds, so relevant information changes over time.
As to republishing articles, that depends on how restrictive the original publication license was (essentially, how much of their rights to the work the author has signed away or retained.) Assuming that we can re-release it under the OPL, and the subject matter is relevant to LG's mission, I'll be happy to take a look at it. ]
I saw your Back Page letter in the December issue, asking to hear the voices of your readers. As a long-time silent reader of the Linux Gazette, I guess I am overdue in letting you know why I find the Gazette a valuable resource.
Although I could probably ramble on for quite a while, I'll limit myself to the following four reasons why I hope that the Gazette lives for years to come.
In earlier times, sites with original content were not hard to find on the Internet. A search engine might direct you to dozens of sites run by people or organizations that were actively involved, or at least well-versed, in the subject you were seeking information about. Often times these sites existed because the people that created them had a passion for the subject, wanted to share their knowledge of it, and took pride in doing so.
These days, instead of dozens of sites, a search engine might direct you to hundreds or thousands of sites. Unfortunately, most of these sites will contain information simply copied from other sites -- often sites that have already copied it from somewhere else.
The people behind such sites do not have a passion for your subject of interest, and they take no pride in presenting accurate information. These sites exist in hopes of generating advertising revenue.
The Linux Gazette, on the other hand, has roots that go back to the days when the desire to share helpful information was often the main inspiration for creating a web site. And the folks behind the Gazette have continued the tradition to the present.
When I am looking for Linux-related information, "site:linuxgazette.net" are often the first words I type into the search engine. Often I will find just what I need. And when I don't find what I need, I will soon know that; I won't have had to wade through a lot of crap before coming up empty-handed.
I don't go to my web browser because I want to look at the latest artistic creation of some overpaid web designer. I want information. And I don't want to see the latest state-of-the-art methods of distracting me from getting to and reading the information.
The Linux Gazette is mostly just good ol' HTML. (Well, these days I guess it is actually XHTML, but isn't that mostly good ol' HTML?) And that is all that it needs to be. And that means that anyone can actually read it with any browser, with no need to update to this week's version, or reading and agreeing to a long license agreement for and downloading some proprietary "helper".
While things like javascript and flash certainly have their place in the world, when they are used for content which could easily be presented with HTML they are an unnecessary complication. And I appreciate it when web sites are designed without unnecessary complications.
To say that the Gazette focuses on substance over style, certainly does not mean that it lacks style. I find the elegantly simple style to be a welcome change from the overly-busy pages that seem to predominate on the Web today.
Let's see, you go to linuxgazette.net and are presented with a list of issues. Clicking on an issue brings you the table of contents for that issue. Clicking on an article name brings you to the article. What could be more straight-forward than that? And if you are looking for something other than the content of the magazine, there is a clearly-labeled navigation bar at the top of the page.
By contrast the current fashion seems to be to provide multiple lists of links -- on the left side, on the right side, in the middle, at the top, at the bottom, wherever links can be placed to allow you to go directly to almost any other page on the web site and half a dozen other web sites as well. Never mind that I came to the page for some specific content (perhaps one of those many lists) and don't want to spend time looking around the page to see where it is hiding.
Give me a nice hierarchical layout like LG uses any day.
Centuries ago, newspapers realized that text was easier on the eyes if the lines were not too long. Because the Gazette minimizes its formatting, I can (as I prefer) use a small window for my browser and the text, being HTML, will be adjusted into lines that are a length which is easy to read.
By contrast, many sites these days override this wonderful feature of HTML, and force me to read lines of a length that have been hard-coded by their web site designers. And these designers have not had a good conversation with newspaper publishers, so I am forced to read long lines in a wide window or do a heck of a lot of horizontal scrolling.
Anyway, I'm not just saying that I appreciate the style of the Gazette. I'm also saying that I appreciate the fact that you spend time on the content that might otherwise be wasted designing a complicated style (and probably redesigning it every year when you got tired of it).
I know that early in every month I can go to linuxgazette.net and find new content. I also know that if I am busy and don't visit until late in the month (as was the case this month), the new content will still be there waiting for me -- I don't have to keep checking frequently to ensure that I don't miss something.
Many web sites that host Linux information seem to be forever in a state of flux. Sometimes that is because they are for ever being redesigned ("what are we paying our web designer for if the web site never gets redesigned?"), and sometimes it is in the nature of the the design to be forever changing: new information replaces the old; old information vanishes or goes into hiding.
With the Linux Gazette, I know that if I find a useful article today, it will still be available tomorrow, next week, and next month. Even next year it will still be available in the archive. And -- except on the rare need to correct some gross error -- the article will not have changed from the time I first read it. I won't have the aggravation of trying to track down something that no longer exists. (Much as I like Wikipedia -- at least for its links to _real_ sources -- its dynamic nature can leave one wondering about one's rate of advancing senility when revisiting a page read in the past.) The Gazette has a solid feel to it -- not quite as solid as a stack of paper magazines sitting on a shelf, but much better than the vast majority of what is found on the Web these days.
People, organizations, and corporations can mix varying amounts of fiction into the factual content of their web sites. In many, perhaps most, cases the authors do not even realize it is fiction.
While the Linux Gazette is certainly not totally immune to this, I believe it has far less of a problem in this department than many other sources.
Firstly, as touched on in item 1, above, when people take pride in what they write (which I believe is a main reason that LG authors write -- they certainly aren't doing it for the money), they are more likely to spend time getting their facts straight.
Secondly, LG articles are read by someone other than the author before publication. And while the editors may not yet have achieved infinite knowledge, there is more of a chance of misinformation being caught at this stage.
Thirdly, LG has an auto-immune system known as Talkback. When mistakes are made, there is a good chance that someone will spot it and point it out, as readers are encouraged to do by the availability of the Talkback link. Sometimes, even when no mistake has been made, this encourages a reader to clarify something, or add additional information that was not in the original article.
(The advantages of multiple people reviewing the content, be it before or after publication, extends to the area of LG beyond the articles, such as The Answer Gang and Two-cent Tips. Hearing multiple voices adds to the confidence level the reader has in the information (except, of course, in those rare times when nobody can agree on anything).)
Okay, so there is one man's view of some reasons why the Linux Gazette has certainly not "outlived its usefulness to the community".
If the Gazette ceased to publish new issues, the archives could still exist. However it would be a shame to let the archives get moldy with no fresh input. In a short time they would be of more interest to historians than people looking for current information.
I hope that many other readers will share their thoughts with you, and let you know that the work that you and everyone who contributes to the Gazette is certainly not for naught, and is well appreciated.
Yours truly,
and thanks,
Norm Pierce
[ Norm, thank you for your detailed and thoughtful input! It's nice to know that our various editorial choices are appreciated. That is indeed why we have a serial presentation, and a relatively simple layout. I like your description of Talkback as "an auto-immune system" - it's become one of my favorite features. ]
Hallo, I've just finished reading your Back Page in the last issue of LG. It made me feel like I just _had to_ jump to Thunderbird and write you an e-mail!
Your article is really inspiring and makes one really want to think about one of the thousands ideas that come to mind during a week of work with Linux and write about it...
I have wanted to do it some times. I also know myself enough to be sure that when I'll calm down, a few minutes from now, I'm likely to forget about all this and never write anything.
BUT.
I'll bookmark this article and put it at the top in my list, so next time an idea comes to me I'll remember I'll _have_ to at least try and write about it. And send it to LG!
And by the way, I've been and LG reader for some months now and I've never said thank you for your work. I do it now.
Marcello Romani
I finally had time to catch up on LG and the Back Page #169 requested a little feedback.
Consider this it.
Who am I (And where have I heard that before?)? I'm a retired Industrial Electronic Tech, one of those twigits with dirt under the fingernails. We were stuck with that M$ creature at work, but at home, I ran Linux. I currently have 5 boxes networked at the house and all but one are Linux - PCLinuxOS 2009, to be exact. The one Windows machine is my wife's HP laptop (Vista) that is dedicated to her embroidery machine, which can dual boot to SimplyMepis.
I've been distro hopping since the around 1995. Geez, I was on the Internet when it was all text and you had to go thru a bulletin board that had Internet access. Then you had to know a few Unix commands to find your way to a server and log in. Remember when the search engines were named, 'Gopher', 'Archie', 'Veronica' and the like? My God! I think I'm old... I started with FreeBSD way back when, then Debian and the whole schemer. My favorite was the Debian based Kanotix. But when it went under the bus, I didn't care for the replacements: Sidux and the re-dazzled Kanotix, which seemed pretty much a step-child.
When I hit PCLos, I found what I was looking for. A tool that just works, like a good table saw or a solid lathe. The reason the wife's laptop has Mepis is it was the first distro that would configure that machine's Broadcom 43xx wireless chip out of the box.
I'm also a Ham Radio operator - AI4KH - and refuse to use MS for anything Ham related. Although, DXLab's suite, is my favorite, I've given it up rather than go thru the pain of opening and, especially, closing any MS operating system. I get by with the Linux apps for digital operation and logging,
If I was a programmer like my daughter, I'd be helping with some of the Linux apps. Alas, I'm also a woodworker, shooter, and Scottish Country Dancer besides being active in US Submarine Veterans (USSVI). I retired from the Navy in '74, so I'm not a kid anymore.
Yes, I do touch base with LG when I have a chance, just too see what's going on. There is just sooo much stuff out there, it's nice to know I can still count on LG for honesty.
I hope this wasn't too long-winded for you. I tend to run on at the keyboard.
Thanks,
Ron Gemmell
Canton, GA
[ Great to hear from you, Ron! In fact, it would be nice to find out who some of our other readers are: Who are you? Where are you? How did you start reading Linux Gazette? How did you get started with Linux? What distro are you using now? What are some of your favorite things about using Linux? Click on the Talkback link below and let us know, please. ]
Talkback: Discuss this article with The Answer Gang

Kat likes to tell people she's one of the youngest people to have learned to program using punchcards on a mainframe (back in '83); but the truth is that since then, despite many hours in front of various computer screens, she's a computer user rather than a computer programmer.
Her transition away from other OSes started with the design of a massively multilingual wedding invitation.
When away from the keyboard, her hands have been found wielding of knitting needles, various pens, henna, red-hot welding tools, upholsterer's shears, and a pneumatic scaler. More often these days, she's occupied with managing her latest project.

Ben is the Editor-in-Chief for Linux Gazette and a member of The Answer Gang.
Ben was born in Moscow, Russia in 1962. He became interested in electricity at the tender age of six, promptly demonstrated it by sticking a fork into a socket and starting a fire, and has been falling down technological mineshafts ever since. He has been working with computers since the Elder Days, when they had to be built by soldering parts onto printed circuit boards and programs had to fit into 4k of memory (the recurring nightmares have almost faded, actually.)
His subsequent experiences include creating software in more than two dozen languages, network and database maintenance during the approach of a hurricane, writing articles for publications ranging from sailing magazines to technological journals, and teaching on a variety of topics ranging from Soviet weaponry and IBM hardware repair to Solaris and Linux administration, engineering, and programming. He also has the distinction of setting up the first Linux-based public access network in St. Georges, Bermuda as well as one of the first large-scale Linux-based mail servers in St. Thomas, USVI.
After a seven-year Atlantic/Caribbean cruise under sail and passages up and down the East coast of the US, he is currently anchored in northern Florida. His consulting business presents him with a variety of challenges such as teaching professional advancement courses for Sun Microsystems and providing Open Source solutions for local companies.
His current set of hobbies includes flying, yoga, martial arts,
motorcycles, writing, Roman history, and mangling playing
with his Ubuntu-based home network, in which he is ably assisted by his wife, son and daughter; his Palm Pilot is
crammed full of alarms, many of which contain exclamation points.
He has been working with Linux since 1997, and credits it with his complete loss of interest in waging nuclear warfare on parts of the Pacific Northwest.

![[cartoon]](misc/xkcd/admin_mourning.png "And every day it gets harder to fight the urge to su to the user and freak people out.")



