
Tunnel Tales 1
Justin
I met Justin when I was contracting to one of the world's biggest computer companies, OOTWBCC, building Solaris servers for one of Australia's biggest companies (OOABC). Justin is in EBR (Enterprise Backup and Recovery). (OOTWBCC is almost certainly the world's most prolific acronym generator (TWMPAG).) I was writing scripts to automate much of the install of EBR.
To do a good job of developing automation scripts, one needs a test environment. Well, to do a good job of developing just about anything, one needs a test environment. In our case, there was always an imperative to rush the machines we were building out the door and into production (pronounced BAU (Business As Usual) at TWMPAG). Testing on BAU machines was forbidden (fair enough).
Although OOTWBCC is a huge multinational, it seems to be reluctant to invest in hardware for infrastructure. Our test environment consisted of a couple of the client's machines. They were "network orphans", with limited connectivity to other machines.
Ideally, one also wants a separate development environment, especially a repository for source code. Clearly this was asking too much, so Justin and I shrugged and agreed to use one of the test servers as a CVS repository.
The other test machine was constantly being trashed and rebuilt from scratch as part of the test process. Justin started to get justifiably nervous. One day he came to me and said that we needed to back up the CVS repository. "And while we're at it, we should also back up a few other directories."
Had this been one of the typical build servers, it would have had direct access to all of the network, but, as I said before, this one was a network orphan. Diagram 1 indicates the relevant connectivity.
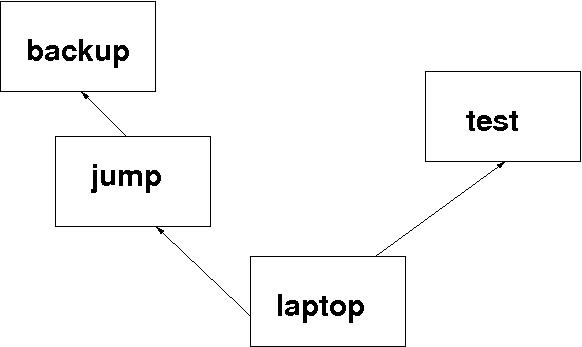
test the test machine and home of the CVS repository laptop my laptop jump an intermediate machine backup the machine which partakes in regular tape backup
If we could get the backup data to the right directory on backup, the corporate EBR system would do the rest.
The typical response I got to my enquiries was, "Just copy the stuff to your laptop, and then to the next machine, and so on." If this were a one-off, I might do that. But what's the point of a single backup? If this activity is not performed at least daily, it will soon be useless. Sure, I could do it manually. Would you?
Step by Step
I'm going to present the solution step by step. Many of you will find some of this just motherhoods[1]. Skip ahead.
My laptop ran Fedora 10 in a VirtualBox under MS Windows XP. All my useful work was done in the Fedora environment.
Two machines
If I want to copy a single file from the test machine to my laptop, then, on the laptop, I would use something like:
scp -p test:/tmp/single.file /path/to/backup_dirThis would create the file /path/to/backup_dir/single.file on my laptop.
To copy a whole directory tree once, I would use:
scp -pr test:/tmp/top_dir /path/to/backup_dirThis would populate the directory /path/to/backup_dir/top_dir.
Issues
-
Why did I say "once"? scp is fine if you want to copy a directory tree once. And it's fine if the directory tree is not large. And it's fine if the directory tree is extremely volatile (ie frequently changes completely (or pretty much)).
But what we have here is a directory tree which simply accumulates incremental changes. I guess over 80% of the tree will be the same from one day to the next. Admittedly, the tree is not large, and the network is pretty quick, but even so, it's nice to do it the right way - if possible.
-
There is another problem, potentially a much bigger problem. The choice of scp or some other program is about efficiency and elegance. This problem can be a potential roadblock: permissions.
The way scp works, I have to log in to test. But I can only directly log in as myself (my user id on test). If I want root privileges I have to use su or sudo. In either case, I'd have to supply another password. I could do it that way, but it requires even stronger magic than I'm using so far (and I think it could be a bit less secure than the solution I plan to present).
-
Have another look at Diagram 1. Notice the arrows? Yes, Virginia, they really are one-way arrows. (The link between jump and backup is probably two-way in real life, but the exercise is more powerful if it's one-way, so let's go with the diagram as it is.)
To get from my laptop to the test machine, I go via an SSH proxy, which I haven't drawn because it would complicate the diagram unnecessarily. A firewall might be set up the same way. In either case, I can establish an SSH session from my laptop to the other machine; but I can't do the reverse. It's like a diode.
I'm going to show you how an SSH tunnel allows access in the other direction. Not only that, but it will make jump directly accessible from test as well!
-
One final point about ssh/scp. If I do nothing special, when I run those scp commands above, I'll get a prompt like:
henry@test's password:
and I will have to enter my password before the copy will take place. That's not very helpful for an automatic process.
Look, ma! No hands!
Whenever I expect to go to a machine more than once or twice, I take the time to set up $HOME/.ssh/authorized_keys on the destination machine. See ssh(1). Instead of using passwords, the SSH client on my laptop
proves that it has access to the private key and the server checks that the corresponding public key is authorized to accept the account. - ssh(1)It all happens "under the covers". I invoke scp, and the files get transferred. That's convenient for me, absolutely essential for a cron job.
Permissions
There's more than one way to skin this cat. I decided to use a cron job on test to copy the required backup data to an intermediate repository. I don't simply copy the directories, I package them with tar, and compress the tarfile with bzip2. I then make myself the owner of the result. (I could have used zip.)
The point of the tar is to preserve the permissions of all the files and directories being backed up. The point of the bzip2 is to make the data to be transferred across the network, and later copied to tape, as small as possible. (Theoretically, some of these commendable goals may be defeated to varying degrees by "smart" technology. For instance, rsync has the ability to compress; and most modern backup hardware performs compression in the tape drive.) The point of the chown is to make the package accessible to a cron job on my laptop running as me (an unprivileged user on test).
Here's the root crontab entry:
0 12 * * * /usr/local/sbin/packitup.sh >/dev/null 2>&1 # BackupAt noon each day, as the root user, run a script called packitup.sh:
#! /bin/sh
# packitup.sh - part of the backup system
# This script collates the data on test in preparation for getting it
# backed up off-machine.
# Run on: test
# from: cron or another script.
BACKUP_PATHS='
/var/cvs_repository
/etc
'
REPO=/var/BACKUPS
USER=henry
date_stamp=`date '+%Y%m%d'`
for dir in $BACKUP_PATHS
do
echo Processing $dir
pdir=`dirname $dir`
tgt=`basename $dir`
cd $pdir
outfile=$REPO/$tgt.$date_stamp.tar.bz2
tar -cf - $tgt | bzip2 > $outfile
chown $USER $outfile
done
exit
If you are struggling with any of what I've written so far, this
article may not be for you. I've really only included much of it for
completeness. Now it starts to get interesting.
rsync
Instead of scp, I'm going to use rsync which invokes ssh to access remote machines. Both scp and rsync rely on SSH technology; this will become relevant when we get to the tunnels.
Basically, rsync(1) is like scp on steroids. If I have a 100MB of data to copy and 90% is the same as before, rsync will copy a wee bit more than 10MB, whereas scp will copy all 100MB. Every time.
Tunnels, finally!
Don't forget, I've already set up certificates on all the remote machines.
To set up a tunnel so that test can access jump directly, I simply need:
ssh -R 9122:jump:22 test
Let's examine this carefully because it is the essence of this article. The command says to establish an SSH connection to test. "While you're at it, I want you to listen on a port numbered 9122 on test. If someone makes a connection to port 9122 on test, connect the call through to port 22 on jump." The result looks like this:
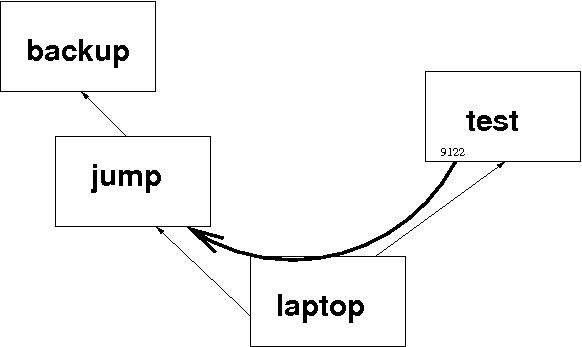
So, immediately after the command in the last box, I'm actually logged in on test. If I now issue the command
henry@test:~$ ssh -p 9122 localhostI'll be logged in on jump. Here's what it all looks like (omitting a lot of uninteresting lines):
henry@laptop:~$ ssh -R 9122:jump:22 test henry@test:~$ ssh -p 9122 localhost Last login: Wed Feb 3 12:41:18 2010 from localhost.localdomain henry@jump:~$
It's worth noting that you don't "own" the tunnel; anyone can use it. And several sessions can use it concurrently. But it only exists while your first ssh command runs. When you exit from test, your tunnel disappears (and all sessions using the tunnel are broken).
Importantly, by default, "the listening socket on the server will be bound to the loopback interface only" - ssh(1). So, by default, a command like the following won't work:
ssh -p 9122 test # usually won't work ssh: connect to address 192.168.0.1 port 9122: Connection refused
Further, look carefully at how I've drawn the tunnel. It's like that for a reason. Although, logically the tunnel seems to be a direct connection between the 2 end machines, test and jump, the physical data path is via laptop. You haven't managed to skip a machine; you've only managed to avoid a manual step. There may be performance implications.
Sometimes I Cheat
The very astute amongst my readers will have noticed that this hasn't solved the original problem. I've only tunneled to jump; the problem was to get the data to backup. I could do it using SSH tunnels, but until next time, you'll have to take my word for it. Or work it out for yourself; it should not be too difficult.
But, as these things sometimes go, in this case, I had a much simpler solution:
henry@laptop:~$ ssh jump henry@jump:~$ sudo bash Password: root@jump:~# mount backup:/backups /backups root@jump:~# exit henry@jump:~$ exit henry@laptop:~$I've NFS-mounted the remote directory /backups on its local namesake. I only need to do this once (unless someone reboots jump). Now, an attempt to write to the directory /backups on jump results in the data being written into the directory /backups on backup.
The Final Pieces
Ok, in your mind, log out of all the remote machines mentioned in Tunnels, finally!. In real life, this is going to run as a cron job.
Here's my (ie user henry's) crontab entry on laptop:
30 12 * * * /usr/local/sbin/invoke_backup_on_test.shAt 12:30 pm each day, as user henry, run a script called invoke_backup_on_test.sh:
#! /bin/sh
# invoke_backup_on_test.sh - invoke the backup
# This script should be run from cron on laptop.
# Since test cannot access the backup network, it cannot get to the
# real "backup" directly. An ssh session from "laptop" to "test"
# provides port forwarding to allow ssl to access the jump machine I
# have nfs-mounted /backups from "backup" onto the jump machine.
# It's messy and complicated, but it works.
ssh -R 9122:jump:22 test /usr/local/sbin/copy2backup.sh
Of course I had previously placed copy2backup.sh on test.
#! /bin/sh
# copy2backup.sh - copy files to be backed up
# This script uses rsync to copy files from /var/BACKUPS to
# /backups on "backup".
# 18 Sep 2009 Henry Grebler Perpetuate (not quite the right word) pruning.
# 21 Aug 2009 Henry Grebler Avoid key problems.
# 6 Aug 2009 Henry Grebler First cut.
#=============================================================================#
# Note. Another script, prune_backups.sh, discards old backup data
# from the repo. Use rsync's delete option to also discard old backup
# data from "backup".
PATH=$PATH:/usr/local/bin
# Danger lowbrow: Do not put tabs in the next line.
RSYNC_RSH="ssh -o 'NoHostAuthenticationForLocalhost yes' \
-o 'UserKnownHostsFile /dev/null' -p 9122"
RSYNC_RSH="`echo $RSYNC_RSH`"
export RSYNC_RSH
rsync -urlptog --delete --rsync-path bin/rsync /var/BACKUPS/ \
localhost:/backups
Really important stuff
Notes on copy2backup.sh.
-
PATH=$PATH:/usr/local/bin
The way that copy2backup.sh is invoked (on test) from cron (on laptop) via invoke_backup_on_test.sh means that you should not count on any but the most basic of items in PATH. Even safer, would be to define even things like /bin. -
RSYNC_RSH=... ... export RSYNC_RSH
These lines provide rsync with with details of the rsh command (in this case, ssh) to run. Depending on which version of ssh your machine has, and the options set in the various SSH config files, your ssh may try to keep track of the certificates of the SSH daemons on the remote machines. Using localhost the way that we do here, the actual machine at the end of the tunnel (and therefore its fingerprint or certificate) may change from one run to the next. ssh will try to protect you from the possibility of certain known forms of attack. These incantations try to get ssh to keep out of the way. It's safe enough on an internal private network; more risky if you are venturing into the badlands of the Internet. - rsync is a pretty powerful program. Its options and arguments can be complicated. I do not propose to cover chapter and verse here. Check the man page, rsync(1). I will just say that the trailing slash in the "from" argument (/var/BACKUPS/) is significant. It says to copy the contents of the specified directory. Omitting the trailing slash would mean to copy the directory. Recursion is specified in an earlier option (-r).
-
--rsync-path bin/rsync
When rsync runs on the local machine (in this case, test), it makes an SSH connection to the remote machine ("localhost" = jump) and tries to run an rsync on the remote machine. This argument indicates where to find the remote rsync. In this case, it will be in the bin subdirectory of my (user henry's) HOME directory on jump. In other words, I'm running a private copy of rsync. - prune_backups.sh and --delete - these two components go together. They can be dangerous. I'll explain later.
Recap
- Everyday at noon packitup.sh on test gathers the data to be backed up into a local holding repository.
- Everyday, half an hour later, if my laptop is turned on, a local script, invoke_backup_on_test.sh is invoked. It simply connects to test, establishing an SSH tunnel as it does, and invokes the script which performs the backup, copy2backup.sh.
- copy2backup.sh does the actual copy over the SSH tunnel using rsync to transport the data.
- When copy2backup.sh completes, it exits, causing the ssh command to exit and the SSH tunnel to be torn down.
- Next day, it all starts over again.
Wrinkles
It's great when you finally get something like this to work. All the pieces fall into place - it's very satisfying.
Of course, you monitor things carefully for the first few days. Then you check less frequently. You start to gloat.
... until a few weeks elapse and you gradually develop a gnawing concern. The data is incrementally increasing in size as more days elapse. At first, that's a good thing. One backup good, two backups better, ... Where does it end? Well, at the moment, it doesn't. Where should it end? Good question. But, congratulations on realising that it probably should end.
When I did, I wrote prune_backups.sh. You can see when this happened by examining the history entries in copy2backup.sh: about 6 weeks after I wrote the first cut. Here it is:
#! /bin/sh
# prune_backups.sh - discard old backups
# 18 Sep 2009 Henry Grebler First cut.
#=============================================================================#
# Motivation
# packitup.sh collates the data on test in preparation for getting
# it backed up off-machine. However, the directory just grows and
# grows. This script discards old backup sets.
#----------------------------------------------------------------------#
REPO=/var/BACKUPS
KEEP_DAYS=28 # Number of days to keep
cd $REPO
find $REPO -type f -mtime +$KEEP_DAYS -exec rm {} \;
Simple, really. Just delete anything that is more than 28 days old. NB
more than rather than equal to. If for
some reason the cron job doesn't run for a day or several, when next
it runs it will catch up. This is called self-correcting.
Here's the crontab entry:
0 10 * * * /usr/local/sbin/prune_backups.sh >/dev/null 2>&1At 10 am each day, as the root user, run a script called prune_backups.sh.
But, wait. That only deletes old files in the repository on test. What about the copy of this data on jump?!
Remember the --delete above? It's an rsync option; a very dangerous one. That's not to say that you shouldn't use it; just use it with extra care.
It tells rsync that if it discovers a file on the destination machine that is not on the source machine, then it should delete the file on the destination machine. This ensures that the local and remote repositories stay truly in sync.
However, if you screw it up by, for instance, telling rsync to copy an empty directory to a remote machine's populated directory, and you specify the --delete option, you'll delete all the remote files and directories. You have been warned: use it with extra care.
Risks and Analysis
There is a risk that port 9122 on test may be in use by another process. That happened to me a few times. Each time, it turned out that I was the culprit! I solved that by being more disciplined (using another port number for interactive work).
You could try to code around the problem, but it's not easy.
ssh -R 9122:localhost:22 fw Warning: remote port forwarding failed for listen port 9122Even though it could not create the tunnel (aka port forwarding), ssh has established the connection. How do you know if port forwarding failed?
More recent versions of ssh have an option which caters for this: ExitOnForwardFailure, see ssh_config(5).
If someone else has created a tunnel to the right machine, it doesn't matter. The script will simply use the tunnel unaware that it is actually someone else's tunnel.
But if the tunnel connects to the wrong machine?
Hey, I don't provide all the answers; I simply mention the risks, maybe make some suggestions. In my case, it was never a serious problem. Occasionally missing a backup is not a disaster. The scripts are all written to be tolerant to the possibility that they may not run every day. When they run, they catch up.
A bigger risk is the dependence on my laptop. I tried to do something about that but without long-term success. I'm no longer there; the laptop I was using will have been recycled.
I try to do the best job possible. I can't always control my environment.
Debugging
Because this setup involves cron jobs invoking scripts which in turn invoke other scripts, this can be a nightmare to get right. (Once it's working, it's not too bad.)
My recommendation: run the pieces by hand.
So start at a cron entry (which usually has output redirected to /dev/null) and invoke it manually (as the relevant user) without redirecting the output.
If necessary, repeat, following the chain of invoked scripts. In other words, for each script, invoke each command manually. It's a bit tiresome, but none of the scripts is very long. Apart from the comment lines, they are all very dense. The best example of density is the ssh command which establishes the tunnel.
Use your mouse to copy and paste for convenience and to avoid introducing transcription errors.
Coming Up
That took much longer than I expected. I'll leave at least one other example for another time.
[1]
A UK/AU expression, approximately "boring stuff you've heard before".
-- Ben
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/grebler.jpg)
Henry was born in Germany in 1946, migrating to Australia in 1950. In his childhood, he taught himself to take apart the family radio and put it back together again - with very few parts left over.
After ignominiously flunking out of Medicine (best result: a sup in Biochemistry - which he flunked), he switched to Computation, the name given to the nascent field which would become Computer Science. His early computer experience includes relics such as punch cards, paper tape and mag tape.
He has spent his days working with computers, mostly for computer manufacturers or software developers. It is his darkest secret that he has been paid to do the sorts of things he would have paid money to be allowed to do. Just don't tell any of his employers.
He has used Linux as his personal home desktop since the family got its first PC in 1996. Back then, when the family shared the one PC, it was a dual-boot Windows/Slackware setup. Now that each member has his/her own computer, Henry somehow survives in a purely Linux world.
He lives in a suburb of Melbourne, Australia.
